
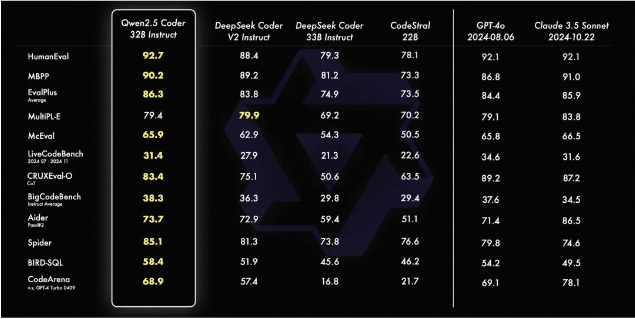
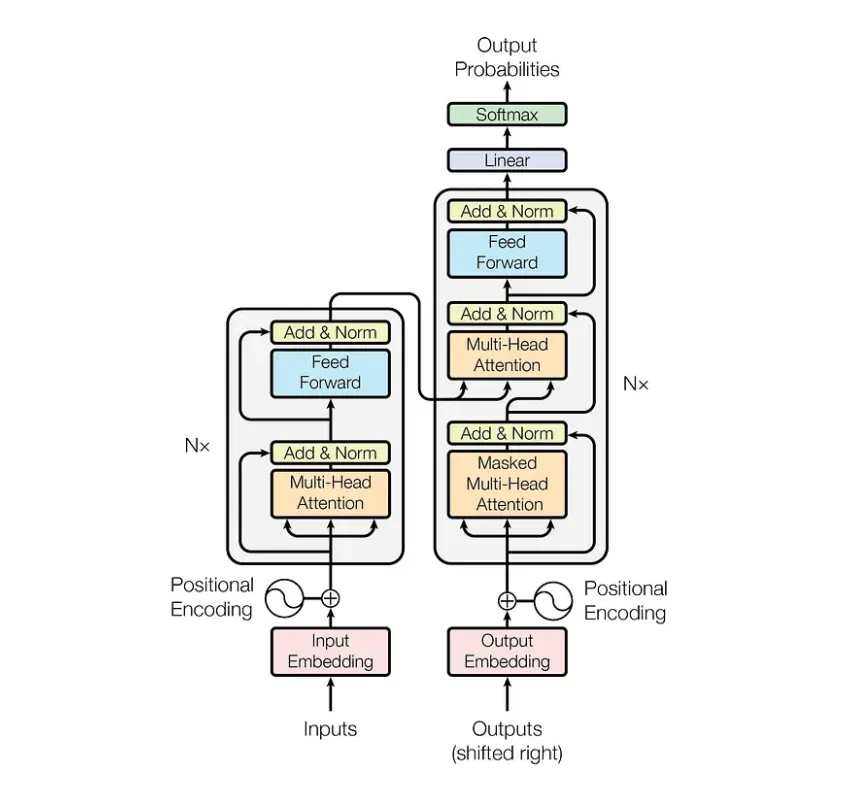
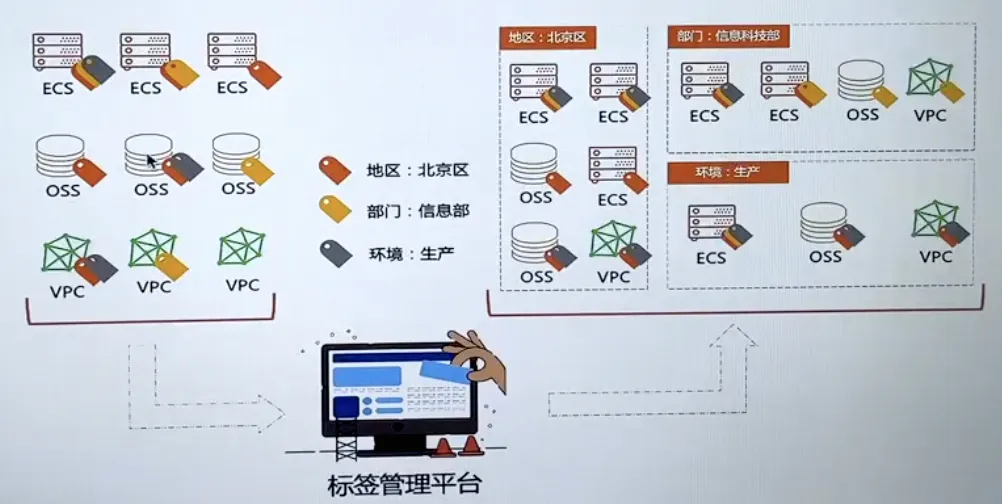
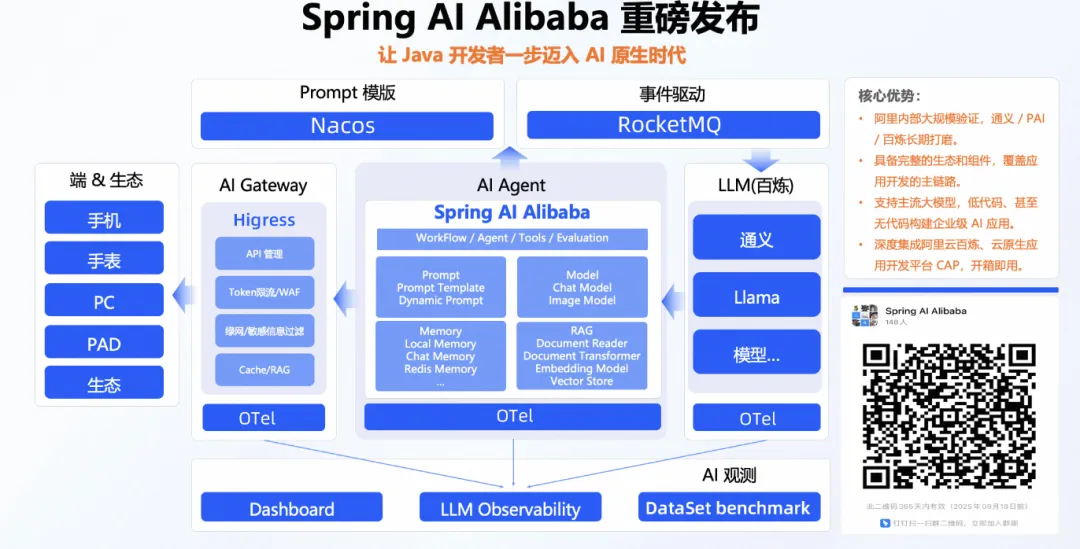
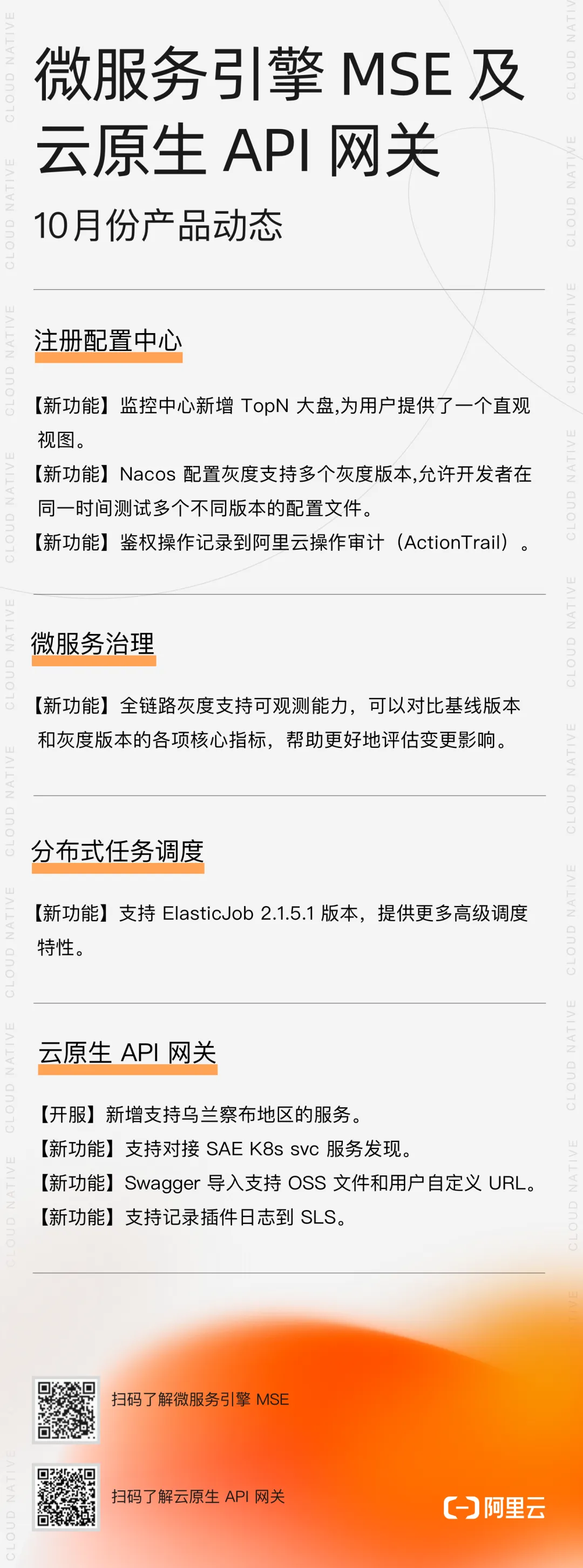
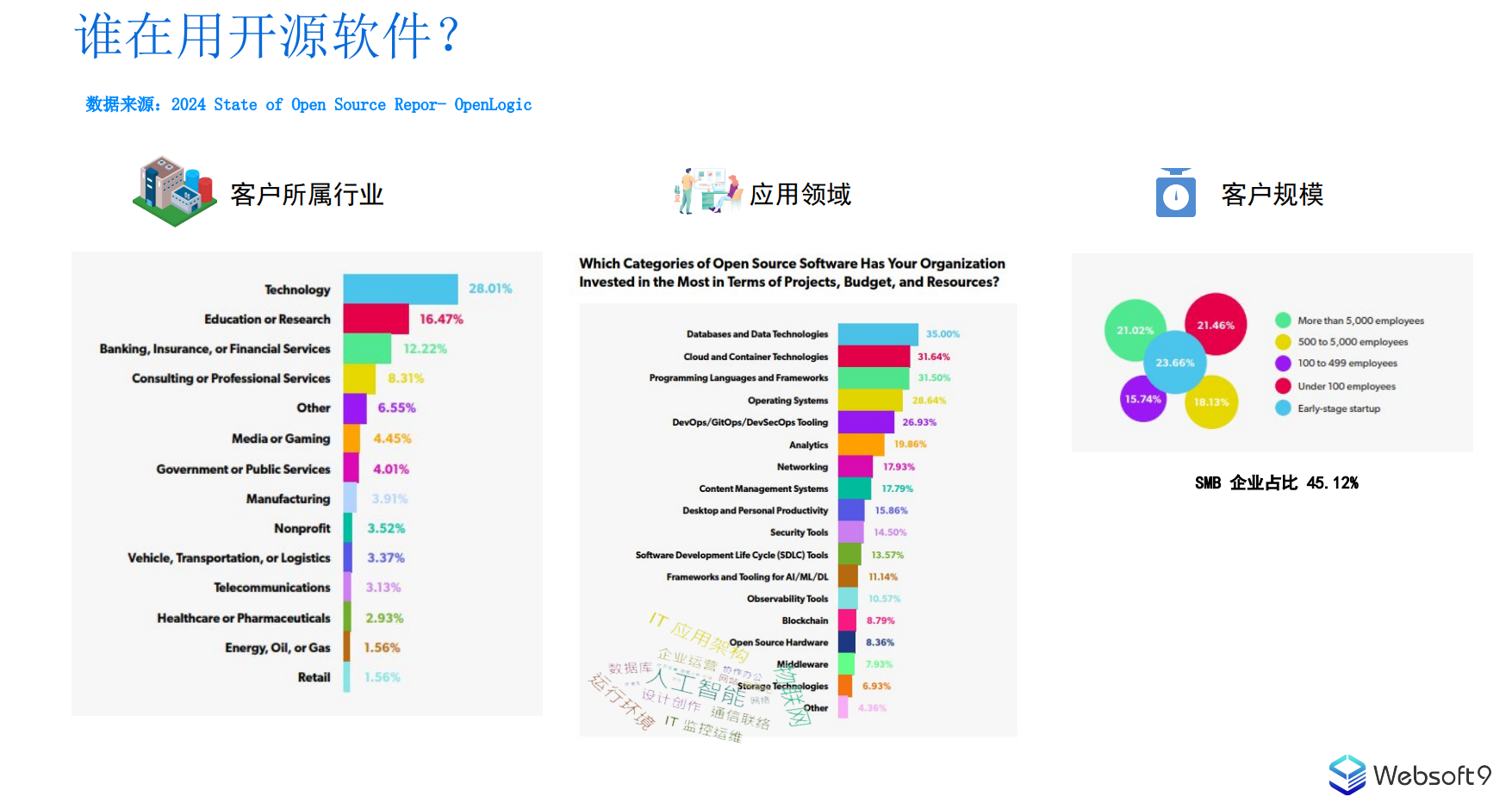
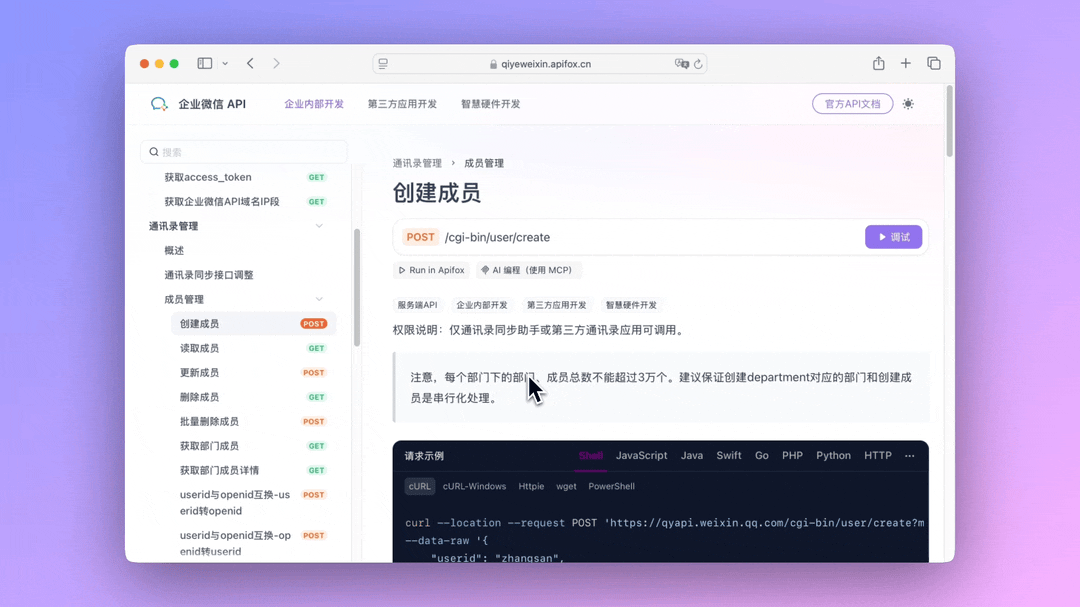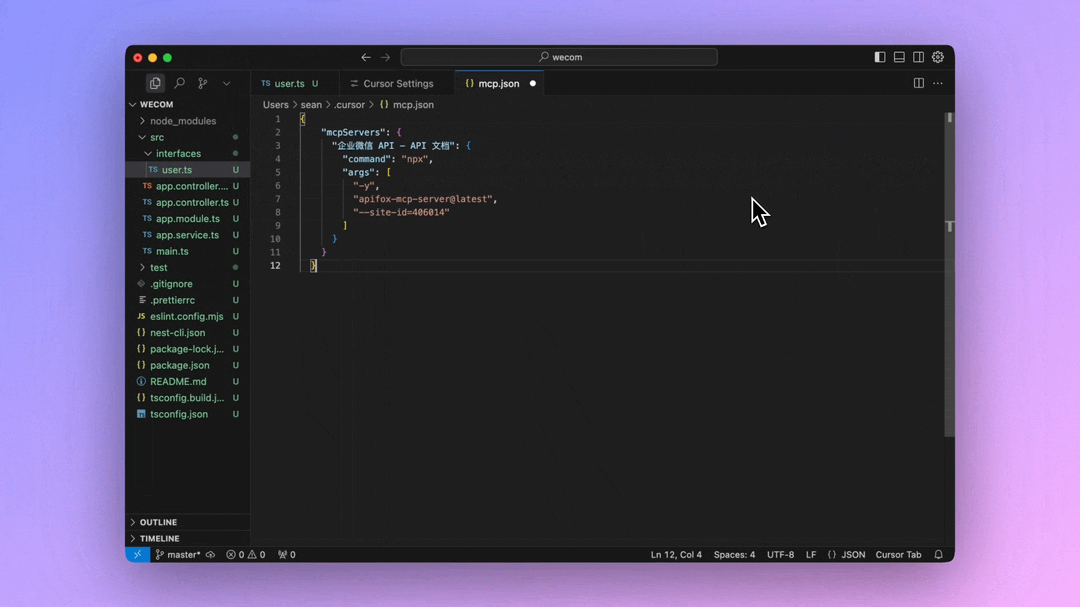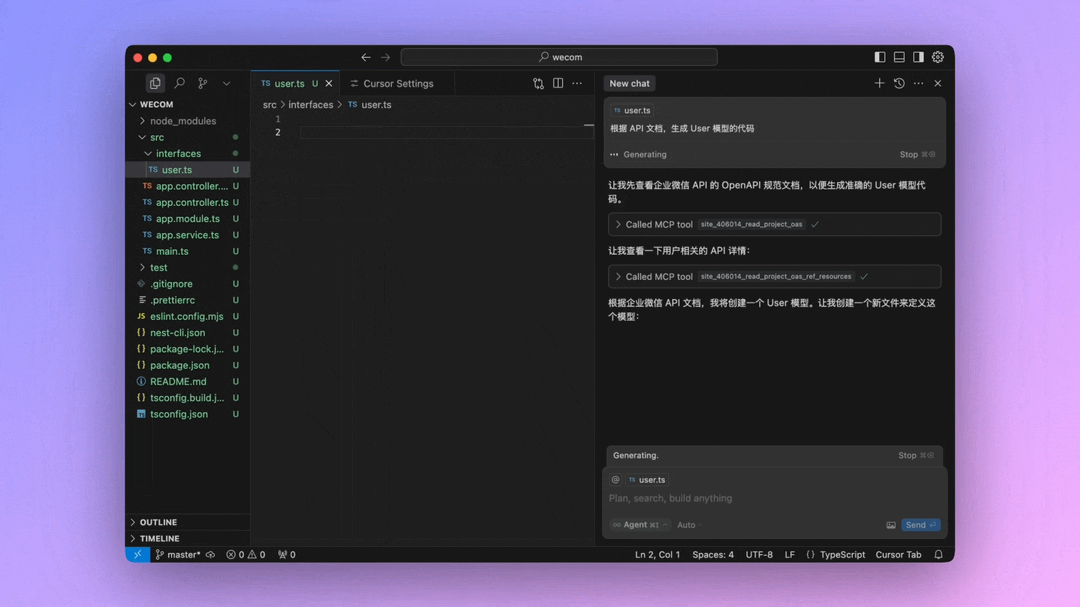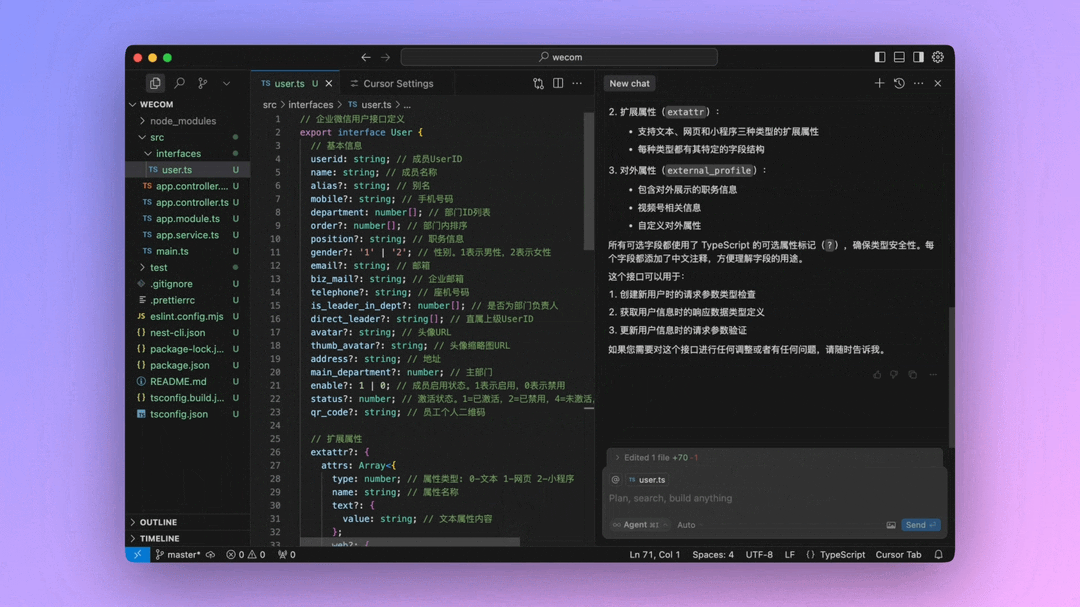
QwQ-32B一键部署,真正的0代码,0脚本,0门槛
























你好,我是AI助理
可以解答问题、推荐解决方案等
