实为吾之愚见,望诸君酌之!闻过则喜,与君共勉
第一节 innodb引擎统计信息
mysql会依据innodb表的数据变化阈值来自动收集和计算表的统计信息(innodb_stats_auto_recalc)以供优化器使用,统计信息的收集是先通过获取一部分符合条件的索引页中的leaf page(是leaf page,不是non-leaf page)的数据,然后通过对这些采集的leaf page计算估计出不同值的数量,进而估算出的信息,信息采集的准确度除了和数据本身的构成有关,还与采集page数量有关,数量越多,采集精度越准确,在mysql5.6中引入了Persistent Optimizer Statistics来解决之前的Non-Persistent Optimizer Statistics带来的一些问题,可以使用innodb_stats_persistent_sample_pages/innodb_stats_sample_pages控制采集精度,innodb_stats_sample_pages已经不推荐使用。innodb_stats_persistent_sample_pages参数是全局的,如果想单独指定某个表的采集page数量,可以使用STATS_SAMPLE_PAGES选项,采集信息结果不准确甚至过度不准确会影响执行计划的生成,造成语句的执行出现问题以至于影响数据库的正常运行,这时可能就需要手动指定采集page数量来收集准确的统计信息,矫正执行计划。查看mysql的统计信息(5.6)可以从mysql.innodb_table_stats and mysql.innodb_index_stats以及information_schema.INNODB_SYS_TABLESTATS获取,以下测试多是基于自建mysql进行
第二节 准备数据和对比测试
2.1 建测试表
CREATE TABLE `MOCK_DATA` (
`autoid` int(11) NOT NULL AUTO_INCREMENT,
`id` int(11) DEFAULT NULL,
`first_name` varchar(50) DEFAULT NULL,
`last_name` varchar(50) DEFAULT NULL,
`email` varchar(50) DEFAULT NULL,
`gender` varchar(50) DEFAULT NULL,
`ip_address` varchar(20) DEFAULT NULL,
PRIMARY KEY (`autoid`),
KEY `first_name` (`first_name`),
KEY `id` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=16580327 DEFAULT CHARSET=latin1
其中autoid是clustered index,first_name和id是secondary index,且id是1至1000连续的数字循环插入,
即id列只有1至1000这些数字
2.2 生成测试数据
使用mockaroo临时生成16384000行测试数据:
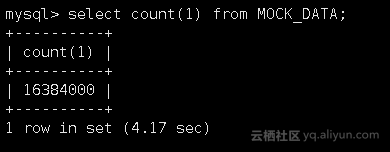
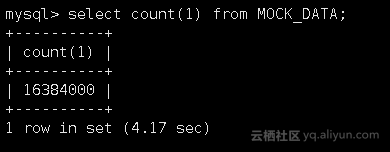
2.3 查询统计信息表
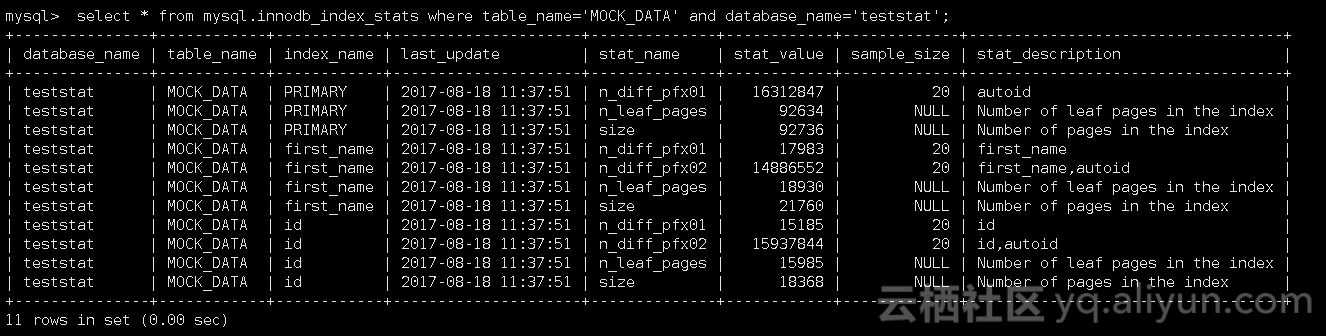
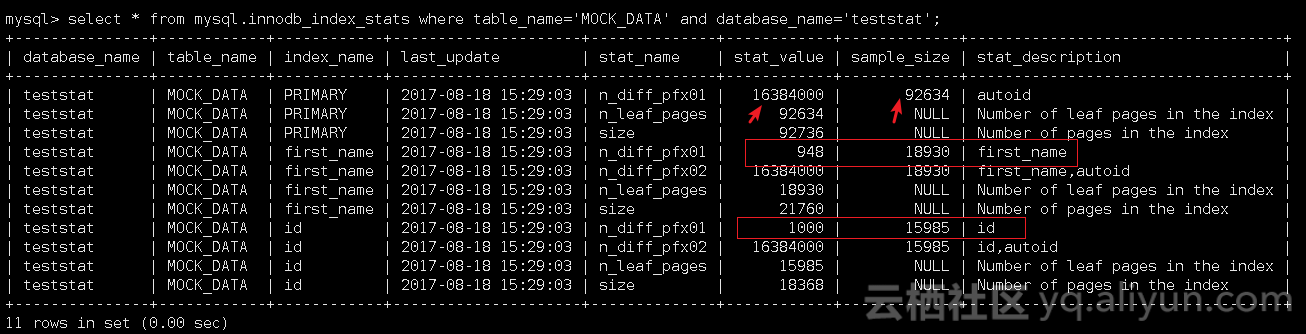
Index_name为id的stat_value为15185,即以index列为索引,在16384000的数据里有15185个不同值(实际是1至1000个不同值),index_name索引有18368个索引页(nonleaf page+leaf page),有15985个叶子页(leaf page)


该表经过统计,预估有16312847行数据,primary index有92736个索引页,除primary index外其他索引一共有40128个索引页(正好是innodb_index_stats中first_name和id索引页的和)

Index name为id的索引其Cardinality是30377(与innodb_index_stats中的stat_value的distinct value的数值不同)
如上获取的一些统计信息是在innodb_stats_persistent_sample_pages为20的情况下,手动analyze table MOCK_DATA生成的
2.4 执行查询
执行如下语句:
SET optimizer_trace="enabled=on";
EXPLAIN EXTENDED select count(1) from MOCK_DATA where id=1
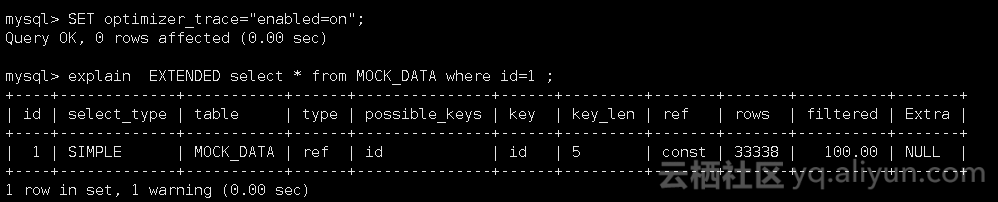
查看INFORMATION_SCHEMA.OPTIMIZER_TRACE表的优化器追踪信息:


以上是正常情况下的执行计划,下面进行修改统计信息数据,模拟统计信息对执行计划的影响在哪里
2.5 修改统计信息
只修改innodb_table_stats的n_rows变为10,同样执行:
SET optimizer_trace="enabled=on";
EXPLAIN EXTENDED select count(1) from MOCK_DATA where id=1
改完之后要执行flush table重新加载统计信息
如下:

执行计划:

和之前的对比,执行计划有明显的变化,再次查看INFORMATION_SCHEMA.OPTIMIZER_TRACE表的优化器追踪信息:


通过对比发现,虽然生成的执行计划使用的索引和access type没有错误,但是在生成过程中的cost与之前相比已经变化明显了。不准确的统计信息有很大可能对优化器的cost预估产生影响。所以我们可能有时候需要手工的进行统计信息的收集,除了统计信息还有很多情况会对optimizer的执行计划生成产生影响,比如索引的数量,索引数据的分布等等
第三节 统计信息收集
统计信息收集最常用的是analyze table 和optimize table,一般情况下这两个操作是有效的,但是也有少数情况analyze table和optimize table完全失效(获取不了准确的统计信息),即使我们知道表和索引的数据分布并非如此,我们也无法使用analyze和optimize来获取,此时可能就需要更精确的收集,拿上面的表举例子,其有16384000行数据,使用analyze 和optimize 在innodb_stats_persistent_sample_pages为20的情况下,对数据量大的表和索引预估可能并不完全准确(16384000已经比较准确了),如果我们需要其预估完全准确的话(正常情况下不需要完全准确,会加重统计信息采集时间),我们可以对innodb表尝试如下两种方式:
1, 调大innodb_stats_persistent_sample_pages的值,然后再执行analyze table
2,单独设置该表的STATS_SAMPLE_PAGES数量
2.1 调整innodb_stats_persistent_sample_pages
通过如下信息:
因为只有一个Primary key有92634和leaf page,没有其他的unique key,这里
分别设置innodb_stats_persistent_sample_pages为60000和92634和92635,
然后与默认的20进行对比,如下:
1),set global innodb_stats_persistent_sample_pages=60000:
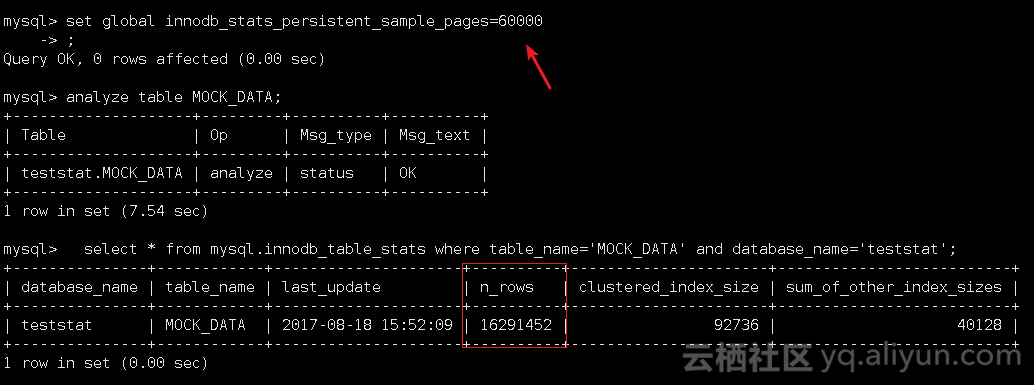
2),set global innodb_stats_persistent_sample_pages=92634:
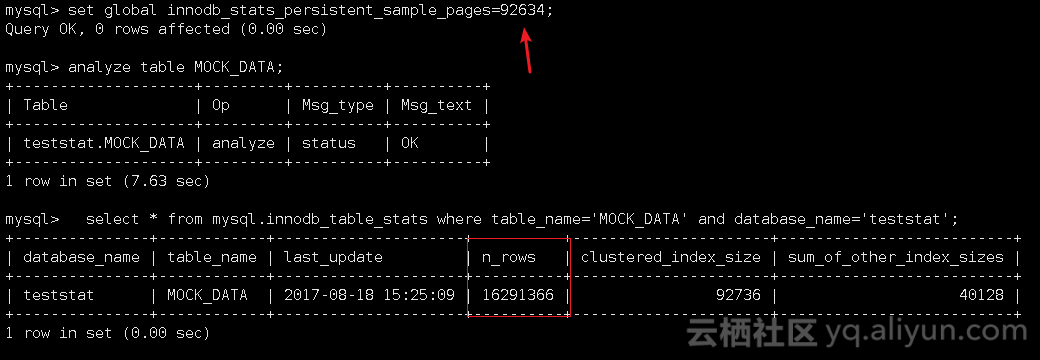
3),set global innodb_stats_persistent_sample_pages=92635:
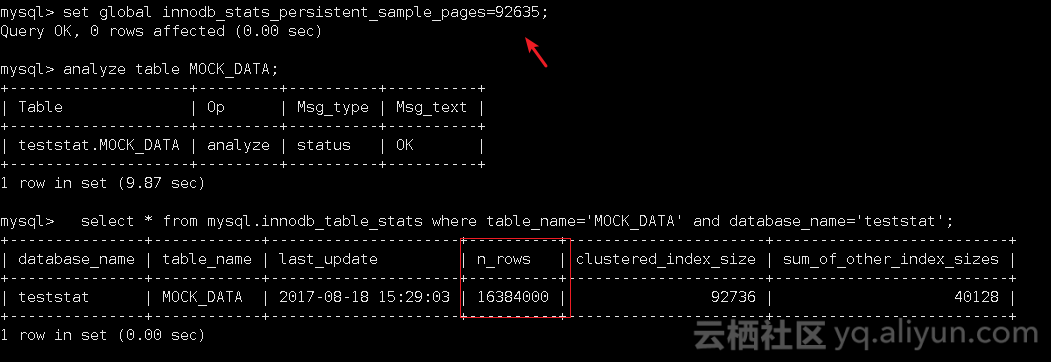
通过对比,当设置为92635(leaf page+1)时,数量才可以完全的准确,此时的mysql.innodb_index_stats表如下,已经很准确了,如下
2.2 调整STATS_SAMPLE_PAGES
同样分别设置STATS_SAMPLE_PAGES为60000和92634和92635
1),STATS_SAMPLE_PAGES=60000
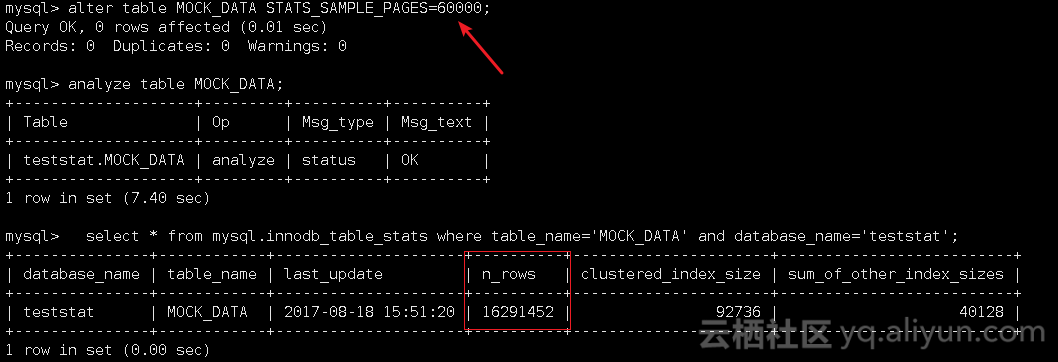
2),STATS_SAMPLE_PAGES=92634以及STATS_SAMPLE_PAGES=92634
![]()
3),调整STATS_SAMPLE_PAGES设置为 65535,该参数最大为65535(STATS_SAMPLE_PAGES的最大值,文档未标明,测试所得,应该是代码限制)
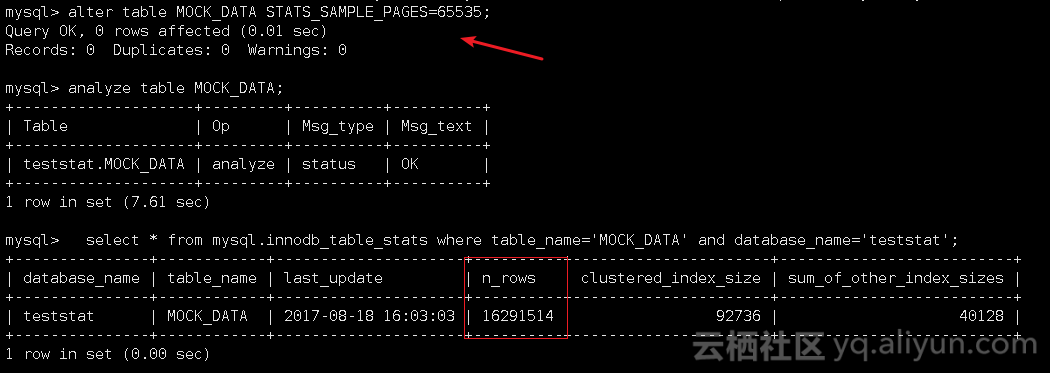
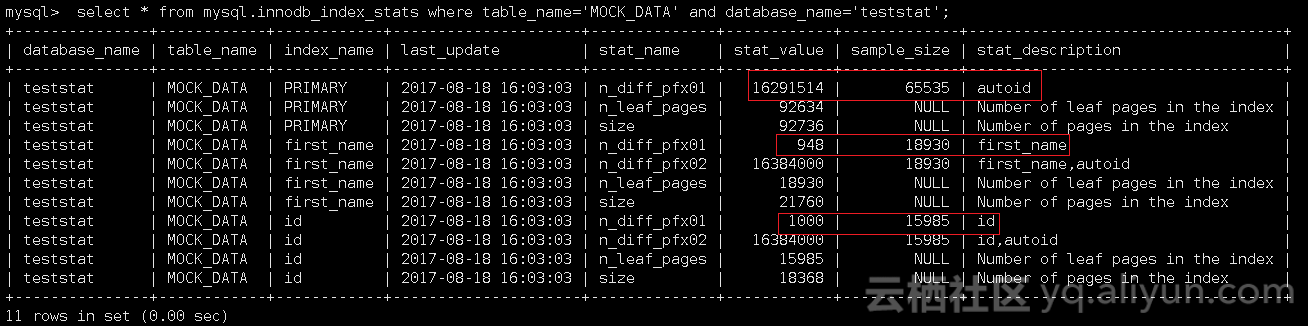
未能达到innodb_stats_persistent_sample_pages的效果,当STATS_SAMPLE_PAGES为65535时,此时innodb_index_stats的信息如下:
2.3 问题延伸
2.4 测试结果
通过测试,发现默认采集20个leaf page一般情况是比较准确的,故正常情况下,我们是不需要手工干预的,可以交给mysql根据数据量的变化自动统计,太精确的采集page数量过多会造成系统的负担,只有当明确的得知统计信息错误(表中的数据分布并非如此),而且默认采集page数量使用analyze和optimize无法获取更精确的统计信息时可以尝试这样做
问题:为何STATS_SAMPLE_PAGES最大值代码里限制为65535暂时不清楚为何,测试所得其最大为65535