热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
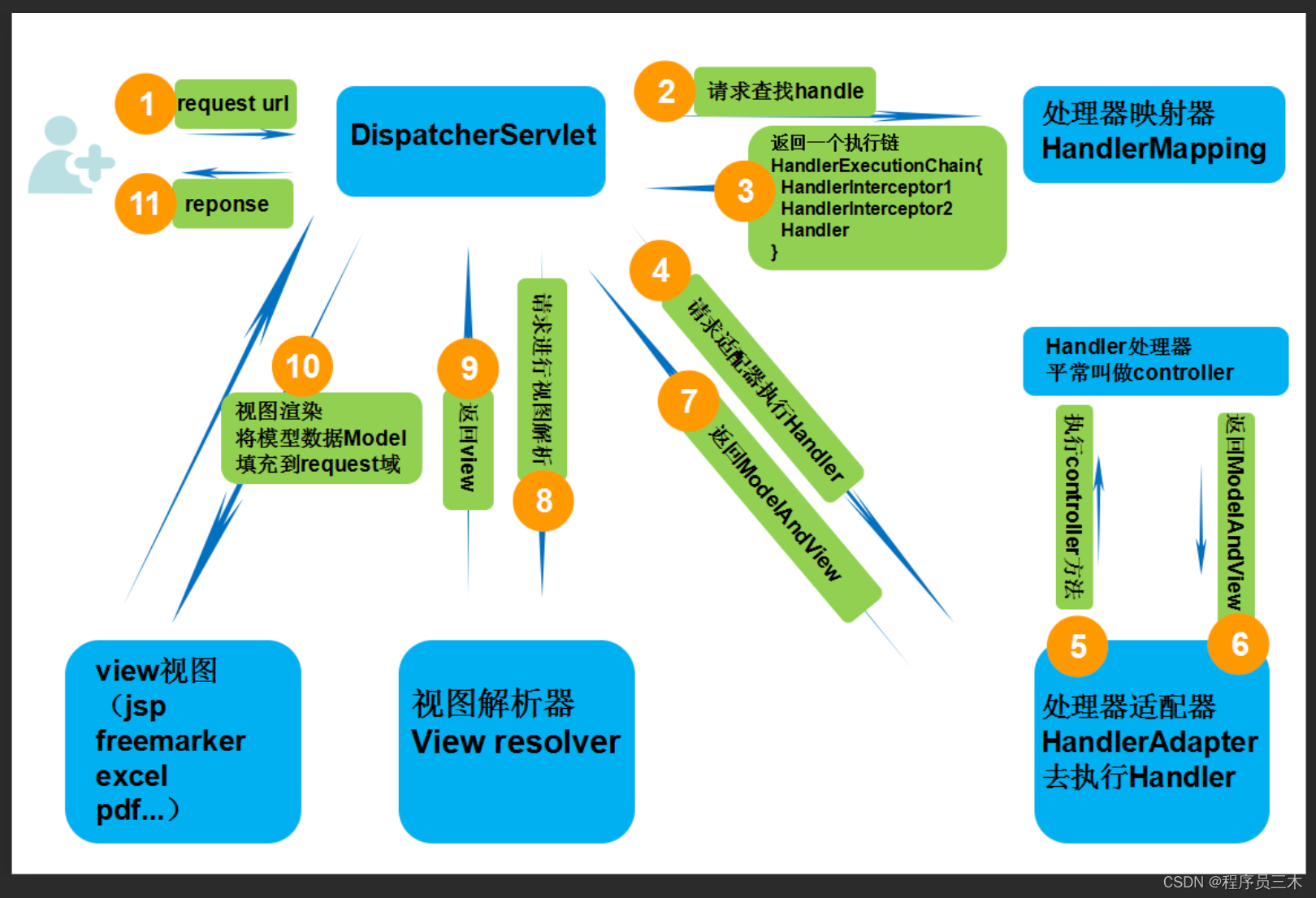
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
[leetcode] 705. 设计哈希集合
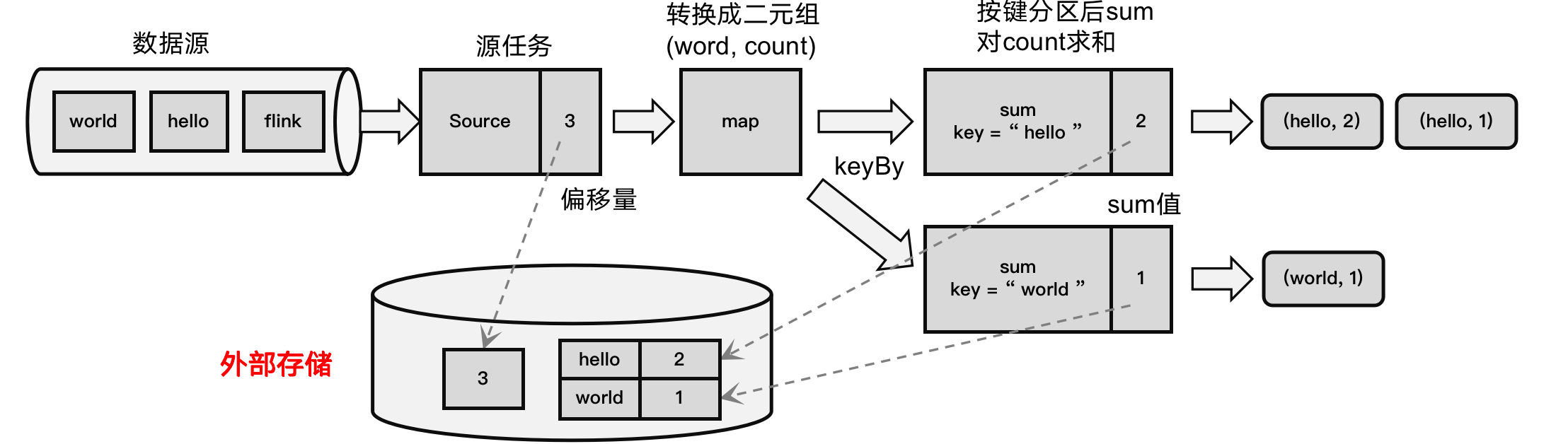
[尚硅谷flink] 检查点笔记
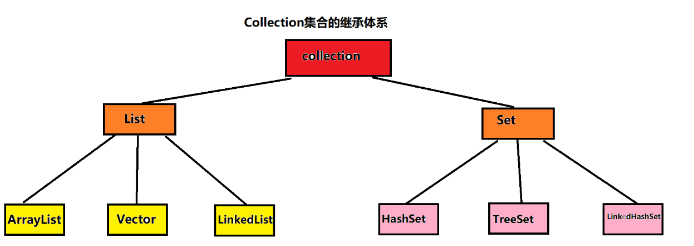
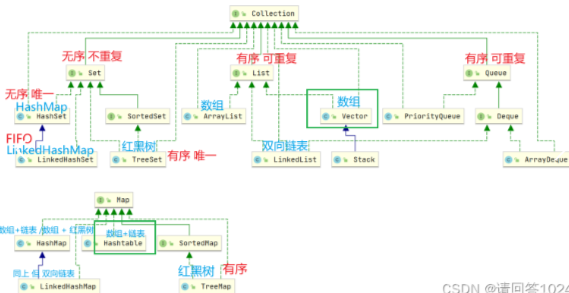
JavaSE&Collection集合
Java堆内存又溢出了!教你一招必杀技
深入理解Java异常处理机制
构建高效云原生应用:容器化与微服务架构的融合
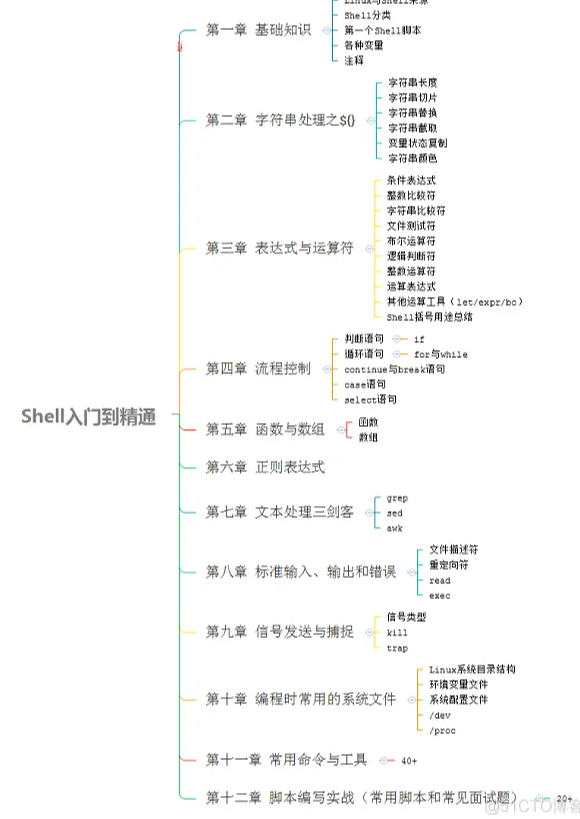
Shell和Python学习教程总结
构建未来:使用Flutter框架开发跨平台移动应用
深入理解自动化测试:框架选择与实践策略
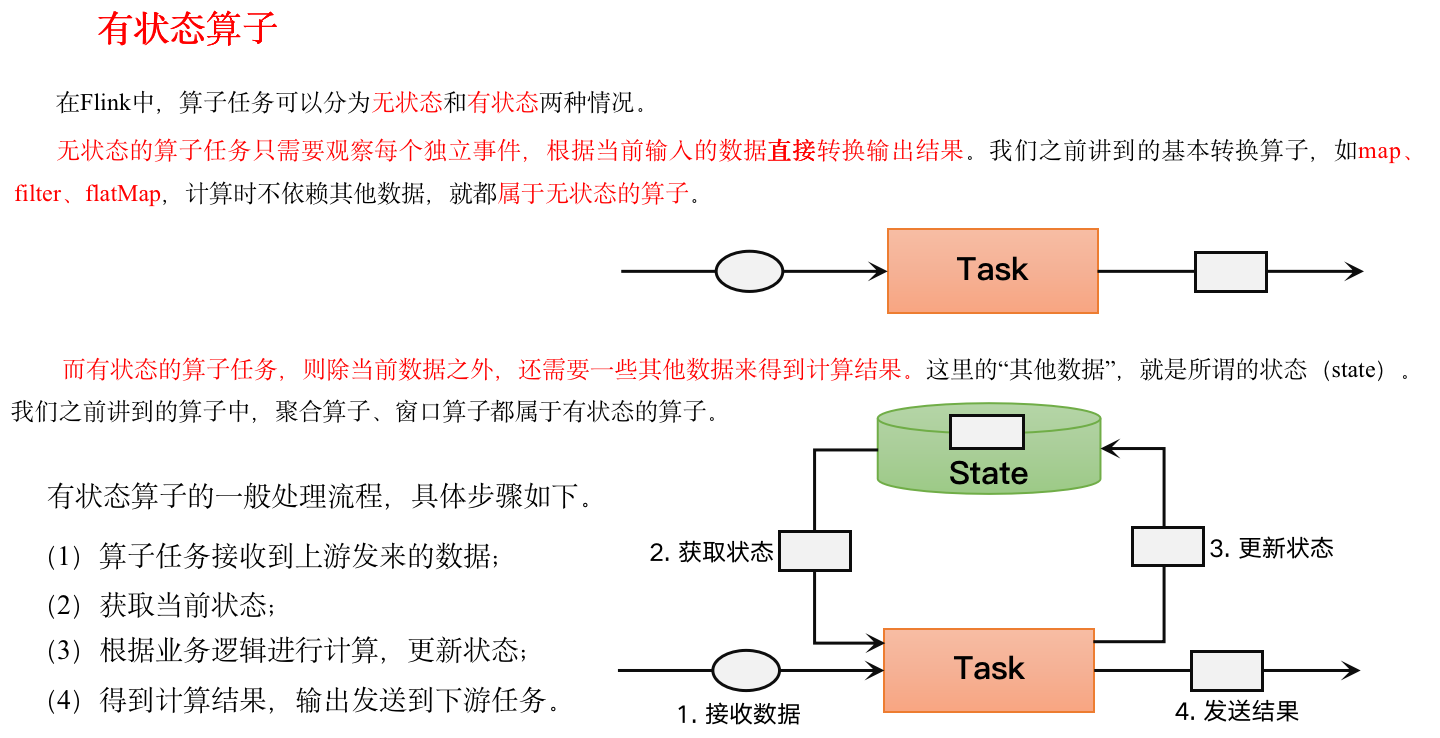
[尚硅谷 flink] 状态管理 笔记
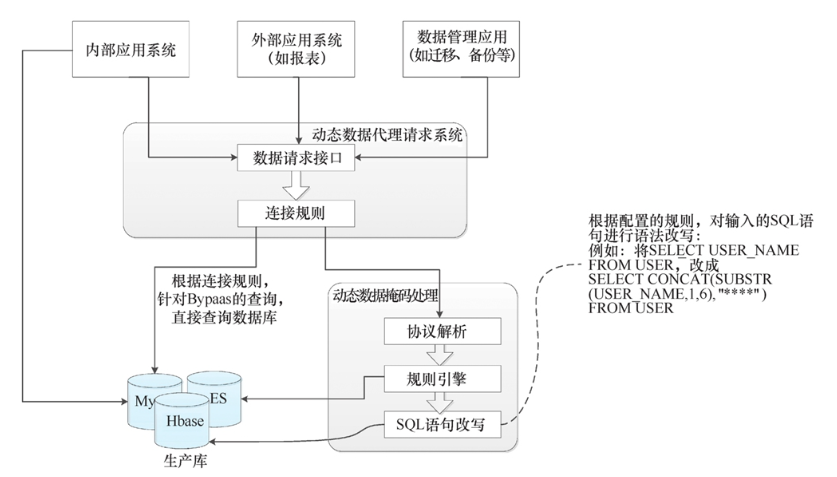
数据脱敏技术
移动应用开发的未来:跨平台框架与原生系统之争
LTE:连接你我,5G时代的前奏
编码和解码的未来之路
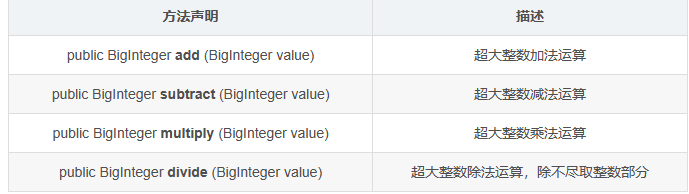
JavaSE&常用API(BigInteger,BigDecimal,Arrays,包装类)
使用 kubeadm 快速部署一个 Kubernetes 集群
数字时代是什么意思
[AIGC] `InitializingBean`接口 的使用场景
swtich分支结构需要注意哪些事情
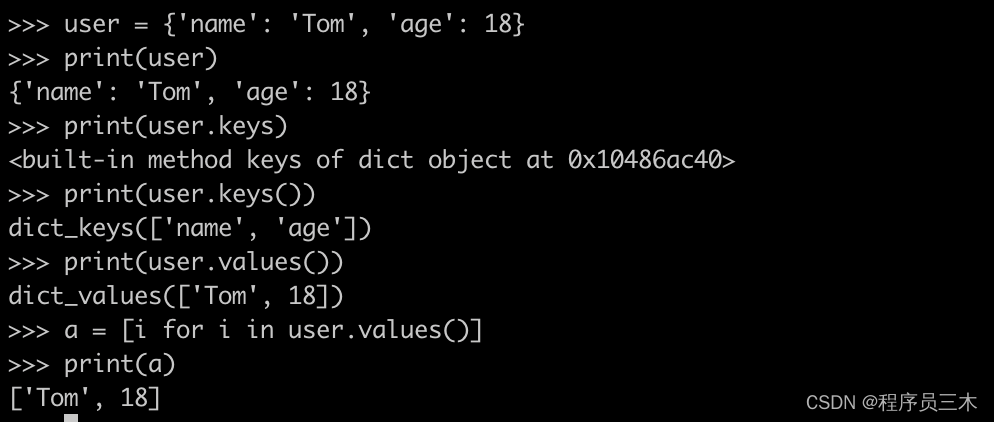
[AIGC] Python列表([])和字典({})常用API介绍
标识符是什么,Java中命名规则?
自动类型转换你忘记了吗?
[AIGC] Python字符串常用API介绍
为什么 如果栈不为空就是top >= 0
删除字符串中的所有相邻重复项
StringBuilder和StringBuffer区别是什么?
JavaSE&集合框架
报错permission.js:41 [Vue warn]: Property “showClose“ must be accessed with “$data.showClose“ because
@PostMapping 必须加上@RequestBody吗
[尚硅谷flink学习笔记] 实战案例TopN 问题
一篇文章概括!状态码分别是什么意思?
[AIGC] 使用Python刷LeetCode:常用API及技巧指南
双星号**什么作用?
@Configuration的作用
[AIGC] 分布式锁及其实现方式详解与Python代码示例
.env.development是什么
Golang深入浅出之-Go语言 defer、panic、recover:异常处理机制
[AIGC] 实现博客平台的推荐排行榜
[AIGC] MySQL连接查询全面解析
企业级Docker镜像仓库Harbor部署与使用
[AIGC] Spring Interceptor 的执行顺序是怎样的?
Golang深入浅出之-Go语言流程控制:if、switch、for循环详解
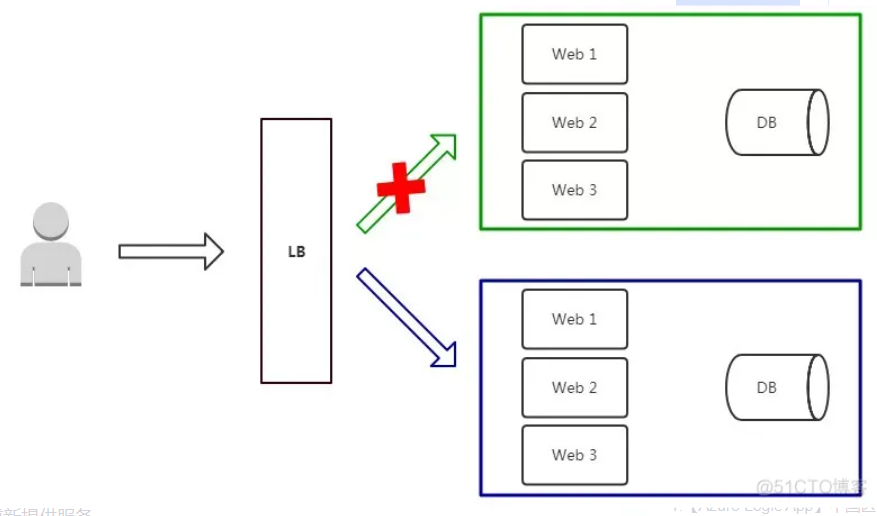
一文搞懂蓝绿发布、灰度发布和滚动发布
Golang深入浅出之-Go语言指针面试必知:理解与使用指针
[AIGC] Spring 获取前端请求参数的全面指南
微平均在云计算中的实践