数学是计算机技术的基础,线性代数是机器学习和深度学习的基础,了解数据知识最好的方法我觉得是理解概念,数学不只是上学时用来考试的,也是工作中必不可少的基础知识,实际上有很多有趣的数学门类在学校里学不到,有很多拓展类的数据能让我们发散思维,但掌握最基本的数学知识是前提,本文就以线性代数的各种词条来做一下预热,不懂的记得百度一下。
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
矩阵与方程组
还记得n*n方程组是怎么求解的吗?这个术语叫“回代法”,即转成三角形方程组再挨个代入求解
一直不理解“代数”这个“代”是什么意思,现在终于理解了,代,英文是substitution,含义是代替,从初中到现在一直以为“代数”就是“代入”
系数矩阵,英文名叫coefficient matrix,怪不得读开源代码里面经常遇到变量名叫做coe,原来是从这来的
“导数”、“可导”还记得吗?不知道“导”是什么含义的有木有?英文derivative(含义是派生的、衍生的),看起来不是疏导的意思,而是音译过来的
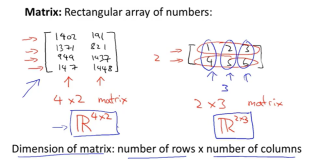
矩阵就是矩形的数字阵列,这再简单不过了
n*n的矩阵叫方阵,傻子都知道了
系数矩阵加一列右端项的矩阵叫增广矩阵,英文叫做augmented matrix,记作:(A|B),科学家们随便想个东西起个名字就让我们抱着书本啃,我把A后面放两个B,叫做“增广矩阵二”行吗
行阶梯型矩阵,这回有点难度了,它就是这样的:非零一行比一行少,第一个元素是1,数字靠右
高斯消元法:把增广矩阵化为行阶梯型矩阵
超定方程组:方程个数比未知量个数多
行最简形:行阶梯形,每行第一个非零元是该列唯一的非零元
高斯-若尔当消元法:将矩阵化为最简形的方法
齐次方程组(homogeneous):右端项全为零。齐次方程组总是有解的
平凡解,就是零解(0,0,0,.....0),能不能别这么平凡的叫....
非平凡解:零解以外的解
x上面加水平箭头表示水平数组(行向量),不加则表示列向量,不一样的书里记法不太一样,姑且这么记吧
对称矩阵的性质:转置等于他自己
若A=(1),则An=(2n-1)
如果AB=BA=I,则称A是可逆的,或A是非奇异的(nonsingular),B叫做A的逆元,记作A-1
矩阵没有乘法逆元,那么叫做奇异的(singlular)
(AB)-1=B-1A-1
(AB)T=BTAT
图的邻接矩阵(相连为1否则为0)是对称的
初等矩阵:乘到方程两端得到行阶梯形,初等矩阵是非奇异的,即有逆
如果B=多个初等矩阵连乘A,那么说A与B是行等价的
如果A与I行等价,那么Ax=0只有平凡解0,而且A有逆矩阵A-1,也就是A是非奇异的,此时Ax=b有唯一解
求逆的方法:对增广矩阵A|I做行列变换,把A变成I,则I变成了A-1
对角矩阵:对角线以外的元素都是0
如果A可以仅利用行运算化简为严格上三角形,则A有一LU分解,L是单位下三角矩阵,矩阵值就是变换中用的系数,这叫LU分解
矩阵分块后满足矩阵乘法规则
内积也叫标量积:行向量和列向量乘积,得出一个数
外积:列向量和行向量乘积,得出一个矩阵
外积展开:两个矩阵分别用向量方式表示,其乘积可以表示为外积展开
行列式
行列式:两条竖线间包括的阵列
每个方形矩阵可以和他的行列式对应,行列式数值说明方阵是否是奇异的
行列式算法:展开某一行,每个数乘以他的余子式并加和
如果行列式非0,则方形矩阵为非奇异
det(A)可表示为A的任何行或列的余子式展开
三角形矩阵的行列式等于对角元素乘积
交换矩阵两行,行列式变成原来的负数,即det(EA)=-det(A)
矩阵某行乘以a,行列式变成原来的a倍,即det(EA)=adet(A)
矩阵某行乘以a加到另一行,行列式不变
如果某行为另一行的倍数,则矩阵行列式为零
det(AB)=det(A)det(B)
adj A:矩阵的伴随(adjoint),将元素用余子式替换并转置
求逆方法:A-1=(1/det(A)) adj A,推导:A(adj A)=det(A)I所以A(((1/det(A)) adj A) = I
克拉黙法则:Ax=b的唯一解是xi=det(Ai)/det(A),这是线性方程组用行列式求解的便利方法
信息加密方法:找到行列式为正负1的整数矩阵A,A-1=+-adj A易求,乘A加密,乘A-1解密,A的构造方法:单位矩阵做初等变换
向量积也是一个向量
微积分中x看做行向量,线性代数中x看做列向量
假设x和y是行向量,则x*y=(x2y3-y2x3)i-(x1y3-y1x3)j+(x1y2-y1x2)k,其中i,j,k是单位矩阵的行向量
向量积可用于定义副法线方向
xT(xy)=yT(xy)=0,说明向量积与向量夹角为0
向量空间
向量空间:这个集合中满足加法和标量乘法运算,标量通常指实数
子空间:向量空间S的子集本身也是个向量空间,这个子集叫做子空间
除了{0}和向量空间本身外,其他子空间叫做真子空间,类似于真子集的概念,{0}叫做零子空间
Ax=0的解空间N(A)称为A的零空间,也就是说Ax=0线性方程组的解空间构成一个向量空间
向量空间V中多个向量的线性组合构成的集合成为这些向量的张成(span),记作span(v1,v2,...,vn)
span(e1,e2)为R3的一个子空间,从几何上表示为所有x1x2平面内3维空间的向量
span(e1,e2,e3)=R3
如果span(v1,v2,v3)=R3,那么说向量v1,v2,v3张成R3,{v1,v2,v3}是V的一个张集
最小张集是说里面没有多余的向量
最小张集的判断方法是:这些向量线性组合=0只有0解,这种情况也就是这些向量是线性无关的,如果有非零解那么就说是线性相关的
在几何上看二位向量线性相关等价于平行,三维向量线性相关等价于在同一个平面内
向量构成矩阵的行列式det(A)=0,则线性相关,否则线性无关
线性无关向量唯一地线性组合来表示任意向量
最小张集构成向量空间的基,{e1,e2...en}叫做标准基,基向量数目就是向量空间的维数
转移矩阵:把坐标从一组基到另一组基的变换矩阵
由A的行向量张成的R1*n子空间成为A的行空间,由A的列向量张成的Rm子空间成为A的列空间
A的行空间的维数成为A的秩(rank),求A的秩方法:把A化为行阶梯形,非零行个数就是秩
矩阵的零空间的维数成为矩阵的零度,一般秩和零度之和等于矩阵的列数
m*n矩阵行空间维数等于列空间的维数
线性变换
线性变换:L(av1+bv2)=aL(v1)+bL(v2)
线性算子:一个向量空间到其自身的线性变换
典型线性算子距离:ax(伸长或压缩a倍),x1e1(到x1轴的投影),(x1,-x2)T(关于x1轴作对称),(-x2,x1)T逆时针旋转90度
判断是不是线性变换,就看看这种变换能不能转化成一个m*n矩阵
线性变换L的核记为ker(L),表示线性变换后的向量空间中的0向量
子空间S的象记为L(S),表示子空间S上向量做L变换的值
整个向量空间的象L(V)成为L的值域
ker(L)为V的一个子空间,L(S)为W的一个子空间,其中L是V到W的线性变换,S是V的子空间
从以E为有序基的向量空间V到以F为有序基的向量空间W的线性变换的矩阵A叫做表示矩阵
B为L相应于[u1,u2]的表示矩阵,A为L相应于[e1,e2]的表示矩阵,U为从[u1,u2]到[e1,e2]的转移矩阵,则B=U-1AU
如果B=S-1AS,则称B相似于A
如果A和B为同一线性算子L的表示矩阵,则A和B是相似的
正交性
两个向量的标量积为零,则称他们正交(orthogonal)
R2或R3中的向量x和y之间的距离是:||x-y||
xTy=||x|| ||y|| cos θ,即cos θ=xTy / (||x|| ||y||)
设方向向量u=(1/||x||)x,v=(1/||y||)y,则cos θ=uTv,即夹角余弦等于单位向量的标量积
柯西-施瓦茨不等式:|xTy| <= ||x|| ||y||,当且仅当有0向量或成倍数关系时等号成立
标量投影:向量投影的长度,α=xTy/||y||
向量投影:p=(xTy/||y||)y=(xTy/yTy)y
对R3:||x*y|| = ||x|| ||y|| sinθ
当x和y正交时, ||x+y||2 = ||x||2 + ||y||2,叫毕达哥拉斯定律
c2=a2+b2叫毕达哥拉斯定理,其实就是勾股弦定理
余弦应用于判断相似程度
U为向量组成的矩阵,C=UTU对应每一行向量的标量积值,这个矩阵表示相关程度,即相关矩阵(correlation matrix),值为正就是正相关,值为负就是负相关,值为0就是不相关
协方差:x1和x2为两个集合相对平均值的偏差向量,协方差cov(X1,X2)=(x1Tx2)/(n-1)
协方差矩阵S=1/(n-1) XTX,矩阵的对角线元素为三个成绩集合的方差,非对角线元素为协方差
正交子空间:向量空间的两个子空间各取出一个向量都正交,则子空间正交。比如z轴子空间和xy平面子空间是正交的
子空间Y的正交补:是这样一个集合,集合中每个向量都和Y正交
正交补一定也是一个子空间
A的列空间R(A)就是A的值域,即Rn中的x向量,列空间中的b=Ax
R(AT)的正交空间是零空间N(A),也就是说A的列空间和A的零空间正交
S为Rn的一个子空间,则S的维数+S正交空间的维数=n
S为Rn的一个子空间,则S的正交空间的正交空间是他本身
最小二乘(least squares)用来拟合平面上的点集
最小二乘解为p=Ax最接近b的向量,向量p为b在R(A)上的投影
最小二乘解x的残差r(x)一定属于R(A)的正交空间
残差:r(x) = b - Ax
ATAx = ATb叫做正规方程组,它有唯一解x = (ATA)-1ATb,这就是最小二乘解,投影向量p=A(ATA)-1ATb为R(A)中的元素
插值多项式:不超过n次的多项式通过平面上n+1个点
一个定义了内积的向量空间成为内积空间
标量内积是Rn中的标准内积,加权求和也是一种内积
内积表示为,内积需满足: >= 0; =; =a+b
a=/||v||为u到v的标量投影
p=(/) v为u到v的向量投影
柯西-施瓦茨不等式:|| <= ||u|| ||v||
范数(norm):定义与向量相关联的实数||v||,满足||v||>=0; ||av||=|a| ||v||; ||v+w|| <= ||v|| + ||w||
||v|| = ()^-1为一个范数
||x||=sigma|xi|为一个范数
||x||=max|xi|为一个范数
一般地,范数给出了一种方法来度量两个向量的距离
v1,v2,...,vn如果相互之间=0,则{v1,v2,...,vn}成为向量的正交集
正交集中的向量都是线性无关的
规范正交的向量集合是单位向量的正交集,规范正交集中=1,里面的向量叫做规范正交基
正交矩阵:列向量构成规范正交基
矩阵Q是正交矩阵重要条件是QTQ=I,即Q-1=QT
乘以一个正交矩阵,内积保持不变,即=
乘以一个正交矩阵,仍保持向量长度,即||Qx||=||x||
置换矩阵:将单位矩阵的各列重新排列
如果A的列向量构成规范正交集,则最小二乘问题解为x=ATb
非零子空间S中向量b到S的投影p=UUTb,其中U为S的一组规范正交基,其中UUT为到S上的投影矩阵
使用不超过n次的多项式对连续函数进行逼近,可以用最小二乘逼近。
某取值范围内线性函数的子空间,内积形式是取值范围内对两个函数乘积做积分
通过将FN乘以向量z来计算离散傅里叶系数d的方法称为DFT算法(离散傅里叶变换)
FFT(快速傅里叶变换),利用矩阵分块,比离散傅里叶变换快8w多倍
格拉姆-施密特正交化过程:u1=(1/||x1||)x1, u2=(1/||x2-p1||) (x2-p1), .....直接求出一组规范正交基
格拉姆-施密特QR分解:m*n矩阵A如果秩为n,则A可以分解为QR,Q为列向量正交的矩阵,R为上三角矩阵,而且对角元素都为正,具体算法:
r11=||a1||,其中r11是对角矩阵第一列第一个元素,a1是A的列向量,
rkk=||ak-p(k-1)||, rik=qiTak, a1=r11q1
Ax=b的最小二乘解为x=R-1QTb,其中QR为因式分解矩阵,解x可用回代法求解Rx=QTb得到
使用多项式进行数据拟合以及逼近连续函数可通过选取逼近函数的一组正交基进行简化
多项式序列p0(x),p1(x),...下标就是最高次数,如果=0,则{pn(x)}成为正交多项式序列,如果=1,则叫规范正交多项式序列
经典正交多项式:勒让德多项式、切比雪夫多项式、雅克比多项式、艾尔米特多项式、拉盖尔多项式
勒让德多项式:在内积
=-1到1的积分p(x)q(x)dx意义下正交,(n+1)P(n+1)(x)=(2n+1)xPn(x)-nP(n-1)(x)
切比雪夫多项式:在内积
=-1到1的积分p(x)q(x)(1-x2)-1/2dx意义下正交,T1(x)=xT0(x), T(n+1)(x)=2xTn(x)-T(n-1)(x)
拉格朗日插值公式:P(x)=sigma f(xi) Li(x)
拉格朗日函数Li(x)=(x-xj)连乘积 / (xi-xj)连乘积
f(x)w(x)在a到b的积分可以简化为sigma Li(x)w(x)在a到b的积分 f(xi)
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
特征值
经过矩阵变换后向量保持不变,稳定后的向量叫做该过程的稳态向量
存在非零的x使得Ax=λx,则称λ为特征值,x为属于λ的特征向量。特征值就是一个缩放因子,表示线性变换这个算子的自然频率
子空间N(A-λI)称为对应特征值λ的特征空间
det(A-λI)=0称为矩阵A的特征方程,求解特征方程可以算出λ
λ1λ2...λn=det(A),即所有特征值的连乘积等于矩阵A的行列式的值
sigma λi = sigma aii,所有特征值的和等于矩阵对角线元素之和
A的对角线元素的和称为A的迹(trace),记为tr(A)
相似矩阵:B=S-1AS
相似矩阵具有相同的特征多项式,和相同的特征值
线性微分方程解法可以用特征值特征向量,形如Y'=AY, Y(0)=Y0的解是ae(λt)x,其中x是向量,这样的问题称为初值问题,如果有多个特征值,则解可以是多个ae(λt)x的线性组合
任意高阶微分方程都可以转化成一阶微分方程,一阶微分方程可以用特征值特征向量求解
矩阵A的不同特征值的特征向量线性无关
如果存在X使得X-1AX=D,D是对角矩阵,则说A是可对角化的,称X将A对角化,X叫做对角化矩阵
如果A有n个线性无关的特征向量,则A可对角化
对角化矩阵X的列向量就是A的特征向量,D的对角元素就是A的特征值,X和D都不是唯一的,乘以个标量,或重新排列,都是一个新的
An=XDnX-1,所以按A=XDX-1因式分解后,容易计算幂次
如果A有少于n个线性无关的特征向量,则称A为退化的(defective),退化矩阵不可对角化
特征值和特征向量的几何理解:矩阵A有特征值2,特征空间由e3张成,看成几何重数(geometric multiplicity)是1
矩阵B有特征值2,特征向量有两个x=(2,1,0)和e3,看成几何重数(geometric multiplicity)是2
随机过程:一个试验序列,每一步输出都取决于概率
马尔可夫过程:可能的输出集合或状态是有限的;下一步输出仅依赖前一步输出,概率相对于时间是常数
如果1为转移矩阵A的住特征值,则马尔可夫链将收敛到稳态向量
一个转移矩阵为A的马尔可夫过程,若A的某幂次的元素全为正的,则称其为正则的(regular)
PageRank算法可以看成浏览网页是马尔可夫过程,求稳态向量就得到每个网页的pagerank值
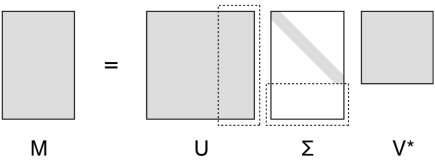
A的奇异值(singlular value)分解:把A分解为一个乘积UΣVT,其中U、V都是正交矩阵,Σ矩阵的对角线下所有元素为0,对角线元素逐个减小,对角线上的值叫奇异值
A的秩等于非零奇异值的个数
A的奇异值等于特征向量的开方
若A=UΣVT,那么上面ATuj=σjvj,下面ATuj=0,其中vj叫做A的右奇异向量,uj叫做左奇异向量
压缩形式的奇异值分解:U1=(u1,u2,...,ur), V1=(v1,v2,...,vr),A=U1Σ1V1T
奇异值分解解题过程:先算ATA的特征值,从而算出奇异值,同时算出特征向量,由特征向量得出正交矩阵V,求N(AT)的一组基并化成规范正交基,组成U,最终得出A=UΣVT
数值秩是在有限位精度计算中的秩,不是准确的秩,一般假设一个很小的epsilon值,如果奇异值小于它则认为是0,这样来计算数值秩
用来存储图像的矩阵做奇异值分解后去掉较小的奇异值得到更小秩的矩阵,实现压缩存储
信息检索中去掉小奇异值得到的近似矩阵可以大大提高检索效率,减小误差
二次型:每一个二次方程关联的向量函数f(x)=xTAx,即二次方程中ax2+2bxy+cy2部分
ax2+2bxy+cy2+dx+ey+f=0图形是一个圆锥曲线,如果没解则称为虚圆锥曲线,如果仅有一个点、直线、两条直线,则称为退化的圆锥曲线,非退化的圆锥曲线为圆、椭圆、抛物线、双曲线
一个关于x、y的二次方程可以写为xTAx+Bx+f=0,其中A为22对称,B为12矩阵,如果A是非奇异的,利用旋转和平移坐标轴,则可化简为λ1(x')2+λ2(y')2+f'=0,其中λ1和λ2为A的特征值。如果A是奇异的,且只有一个特征值为零,则化简为λ1(x')2+e'y'+f'=0或λ2(x')2+d'x'+f'=0
二次型f(x)=xTAx对于所有x都是一个符号,则称为定的(definite),若符号为正,则叫正定的(positive definite),相对应叫负定的(negative definite),如果符号有不同则叫不定的(indefinite),如果可能=0,则叫半正定的(positive semidefinite),和半负定的(negative semidefinite)
如果二次型正定则称A为正定的
一阶偏导存在且为0的点称为驻点,驻点是极小值点还是极大值点还是鞍点取决于A是正定负定还是不定
一个对称矩阵是正定的,当且仅当其所有特征值均为正的
r阶前主子矩阵:将n-r行和列删去得到的矩阵
如果A是一个对称正定矩阵,则A可分解为LDLT,其中L为下三角的,对角线上元素为1,D为对角矩阵,其对角元素均为正的
如果A是一个对称正定矩阵,则A可分解为LLT,其中L为下三角的,其对角线元素均为正
对称矩阵如下结论等价:A是正定的;前主子矩阵均为正定的;A可仅使用行运算化为上三角的,且主元全为正;A有一个楚列斯基分解LLT(其中L为下三角矩阵,其对角元素为正的);A可以分解为一个乘积BTB,其中B为某非奇异矩阵
非负矩阵:所有元素均大于等于0
一个非负矩阵A,若可将下标集{1,2,...,n}划分为非空不交集合I1和I2,使得当i属于I1而j属于I2中时,aij=0,则成其为可约的,否则为不可约的
数值线性代数
舍入误差(round off error):四舍五入后的浮点数x'和原始数x之间的差
绝对误差:x'-x
相对误差:(x'-x)/x,通常用符号δ表示,|δ|可以用一个正常数ε限制,称为机器精度(machine epsilon)
高斯消元法涉及最少的算术运算,因此被认为是最高效的计算方法
求解Ax=b步骤:将A乘以n个初等矩阵得到上三角矩阵U,把初等矩阵求逆相乘得到L,那么A=LU,其中L为下三角矩阵,一旦A化简为三角形式,LU分解就确定了,那么解方程如下:LUx=b,令y=Ux,则Ly=b,所以可以通过求下三角方程求得y,y求得后再求解Ux=y,即可求得x
矩阵的弗罗贝尼乌斯范数记作||·||F,求其所有元素平方和的平方根
若A的奇异值分解A=UΣVT,则||A||2=σ1(最大的奇异值)
矩阵范数可用于估计线性方程组对系数矩阵的微小变化的敏感性
将x'代回原方程组观察b'=Ax'和b的接近成都来检验精度,r=b-b'=b-Ax'叫做残差(residual),||r||/||b||叫做相对残差
奇异值为一个矩阵接近奇异程度的度量,矩阵越接近奇异就越病态
豪斯霍尔德变换(householder transformation)矩阵H可由向量v和标量β求得,因此存储v和β更省空间
主特征值是指最大的特征值
求主特征值的方法:幂法。
求特征值方法:QR算法。将A分解为乘积Q1R1,其中Q1为正交的,R1为上三角的,A2=Q1TAQ1=R1Q1,将A2分解为Q2R2,定义A3=Q2TA2Q2=R2Q2,继续这样,得到相似矩阵序列Ak=QkRk,最终将收敛到类似上三角矩阵,对角上是11或22的对角块,对角块的特征值就是A的特征值
最后的总结
奇异值分解正是对这种线性变换的一个析构,A=,和是两组正交单位向量,是对角阵,表示奇异值,它表示A矩阵的作用是将一个向量从这组正交基向量的空间旋转到这组正交基向量空间,并对每个方向进行了一定的缩放,缩放因子就是各个奇异值。如果维度比大,则表示还进行了投影。可以说奇异值分解描述了一个矩阵完整的功能/特性。
而特征值分解其实只描述了矩阵的部分功能。特征值,特征向量由Ax=x得到,它表示如果一个向量v处于A的特征向量方向,那么Av对v的线性变换作用只是一个缩放。也就是说,求特征向量和特征值的过程,我们找到了这样一些方向,在这些方向上矩阵A对向量的旋转、缩放变换(由于特征值只针对方阵,所以没有投影变换)在一定程度上抵消了,变成了存粹的缩放(这个缩放比例和奇异值分解中的缩放比例可能不一样)。
概括一下,特征值分解只告诉我们在特征向量的那个方向上,矩阵的线性变化作用相当于是简单的缩放,其他方向上则不清楚,所以我说它只表示矩阵的部分特性。而奇异值分解则将原先隐含在矩阵中的旋转、缩放、投影三种功能清楚地解析出来,表示出来了,它是对矩阵的一个完整特征剖析。