2.4 安装和配置Hadoop集群
2.4.1 网络拓扑
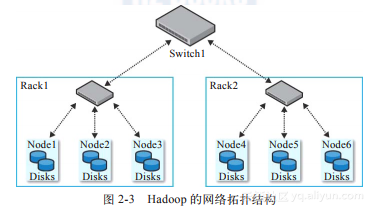
通常来说,一个Hadoop的集群体系结构由两层网络拓扑组成,如图2-3所示。结合实际应用来看,每个机架中会有30~40台机器,这些机器共享一个1GB带宽的网络交换机。在所有的机架之上还有一个核心交换机或路由器,通常来说其网络交换能力为1GB或更高。可以很明显地看出,同一个机架中机器节点之间的带宽资源肯定要比不同机架中机器节点间丰富。这也是Hadoop随后设计数据读写分发策略要考虑的一个重要因素。
2.4.2 定义集群拓扑
在实际应用中,为了使Hadoop集群获得更高的性能,读者需要配置集群,使Hadoop能够感知其所在的网络拓扑结构。当然,如果集群中机器数量很少且存在于一个机架中,那么就不用做太多额外的工作;而当集群中存在多个机架时,就要使Hadoop清晰地知道每台机器所在的机架。随后,在处理MapReduce任务时,Hadoop就会优先选择在机架内部做数据传输,而不是在机架间传输,这样就可以更充分地使用网络带宽资源。同时,HDFS可以更加智能地部署数据副本,并在性能和可靠性间找到最优的平衡。
在Hadoop中,网络的拓扑结构、机器节点及机架的网络位置定位都是通过树结构来描述的。通过树结构来确定节点间的距离,这个距离是Hadoop做决策判断时的参考因素。NameNode也是通过这个距离来决定应该把数据副本放到哪里的。当一个Map任务到达时,它会被分配到一个TaskTracker上运行,JobTracker节点则会使用网络位置来确定Map任务执行的机器节点。
在图2-3中,笔者使用树结构来描述网络拓扑结构,主要包括两个网络位置:交换机/机架1和交换机/机架2。因为图2-3中的集群只有一个最高级别的交换机,所以此网络拓扑可简化描述为/机架1和/机架2。
在配置Hadoop时,Hadoop会确定节点地址和其网络位置的映射,此映射在代码中通过Java接口DNSToSwitchMaping实现,代码如下:
public interface DNSToSwitchMapping {
public List<String> resolve(List<String> names);
} 其中参数names是IP地址的一个List数据,这个函数的返回值为对应网络位置的字符串列表。在opology.node.switch.mapping.impl中的配置参数定义了一个DNSToSwitchMaping接口的实现,NameNode通过它确定完成任务的机器节点所在的网络位置。
在图2-3的实例中,可以将节点1、节点2、节点3映射到/机架1中,节点4、节点5、节点6映射到/机架2中。事实上在实际应用中,管理员可能不需要手动做额外的工作去配置这些映射关系,系统有一个默认的接口实现ScriptBasedMapping。它可以运行用户自定义的一个脚本区完成映射。如果用户没有定义映射,它会将所有的机器节点映射到一个单独的网络位置中默认的机架上;如果用户定义了映射,那么这个脚本的位置由topology.script.file.name的属性控制。脚本必须获取一批主机的IP地址作为参数进行映射,同时生成一个标准的网络位置给输出。
2.4.3 建立和安装Cluster
要建立Hadoop集群,首先要做的就是选择并购买机器,在机器到手之后,就要进行网络部署并安装软件了。安装和配置Hadoop有很多方法,这部分内容在前文已经详细讲解过(见2.1节、2.2节和2.3节),同时还告诉了读者在实际部署时应该考虑的情况。
为了简化我们在每个机器节点上安装和维护相同软件的过程,通常会采用自动安装法,比如Red Hat Linux下的Kickstart或Debian的全程自动化安装。这些工具先会记录你的安装过程,以及你对选项的选择,然后根据记录来自动安装软件。同时它们会在每个进程结尾提供一个钩子执行脚本,在对那些不包含在标准安装中的最终系统进行调整和自定义时这是非常有用的。
下面我们将具体介绍如何部署和配置Hadoop。Hadoop为了应对不同的使用需求(不管是开发、实际应用还是研究),有着不同的运行方式,包括单机式、单机伪分布式、完全分布式等。前面已经详细介绍了在Windows、MacOSX和Linux下Hadoop的安装和配置。下面将对Hadoop的分布式配置做具体的介绍。
- Hadoop集群的配置
在配置伪分布式的过程中,大家也许会觉得Hadoop的配置很简单,但那只是最基本的配置。
Hadoop的配置文件分为两类。
1)只读类型的默认文件:src/core/core-default.xml、src/hdfs/hdfs-default.xml、src/mapred/mapred-default.xml、conf/mapred-queues.xml。
2)定位(site-specific)设置:conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml、conf/mapred-queues.xml。
除此之外,也可以通过设置conf/Hadoop-env.sh来为Hadoop的守护进程设置环境变量(在bin/文件夹内)。
Hadoop是通过org.apache.hadoop.conf.configuration来读取配置文件的。在Hadoop的设置中,Hadoop的配置是通过资源(resource)定位的,每个资源由一系列name/value对以XML文件的形式构成,它以一个字符串命名或以Hadoop定义的Path类命名(这个类是用于定义文件系统内的文件或文件夹的)。如果是以字符串命名的,Hadoop会通过classpath调用此文件。如果以Path类命名,那么Hadoop会直接在本地文件系统中搜索文件。
资源设定有两个特点,下面进行具体介绍。
1)Hadoop允许定义最终参数(final parameters),如果任意资源声明了final这个值,那么之后加载的任何资源都不能改变这个值,定义最终资源的格式是这样的:
<property>
<name>dfs.client.buffer.dir</name>
<value>/tmp/Hadoop/dfs/client</value>
<final>true</final> //注意这个值
</property>2)Hadoop允许参数传递,示例如下,当tenpdir被调用时,basedir会作为值被调用。
<property>
<name>basedir</name>
<value>/user/${user.name}</value>
<property>
<property>
<name>tempdir</name>
<value>${basedir}/tmp</value>
</property>
前面提到,读者可以通过设置conf/Hadoop-env.sh为Hadoop的守护进程设置环境变量。
一般来说,大家至少需要在这里设置在主机上安装的JDK的位置(JAVA_HOME),以使Hadoop找到JDK。大家也可以在这里通过HADOOP_*_OPTS对不同的守护进程分别进行设置,如表2-1所示。

一般而言,除了规定端口、IP地址、文件的存储位置外,其他配置都不是必须修改的,可以根据读者的需要决定采用默认配置还是自己修改。还有一点需要注意的是,以上配置都被默认为最终参数(final parameters),这些参数都不可以在程序中再次修改。
接下来可以看一下conf/mapred-queues.xml的配置列表,如表2-5所示。
表2-5 conf/mapred-queues.xml的配置
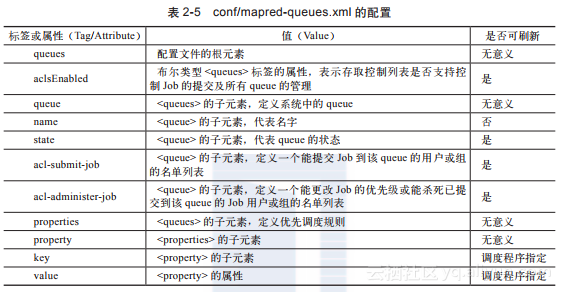
相信大家不难猜出表2-5的conf/mapred-queues.xml文件是用来做什么的,这个文件就是用来设置MapReduce系统的队列顺序的。queues是JobTracker中的一个抽象概念,可以在一定程度上管理Job,因此它为管理员提供了一种管理Job的方式。这种控制是常见且有效的,例如通过这种管理可以把不同的用户划分为不同的组,或分别赋予他们不同的级别,并且会优先执行高级别用户提交的Job。
按照这个思想,很容易想到三种原则:
同一类用户提交的Job统一提交到同一个queue中;
运行时间较长的Job可以提交到同一个queue中;
把很快就能运行完成的Job划分到一个queue中,并且限制queue中Job的数量上限。
queue的有效性很依赖在JobTracker中通过mapreduce.jobtracker.taskscheduler设置的调度规则(scheduler)。一些调度算法可能只需要一个queue,不过有些调度算法可能很复杂,需要设置很多queue。
对queue大部分设置的更改都不需要重新启动MapReduce系统就可以生效,不过也有一些更改需要重启系统才能有效,具体如表2-5所示。
conf/mapred-queues.xml的文件配置与其他文件略有不同,配置格式如下:
<queues aclsEnabled="$aclsEnabled">
<queue>
<name>$queue-name</name>
<state>$state</state>
<queue>
<name>$child-queue1</name>
<properties>
<property key="$key" value="$value"/>
...
</properties>
<queue>
<name>$grand-child-queue1</name>
...
</queue>
</queue>
<queue>
<name>$child-queue2</name>
...
</queue>
...
...
...
<queue>
<name>$leaf-queue</name>
<acl-submit-job>$acls</acl-submit-job>
<acl-administer-jobs>$acls</acl-administer-jobs>
<properties>
<property key="$key" value="$value"/>
...
</properties>
</queue>
</queue>
</queues>
以上这些就是Hadoop配置的主要内容,其他关于Hadoop配置方面的信息,诸如内存配置等,如果有兴趣可以参阅官方的配置文档。
- 一个具体的配置
为了方便阐述,这里只搭建一个有三台主机的小集群。
相信大家还没有忘记Hadoop对主机的三种定位方式,分别为Master和Slave,JobTracker和TaskTracker,NameNode和DataNode。在分配IP地址时我们顺便规定一下角色。
下面为这三台机器分配IP地址及相应的角色:
10.37.128.2—master,namonode,jobtracker—master(主机名)
10.37.128.3—slave,dataNode,tasktracker—slave1(主机名)
10.37.128.4—slave,dataNode,tasktracker—slave2(主机名)
首先在三台主机上创建相同的用户(这是Hadoop的基本要求):
1)在三台主机上均安装JDK 1.6,并设置环境变量。
2)在三台主机上分别设置/etc/hosts及/etc/hostname。
hosts这个文件用于定义主机名与IP地址之间的对应关系。
/etc/hosts:
127.0.0.1 localhost
10.37.128.2 master
10.37.128.3 slave1
10.37.128.4 slave2
hostname这个文件用于定义Ubuntu的主机名。
/etc/hostname:
“你的主机名”(如master,slave1等)3)在这三台主机上安装OpenSSH,并配置SSH可以免密码登录。
安装方式不再赘述,建立~/.ssh文件夹,如果已存在,则无须创建。生成密钥并配置SSH免密码登录本机,输入命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将文件复制到两台Slave主机相同的文件夹内,输入命令:
scp authorized_keys slave1:~/.ssh/
scp authorized_keys slave2:~/.ssh/
查看是否可以从Master主机免密码登录Slave,输入命令:
ssh slave1
ssh slave2
4)配置三台主机的Hadoop文件,内容如下。
conf/Hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk
conf/core-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp</value>
</property>
</configuration>
conf/hdfs-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
conf/mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
conf/masters:
master
conf/slaves:
slave1
slave2
5)启动Hadoop。
bin/Hadoop NameNode –format
bin/start-all.sh
你可以通过以下命令或者通过http://master:50070及http://master:50030查看集群状态。
Hadoop dfsadmin –report