利用MaxCompute,五叶草为某世界500强快消品零售巨头搭建了企业级数据仓库。由于部分子系统未打通、业务逻辑繁杂,客户的业务分析工作主要在线下人工完成,分析时间长、统计口径不一、数据质量参差不齐。在将数据存储在MaxCompute后,依托其强大的海量数据处理能力,原先需要花数小时更新的报表只在10分钟左右即可完成,有效降低了时间人力成本,提升了工作效率,使客户可以将更多的精力投入到业务升级中去。
在MaxCompute中我们定义了如下的各层数据模型:
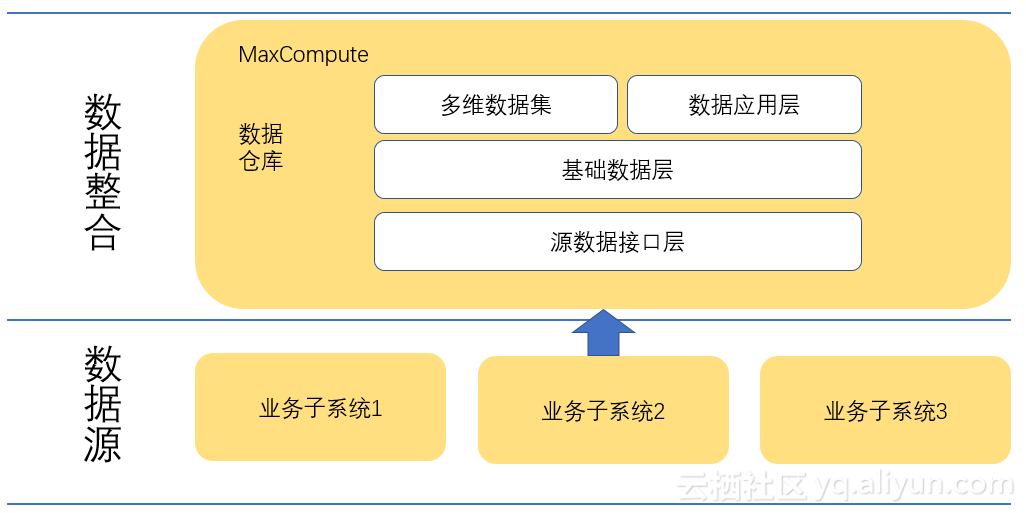
1. 数据接口层
数据接口层的数据结构应该对应源系统。应当注意的是同步的源数据要避免使用视图,在客户的生产环境上曾经出现过这样的情况:由于存储过程优化不好,同步视图在同步任务发起后仍然没有生成出来,导致同步任务及后续的ETL挂起。所以后续通过客户和第三方接洽,将数据源从视图换为表。
2. 基础数据层
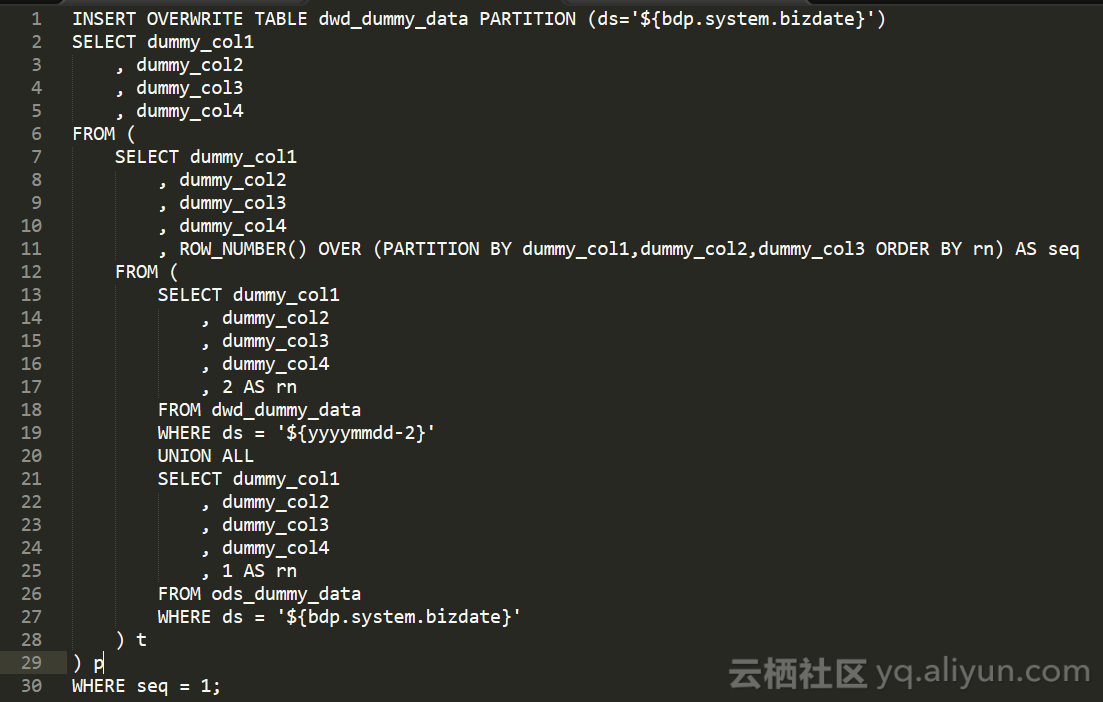
所有清洗、整合、运算工作应当放在基础数据层,避免对同步表里数据进行操作。以增量更新基础表为例,通过使用下面的方法,我们实现了每天增量更新数据到全量基础表的新分区,当天增量与昨天全量合并,数据存在冲突时优先保留增量记录
其中dwd_dummy_data为全量基础表,存放昨天的全量数据;ods_dummy_data为增量同步表,存放今天的增量数据。
由于数据更新之后插入了新分区,保留的基础表原始数据就为后面数据比对提供了极大的便利。客户部分数据源是由其他第三方维护的,出现过本月客户及该第三方协商对上月数据进行了修改,但是没有将该操作告知我们,最终导致上月月报结果与客户BI部门统计有出入。通过与客户提供的数据比对,我们发现了原始数据不一致的地方,我们在测试环境中对历史数据复现了相同的操作,并重跑了之后的任务,最终上月月报结果与客户BI部门结果一致。
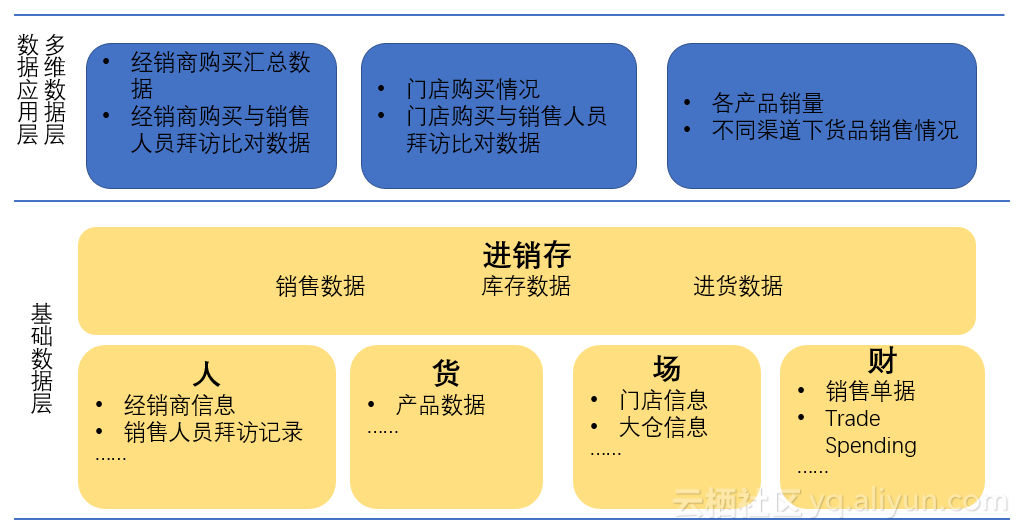
3. 多维数据层、数据应用层
在基础数据层,通过清洗、整合、运算得到的表为基本的维度表、事实表。需要面向业务,计算出业务指标后生成一张多维度表,并最终展现给客户。根据进销存、人货场财等分析思路,可以沿着某一方向深挖下去,下面展示了几张从人、场、货三个方向可以分析得出的多维度表,以及所需的基础数据。我们也在打通更多的数据通路