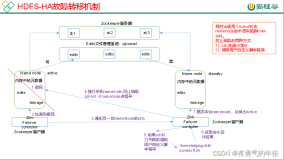
1.每个节点启动zookeeper 服务
zkServer.sh start
2.每个节点先启动journal node
hadoop-daemon.sh start journalnode
3.在某一台NameNode节点,例如nn1上格式化文件系统,并启动nn1的namenode
#格式化hdfs
hdfs namenode -format
#启动当前节点NameNode
hadoop-daemon.sh start namenode
4.在另一台NameNode nn2上同步nn1的数据,并启动nn2
#从另一台NameNode节点同步数据
hdfs namenode -bootstrapStandby
#启动当前节点NameNode
hadoop-daemon.sh start namenode
#每个节点启动DataNode
hadoop-daemon.sh start datanodes
5.在zookeeper中初始化namenode的信息
hdfs zkfc -formatZK
6.停止所有hdfs
stop-dfs.sh
7.启动hdfs文件系统
start-dfs.sh
8.正常的话会启动nn,dn,jn,zkController
[beifeng@hadoop-master ~]$ start-dfs.sh
Starting namenodes on [hadoop-master hadoop-slave1]
hadoop-slave1: starting namenode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-namenode-hadoop-slave1.out
hadoop-master: starting namenode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-namenode-hadoop-master.out
hadoop-slave2: starting datanode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-datanode-hadoop-slave2.out
hadoop-slave1: starting datanode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-datanode-hadoop-slave1.out
hadoop-master: starting datanode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-datanode-hadoop-master.out
Starting journal nodes [hadoop-master hadoop-slave1 hadoop-slave2]
hadoop-master: starting journalnode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-journalnode-hadoop-master.out
hadoop-slave1: starting journalnode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-journalnode-hadoop-slave1.out
hadoop-slave2: starting journalnode, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-journalnode-hadoop-slave2.out
Starting ZK Failover Controllers on NN hosts [hadoop-master hadoop-slave1]
hadoop-slave1: starting zkfc, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-zkfc-hadoop-slave1.out
hadoop-master: starting zkfc, logging to /opt/app/hadoop-2.5.0/logs/hadoop-beifeng-zkfc-hadoop-master.out
9.启动yarn
start-yarn.sh
10.启动历史人物日志功能
mr-jobhistory-daemon.sh start historyserver