首届阿里巴巴中间件技术峰会上,阿里巴巴数据库资深专家何登成带来“AliSQL 引领开源技术变革之路”的演讲,本文从回顾AliSQL发展史开始谈起,接着分析了X-KV接口的好处,最后着重分享了X-Cluster——AliSQL集群解决方案。
以下是精彩内容整理:
AliSQL发展历史简要回顾
为了去IOE,从2010年我们选择Alibaba的MySQL分支AliSQL。
我们为什么发展一个MySQL分支呢?最主要的思考还是在于生态,当我们去选择开源数据库时,我们会发现MySQL的整个生态、社区对于其它数据库来说是庞大的。我们发展MySQL开源分支是因为开源数据库在Alibaba体量下还是会碰到许多问题,比如性能、功能和可运维性,我们都作了相应优化。

在2010~2016期间,我们做了100+ 项的优化,包括bug 修复、功能增强、性能突破和可运维性的增强,目前为止,ALiSQL很多的新功能都被吸收到了开源数据库中。
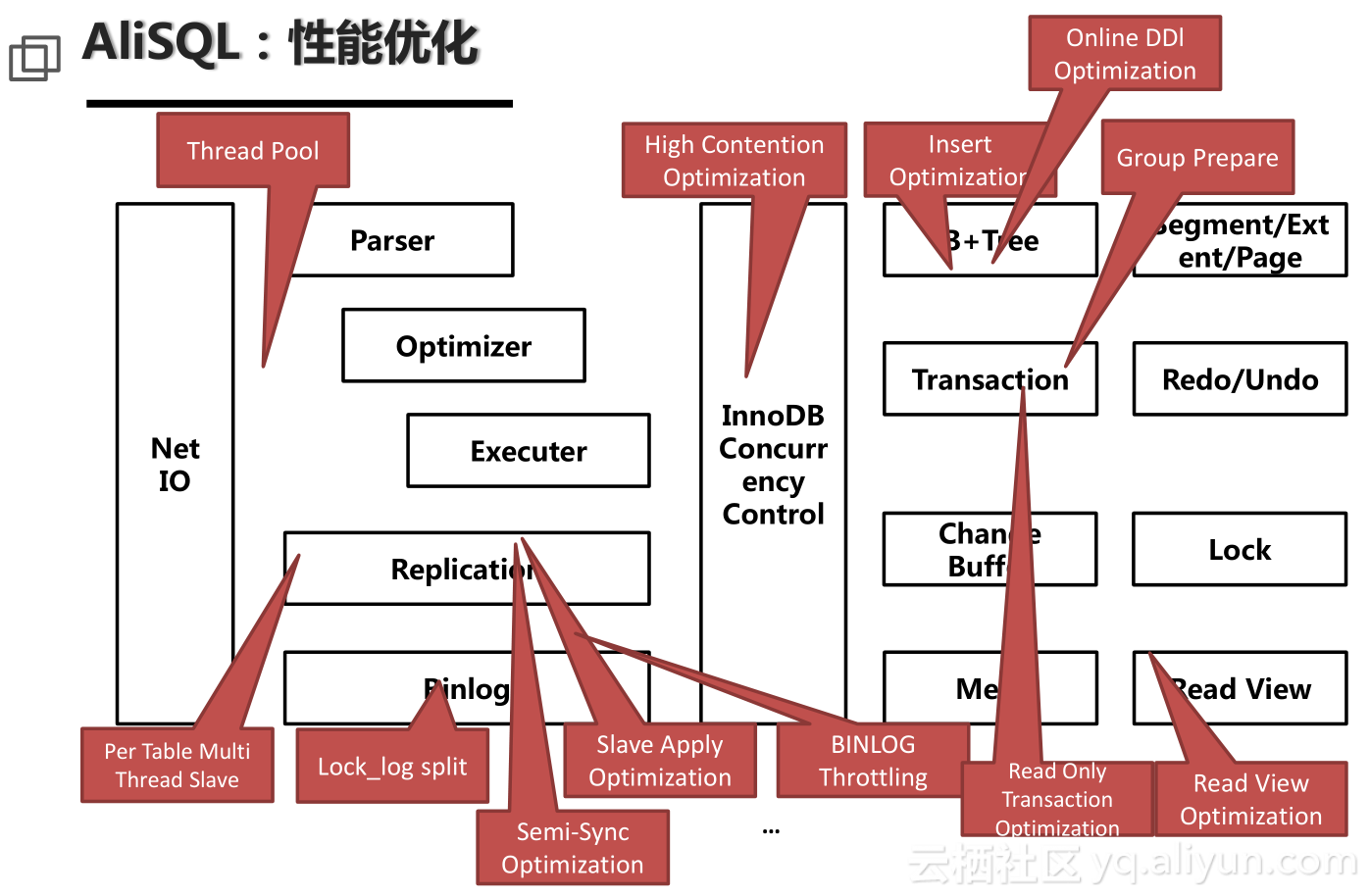
图为AliSQL精简架构。我们在各个核心模块都做了改进,比如Binlog、Read View等等。
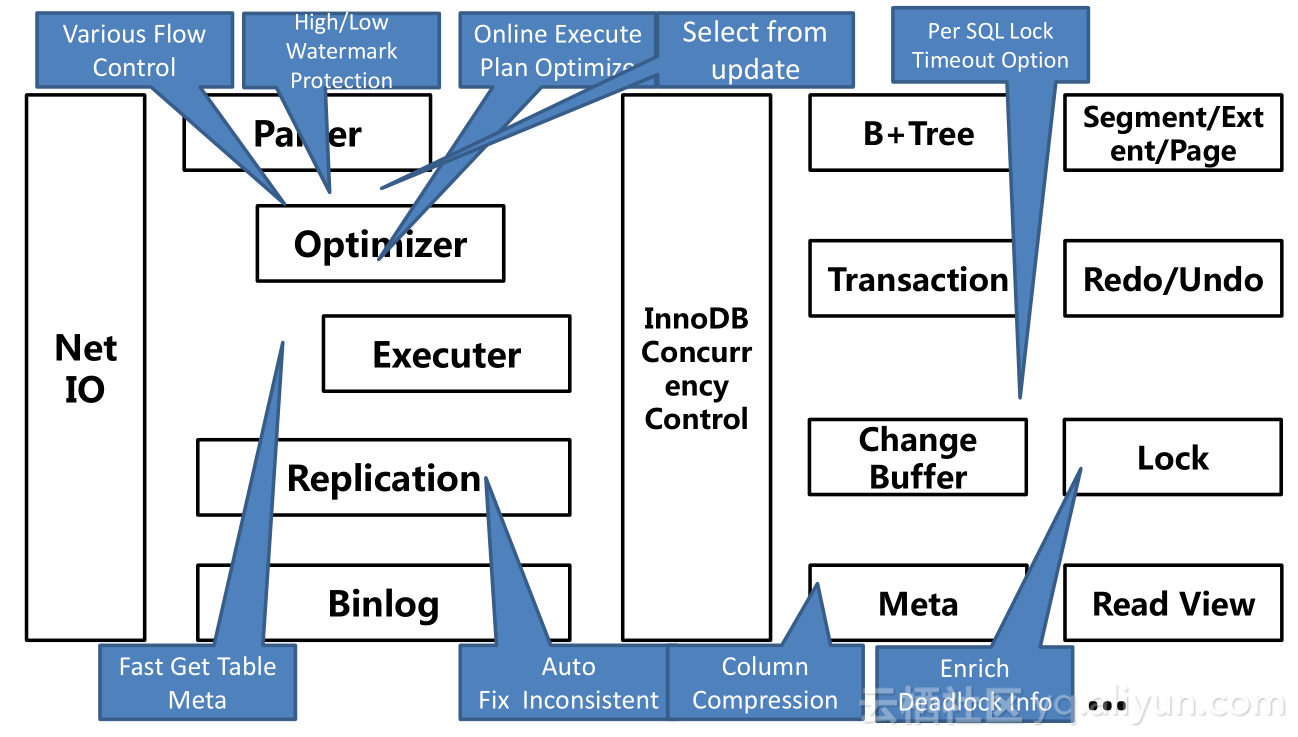
功能和可运维增强也有很多改进,我们不仅仅是在使用,而是真正做了很多创新,这些创新我们也会回馈给社区。
X-KV:高性能K-V接口
X-KV是AliSQL高性能K-V接口,InnoDB Memcached Plugin的扩展。
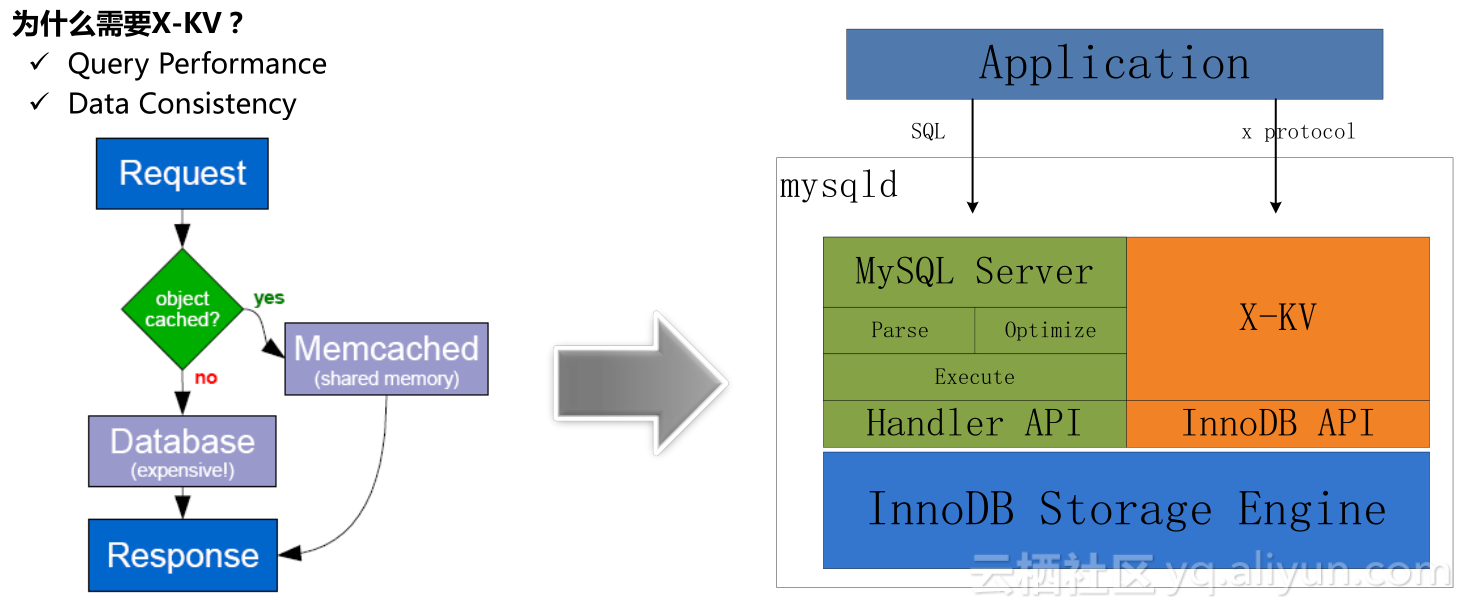
为什么需要X-KV?左图是比较经典的部署,有前端的用户请求、数据库,数据库扩展性能时会在数据库和应用层之间加cache,访问频率比较高的放到缓存和内存中,用缓存区域查询问题是目前通用的解决方案,但它不一定是最好的。那么,我们如何保证数据和缓存的数据一致性呢?我们探索从KV接口直接访问存储引擎中的数据,这样可以绕过MySQL Server层的很多复杂逻辑,比如Parse、Optimize、Execute和数据的转换、投影等。
X-KV的具体优化如下:
- 我们将Data Type支持能力丰富了,不光支持Float/Double、Integer、Decimal,还包括DateTime、Char/Varchar、Custom Format。
- 用KV访问数据支持的接口比较有限,我们在功能上也做了增强,比如Multi get from multi tables,Non-unique index,composite indexes & prefix search,能够覆盖更多的场景。
- X-KV新协议。InnoDB Memcached Plugin存在一些问题,通过指定delimiter来区分每一列,delimiter如何选择?NULL和空值无法区分,NULL = 空。
X-KV新协议将以上问题解决了,我们将返回的Field=Meta Info + Data,加Meta Info来描述返回数据,Meta Info有Version|Count|Length1|Length2|Length3…
- 可运维性优化。官方设计不考虑太多运维性,导致InnoDB Memcached Plugin存在一些问题,比如表结构变更后,如何使得KV接口能够无缝的切换到新的schema, 原有的plugin uninstall ->install 方式对业务有较大影响。X-KV通过扩充Container表,支持了在线的KV配置变更,通过版本号来控制新旧版本的schema配置并自动重新加载。
- 性能优化。
0
我们模拟阿里的交易数据库上的Query请求做了验证,相对于走SQL,我们提升了5倍左右的性能。
X-Cluster:AliSQL集群解决方案
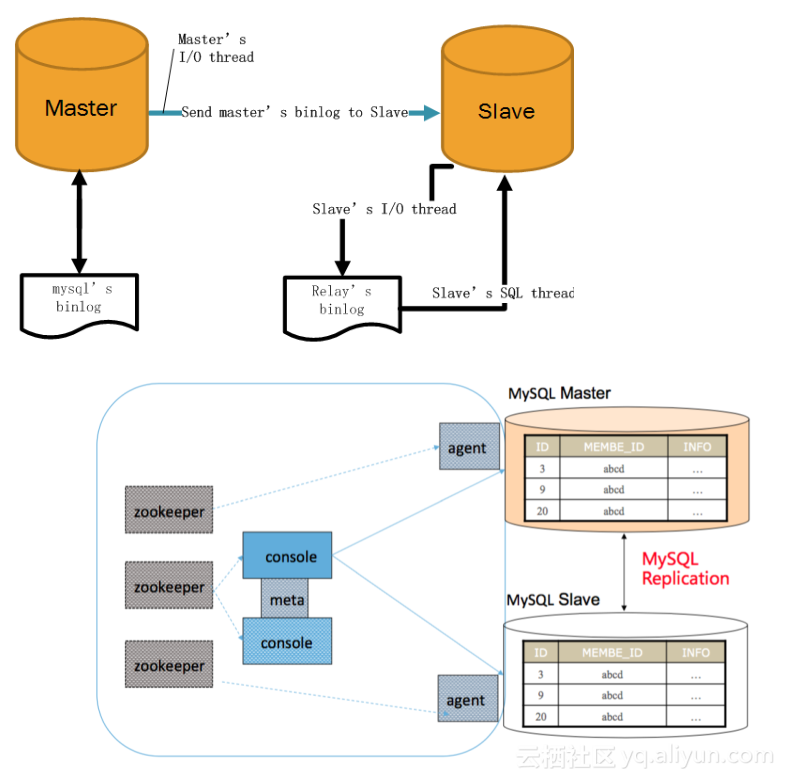
为什么做X-Cluster呢?
1. 首先是数据一致性的问题。传统的数据库都是主备的异步复制,异步复制带来的是数据质量问题;官方为了解决问题,提出半同步复制,但半同步复制过段时间会降级。所以它们都很难百分百保证数据质量。
2. 持续高可用问题。当我们搭建完MySQL主备后,主备本身不会做切换,不会做高可用,真正的高可用是在主备之外使用一个外部组件,比如基于zookeeper的HA来提供高可用功能。
3. 区域化/全球化部署问题。过去几年我们分享最多的是异地双活和异地多活,我们要做到真正多城市多活高可用,需要集群能耗跨城市部署,跨国际部署。
4. 上下游生态联动。我们的数据库不仅仅作数据存取,下游还要给其他系统作消费。
能不能用一种技术尝试解决掉这些问题呢?这是我们做X-Cluster的初衷。
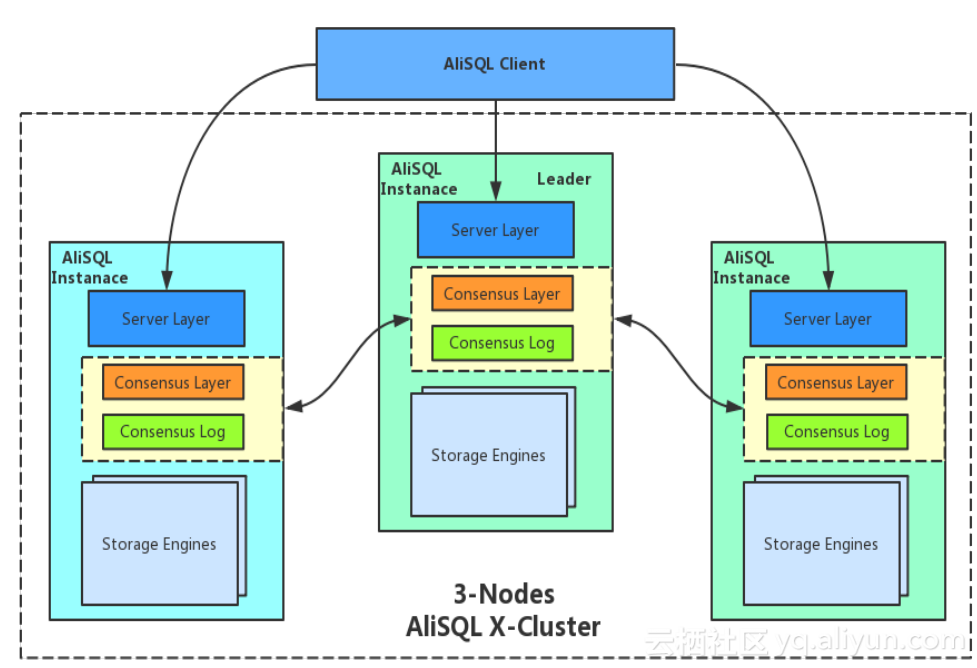
我们的设计目标是:
- 一体化架构:运维友好
- 极致性能:同城三副本相对于单机性能下降在10%以内
- 可异地部署:异地部署,延时增加,但是保持高吞吐
- 稳定性:网络抖动高容忍性
- 兼容性:对原有生态100%兼容
我们交付出一个AliSQL集群化的解决方案,将分布式一致性协议Paxos引入到AliSQL上,我们可以去组件一个AliSQL真正的集群,通过Paxos实现日志的强同步,实现自动化选主。
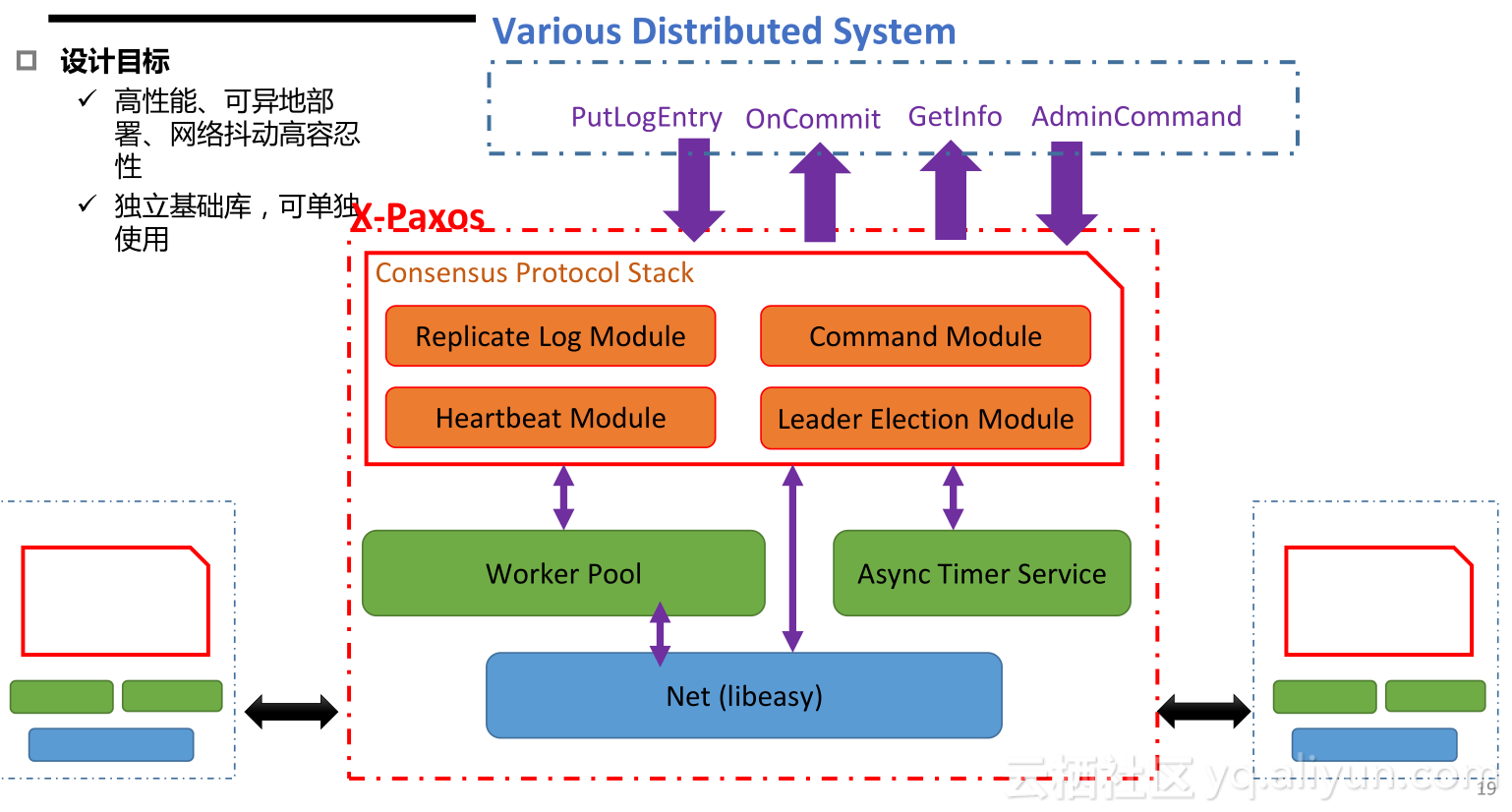
X-Cluster核心组件X-Paxos,X-Paxos就是高性能分布式一致性算法。
X-Cluster核心技术
Batching & Pipelining
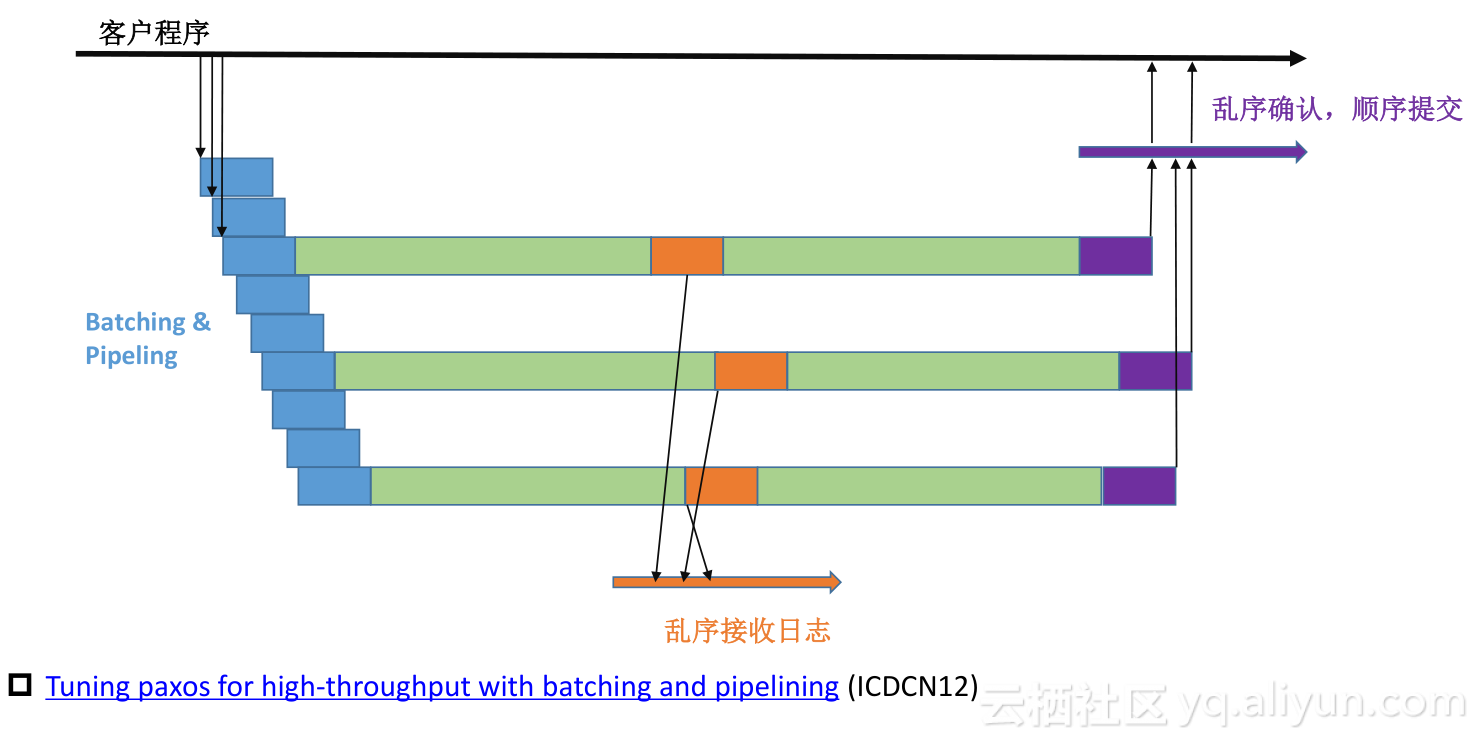
如何实现再有网络延时,尤其有异地网络延时、长延时、短延时以及不同网络条件下怎么样去做高性能真正与单机性能几乎持平?我们使用了Batching&Pipelining。
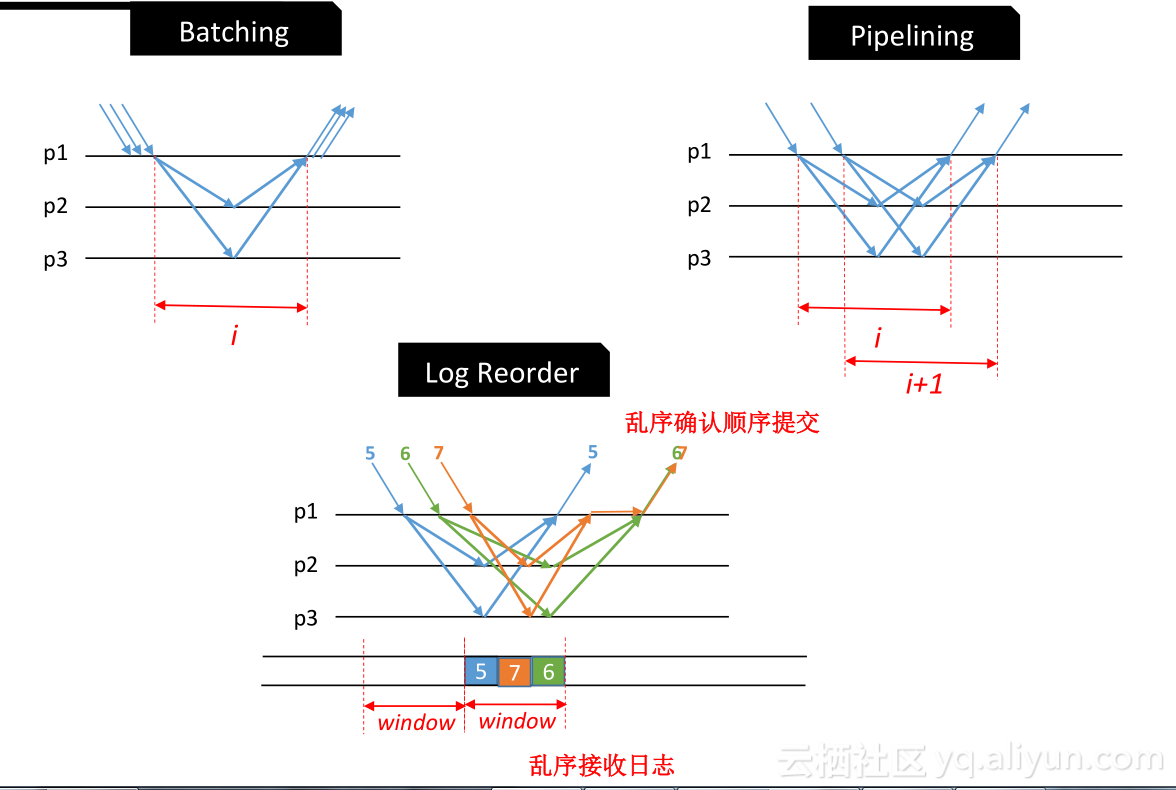
Pipelining是当一批往follower发送时,follower返回之前能不能把下一批在leader上已经完成的事务再发出去,这样就会同时有多批事务从leader等待follower达成多数派,这就是所谓的Pipelining。原来Batching时,是一次只能发一批,等应答后再发下一批,每一批至少会有一个网络的RTT,Pipelining好处是在第一批没有应答前就可以发送第二批···
引入Pipelining就会带来乱序,导致日志空洞,会出现乱序接收。Paxos可以作乱序确认,乱序确认的好处是,如果有日志空洞,任意两个副本达成多数派,都认为事务提交成功。每一个follower上都有空洞,但是将两个follower拼在一起,它是一个完整的日志流。
Locality Aware Content Distribution
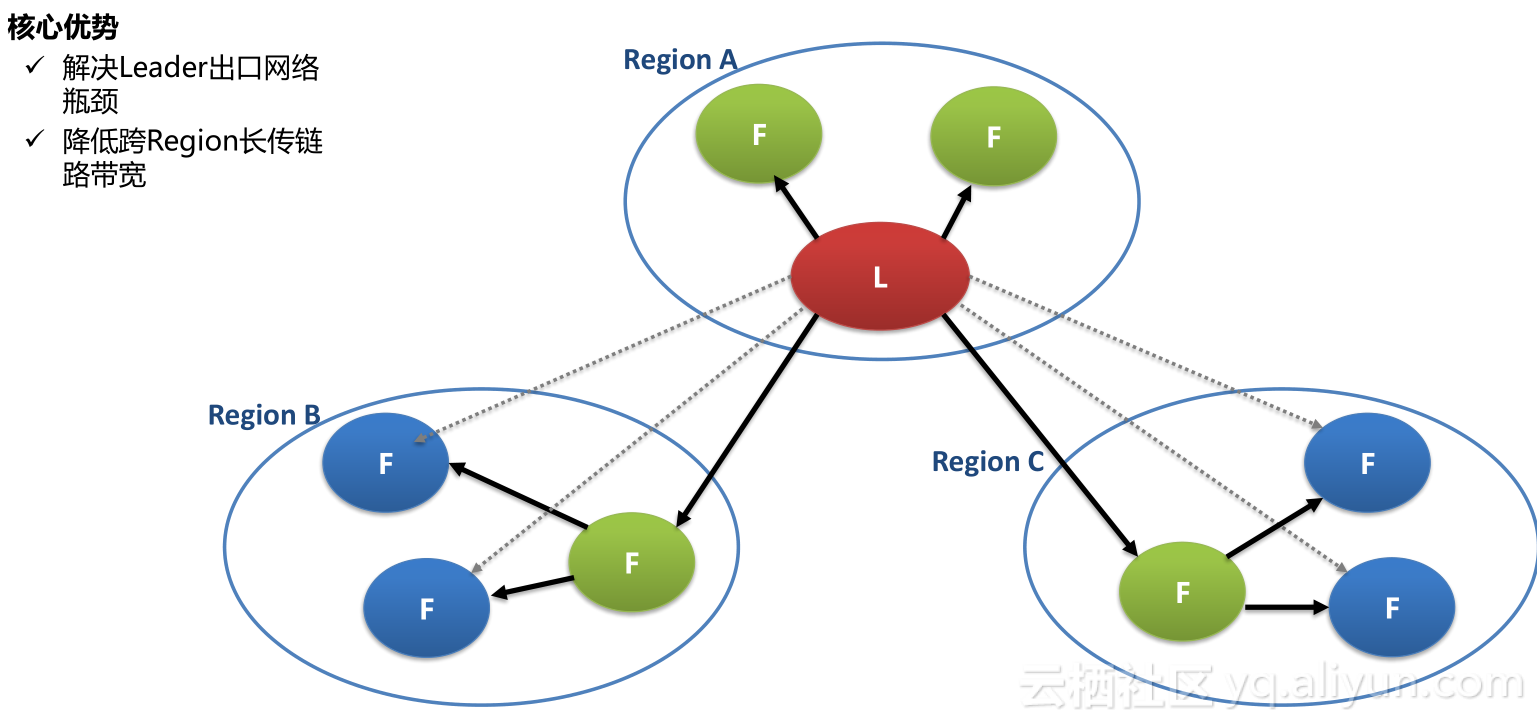
有了Paxos之后,多少副本都可以。为了解决Leader出口网络,降低跨Region长传链路带宽,我们在跨Region时使follower可以连在follower上,用级联的方式去复制。
日志实现
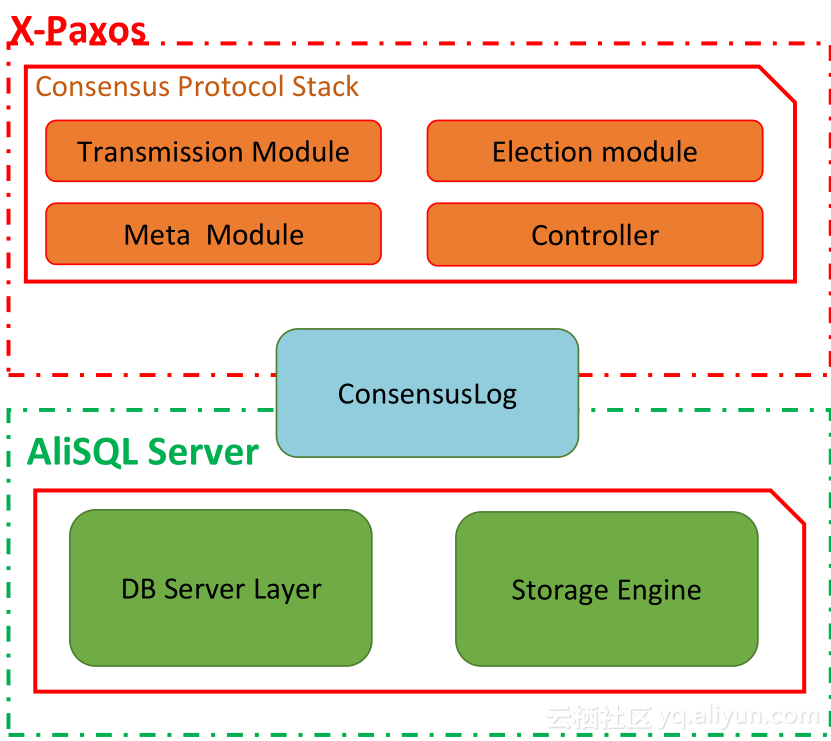
还有我们做了一体化日志:插件式X-Paxos的日志,归一化的ConsensusLog代替Binlog和RelayLog,全局统一的Log Index。
Asynchronously Commit
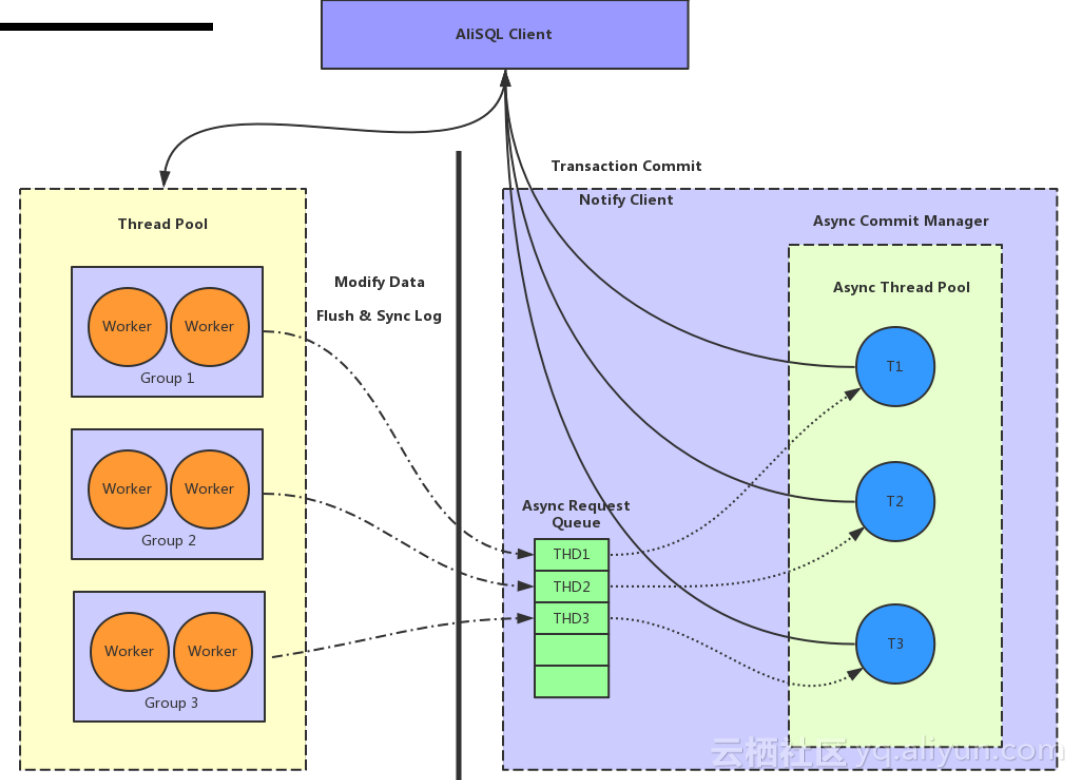
我们还将工作线程和提交线程异步化,工作线程只负责处理事务提交之外的用户请求,在用户发送提交请求后,工作线程将事务推入提交等待队列后就继续处理下一个用户请求。而提交等待队列的中的事务由另外一批线程来负责处理,这样能够充分解放工作线程,减少线程的等待,提高高延时下的吞吐性能。
X-Cluster: vs MySQL Group Replication
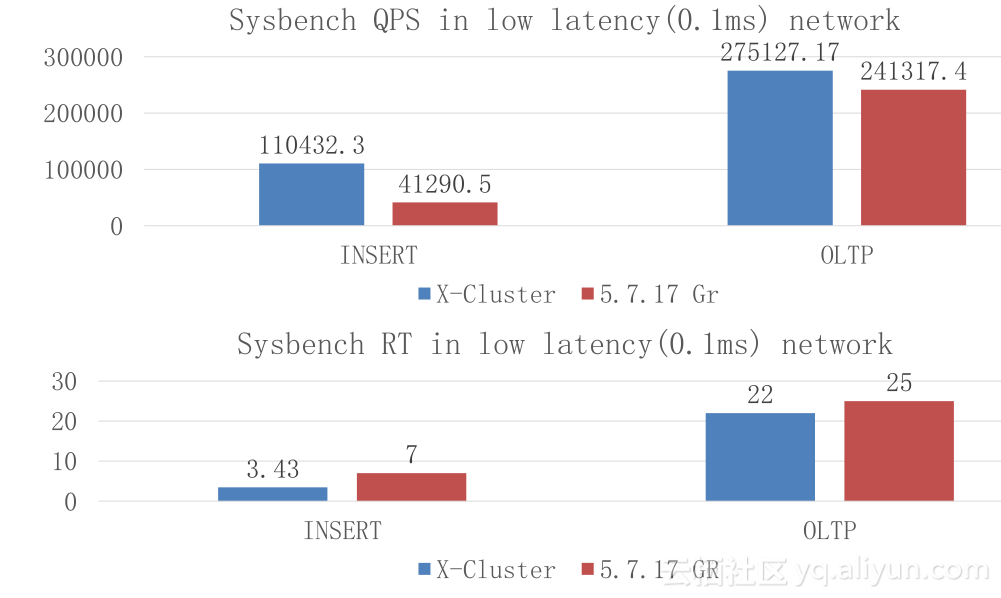
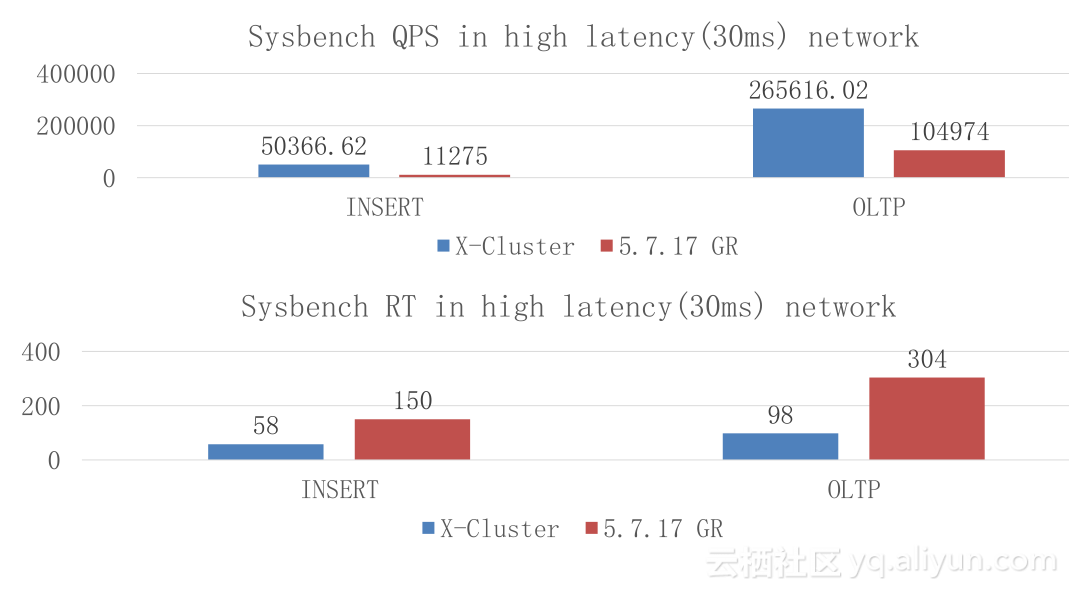
我们与MySQL Group Replication对比,做了简单的性能测试。可以看出,INSERT同城比官方好两倍性能,延时要小很多;30ms 网络延时的部署下,我们仍旧能够达到五万多,延时只有官方的三分之一,性能是五倍。
X-Cluster生态
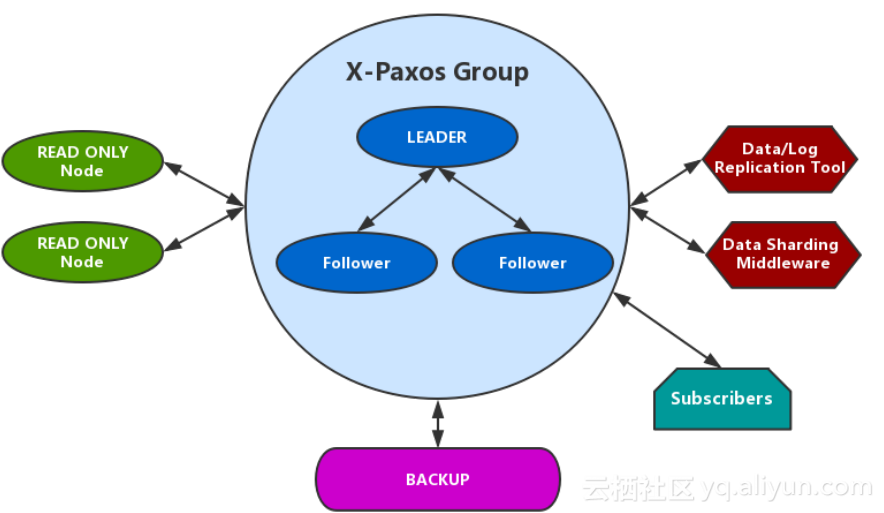
我们面临的问题很多,比如备份、日志订阅、只读节点等,所以我们要超越数据一致性和持续可用,Paxos关联的东西有很多。
持续备份
原有MySQL备份逻辑是:定期备份Binlog文件;RPO一般比较大,例如:大于5分钟;备份跟MySQL的数据一致性保障困难。
X-Cluster可以解决备份的一些不便之处:备份节点作为X-Cluster的一个Learner节点,实时推送X-Cluster上达成多数派的日志;RPO < 1秒;由于备份的一定是达成多数派的日志,因此无数据一致性问题。
自动化高可用
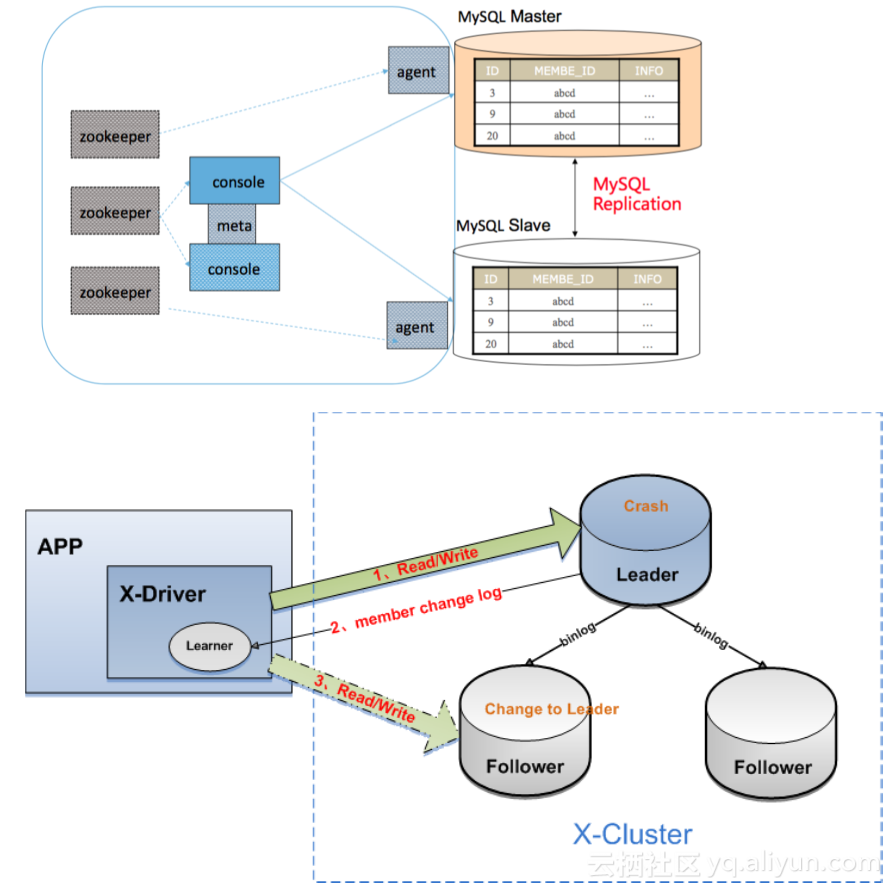
原有MySQL高可用方案外部组件依赖:ADHA、ZK。而X-Cluster自动化高可用,Client、Server一体化,Client也是数据库一个learner节点,它需要消费成员变更日志,成员变更日志达成多数派后推给learner节点,Driver就会知道主备发生切换,可以直接连新leader,没有外部组件依赖,达到自动化高可用。
自动化增量日志消费
原有MySQL下游日志消费准实时消费MySQL产生的日志,问题之一是数据一致性;问题之二是数据库主备切换与下游消费端的联动。
X-Cluster自动化增量日志消费,日志消费节点作为X-Cluster的Learner节点,只消费达成多数派的日志,保证数据一致性;X-Cluster自动选主,新Leader自动向日志消费节点推送新日志,彻底解决联动问题。
区域化/全球化部署
- 按需增加Learner节点:增加读能力,但是不会带来强同步开销
- 按需增加Log节点:Log节点只有日志,没有数据;Log节点可参与选主,但是没有新增存储开销。低成本节点;3节点X-Cluster = 2节点MySQL主备。
- 权重化体系:可以指定节点选主权重,控制每个节点的选主优先级。
X-Cluster实战总结
一路走来,我们并不是一帆风顺,也踩过很多坑,比如:
- 异常处理:硬件异常,网络异常:Leader Stickiness
- Batching & Pipelining:极大事务,极小事务,不同网络时延下的Batching/Pipelining策略,网络异常情况下的Batching/Pipelining策略
- 全球化部署下的优化:权重体系、热点带来的影响

