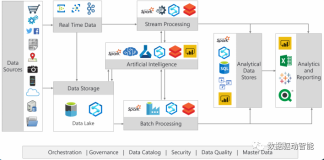
全球领先的大数据分析服务供应商Teradata天睿公司(Teradata Corporation,纽交所:TDC)宣布旗下Think Big公司运用Apache Spark 扩展数据湖与管理服务业务。Think Big公司是Teradata天睿公司旗下全球化咨询公司,拥有领先的Apache Spark及其它大数据技术部署能力。Spark是一套开源集群计算平台,可用于产品推荐、预测分析、传感器数据分析、图形分析等多个领域。
目前,客户可在搭载“通用硬件”的一般Hadoop环境中部署云端Apache Spark使用数据湖。客户还可在Teradata Hadoop专用平台上使用。该平台是功能最强大的就绪式企业级平台,专为运行企业级大数据工作负载进行预置和优化。
随着Spark受到越来越多的关注,许多企业正在尽力跟上这一开源平台快节奏的变化和发布频率。Think Big公司已经成功将Spark融入创建企业级品质数据湖和分析应用的开发框架。
数据仓库研究院(TDWI)数据管理研究负责人Philip Russom博士表示:“许多企业正在尝试部署Apache Spark,通常会结合数据湖使用,希望能发挥其在流数据、查询和分析上的优势。但用户很快意识到,Spark并不容易使用,而且数据湖所需规划与设计超出用户想象。在这种情况下,用户需要求助于外部顾问和管理服务提供商,他们需要具备为各种不同类型的客户顺利部署Apache Spark和数据湖的可靠经验。Think Big公司正拥有这样的经验。”
Think Big公司正在为部署Spark开发可复制的服务包,包括在提供数据湖和管理服务时,将Spark增加为执行引擎。Think Big还将通过旗下培训分支机构Think Big大数据学院(Think Big Academy)为企业客户提供一系列全新Spark培训课程。这些培训课程由经验丰富的讲师讲解,面向经理、开发人员和管理员培训如何使用Spark及机器学习、图形、流、查询等各种Spark模块。
Think Big数据科学团队还将开源Spark Python应用程序接口(API)的分布式K-Modes集群源程序。这些程序将为客户细分和客户流失分析提升分类数据集群性能。用户可访问Think Big公司的GitHub页面,获取该程序代码及Think Big其它开源项目。
Think Big公司总裁Ron Bodkin表示:“Think Big咨询业务正从美洲地区迅速拓展至欧洲和中国,因为首次接触数据湖时,企业对正确使用Spark和Hadoop所需专业技术、经验和方法的需求正在爆炸性增长。部署Spark应成为企业信息与分析战略中的重要组成部分。我们依据经验提供相关的使用案例,提出适当的问题,并提防部署中应注意的雷区。我们了解商业用户的期望和技术需求。我们能帮助客户创造真实的商业价值,而我们的Spark客户已在全渠道消费个性化、高科技制造业实时故障检测等领域付诸实践。”
早在大数据热潮兴起之前,Think Big就已成为全球首家专注大数据服务的领导企业,致力于运用新兴技术实施分析解决方案。现在,Think Big依托完善的流程、健全的工具和经验丰富的大数据技术专家,在平台和应用支持方面为Hadoop提供管理服务,以经济的方式管理、监控并维护Hadoop平台。Think Big公司通过完善测试的转换流程,进行每一次部署安排,通过评估并提升客户的生产支持、开发和维持团队,使部署卓有成效。
本文转自d1net(转载)