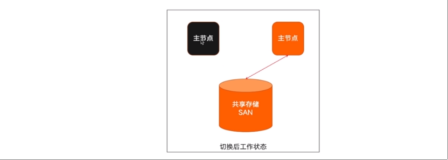
PostgreSQL9提供了一个非常兴奋的功能,hot-standby,功能与ORACLE 11G的ACTIVE STANDBY类似。并且增加了流复制的功能,这个与oracle 的standby redo log功能类似,大大的缩短了备份库与主库的事务间隔。
HOT-STANDBY可以提供容灾,恢复的同时可以把数据库打开,提供查询功能。以前的版本恢复的时候是不能打开的。
首先看一张postgreSQL的高可用,负载均衡,复制特征矩阵图

这里有一个很好的特性
| Slaves accept read-only queries |
下面是来自POSTGRESQL WIKI的文档,非常简单,这里就不作翻译了。
SR is being developed for inclusion in PostgreSQL 9.0 by NTT OSS Center. The lead developer is . Synchronous Log Shipping Replication Presentation introduces the early design of the feature.
Users Overview
- Log-shipping
- XLOG records generated in the primary are periodically shipped to the standby via the network.
- In the existing warm standby, only records in a filled file are shipped, what’s referred to as file-based log-shipping. In SR, XLOG records in partially-filled XLOG file are shipped too, implementing record-based log-shipping. This means the window for data loss in SR is usually smaller than in warm standby, unless the warm standby was also configured for record-based shipping (which is complicated to setup).
- The content of XLOG files written to the standby are exactly the same as those on the primary. XLOG files shipped can be used for a normal recovery and PITR.
- Multiple standbys
- More than one standby can establish a connection to the primary for SR. XLOG records are concurrently shipped to all these standbys. The delay/death of a standby does not harm log-shipping to other standbys.
- The maximum number of standbys can be specified as a GUC variable.
- Continuous recovery
- The standby continuously replays XLOG records shipped without using pg_standby.
- XLOG records shipped are replayed as soon as possible without waiting until XLOG file has been filled. The combination of Hot Standby and SR would make the latest data inserted into the primary visible in the standby almost immediately.
- The standby periodically removes old XLOG files which are no longer needed for recovery, to prevent excessive disk usage.
- Setup
- The start of log-shipping does not interfere with any query processing on the primary.
- The standby can be started in various conditions.
- If there are XLOG files in archive directory and restore_command is supplied, at first those files are replayed. Then the standby requests XLOG records following the last applied one to the primary. This prevents XLOG files already present in the standby from being shipped again. Similarly, XLOG files in pg_xlog are also replayed before starting log-shipping.
- If there is no XLOG files on the standby, the standby requests XLOG records following the starting XLOG location of recovery (the redo starting location).
- Connection settings and authentication
- A user can configure the same settings as a normal connection to a connection for SR (e.g., keepalive, pg_hba.conf).
- Activation
- The standby can keep waiting for activation as long as a user likes. This prevents the standby from being automatically brought up by failure of recovery or network outage.
- Progress report
- The primary and standby report the progress of log-shipping in PS display.
- Graceful shutdown
- When smart/fast shutdown is requested, the primary waits to exit until XLOG records have been sent to the standby, up to the shutdown checkpoint record.
Restrictions
- Synchronous log-shipping
- Currently SR supports only asynchronous log-shipping. The commit command might return a “success” to a client before the corresponding XLOG records are shipped to the standby.
- Replication beyond timeline
- A user has to get a fresh backup whenever making the old standby catch up.
- Clustering
- Postgres doesn’t provide any clustering feature.
How to Use
- 1. Install postgres in the primary and standby server as usual. This requires only configure, makeand make install.
- 2. Create the initial database cluster in the primary server as usual, using initdb.
- 3. Set up connections and authentication so that the standby server can successfully connect to the replication pseudo-database on the primary.
$ $EDITOR postgresql.conflisten_addresses = '192.168.0.10'$ $EDITOR pg_hba.conf# The standby server must have superuser access privileges.host replication postgres 192.168.0.20/22 trust
- 4. Set up the streaming replication related parameters on the primary server.
$ $EDITOR postgresql.conf# To enable read-only queries on a standby server, wal_level must be set to# "hot_standby". But you can choose "archive" if you never connect to the# server in standby mode.wal_level = hot_standby# Set the maximum number of concurrent connections from the standby servers.max_wal_senders = 5# To prevent the primary server from removing the WAL segments required for# the standby server before shipping them, set the minimum number of segments# retained in the pg_xlog directory. At least wal_keep_segments should be# larger than the number of segments generated between the beginning of# online-backup and the startup of streaming replication. If you enable WAL# archiving to an archive directory accessible from the standby, this may# not be necessary.wal_keep_segments = 32# Enable WAL archiving on the primary to an archive directory accessible from# the standby. If wal_keep_segments is a high enough number to retain the WAL# segments required for the standby server, this may not be necessary.archive_mode = onarchive_command = 'cp %p /path_to/archive/%f'
- 5. Start postgres on the primary server.
- 6. Make a base backup by copying the primary server’s data directory to the standby server.
$ psql -c "SELECT pg_start_backup('label', true)"$ rsync -a ${PGDATA}/ standby:/srv/pgsql/standby/ --exclude postmaster.pid$ psql -c "SELECT pg_stop_backup()"
- 7. Set up replication-related parameters, connections and authentication in the standby server like the primary, so that the standby might work as a primary after failover.
- 8. Enable read-only queries on the standby server. But if wal_level is archive on the primary, leave hot_standby unchanged (i.e., off).
$ $EDITOR postgresql.confhot_standby = on
- 9. Create a recovery command file in the standby server; the following parameters are required for streaming replication.
$ $EDITOR recovery.conf# Specifies whether to start the server as a standby. In streaming replication,# this parameter must to be set to on.standby_mode = 'on'# Specifies a connection string which is used for the standby server to connect# with the primary.primary_conninfo = 'host=192.168.0.10 port=5432 user=postgres'# Specifies a trigger file whose presence should cause streaming replication to# end (i.e., failover).trigger_file = '/path_to/trigger'# Specifies a command to load archive segments from the WAL archive. If# wal_keep_segments is a high enough number to retain the WAL segments# required for the standby server, this may not be necessary. But# a large workload can cause segments to be recycled before the standby# is fully synchronized, requiring you to start again from a new base backup.restore_command = 'cp /path_to/archive/%f "%p"'
- 10. Start postgres in the standby server. It will start streaming replication.
- 11. You can check the progress of streaming replication by using ps command.
# The displayed LSNs indicate the byte position that the standby server has# written up to in the xlogs.[primary] $ ps -ef | grep senderpostgres 6879 6831 0 10:31 ? 00:00:00 postgres: wal sender process postgres 127.0.0.1(44663) streaming 0/2000000[standby] $ ps -ef | grep receiverpostgres 6878 6872 1 10:31 ? 00:00:01 postgres: wal receiver process streaming 0/2000000
- How to do failover
- Create the trigger file in the standby after the primary fails.
- How to stop the primary or the standby server
- Shut down it as usual (pg_ctl stop).
- How to restart streaming replication after failover
- Repeat the operations from 6th; making a fresh backup, some configurations and starting the original primary as the standby. The primary server doesn’t need to be stopped during these operations.
- How to restart streaming replication after the standby fails
- Restart postgres in the standby server after eliminating the cause of failure.
- How to disconnect the standby from the primary
- Create the trigger file in the standby while the primary is running. Then the standby would be brought up.
- How to re-synchronize the stand-alone standby after isolation
- Shut down the standby as usual. And repeat the operations from 6th.
1. 《PostgreSQL 9.1 Allow standby recovery to switch to a new timeline automatically》
http://blog.163.com/digoal@126/blog/static/163877040201182395310376/
2. 《PostgreSQL 9.2 devel adding cascading replication support》
http://blog.163.com/digoal@126/blog/static/1638770402012012361519/
3. 《PostgreSQL HOT STANDBY using Stream》
http://blog.163.com/digoal@126/blog/static/16387704020110442050808/
4. 《PostgreSQL cluster role switchover between primary and standby》
http://blog.163.com/digoal@126/blog/static/163877040201141154024306/
5. 《We can ignore the performance influence when use sync replication in PostgreSQL 9.1》
http://blog.163.com/digoal@126/blog/static/163877040201192203458765/
6. 《PostgreSQL 9.1 Replication role privilege change to REPLICATION from SUPERUSER》
http://blog.163.com/digoal@126/blog/static/16387704020114112379185/
7. 《PostgreSQL 9.0.2 Replication Best Practices》
http://blog.163.com/digoal@126/blog/static/1638770402010113034232645/
8. 《PostgreSQL replication monitor》
http://blog.163.com/digoal@126/blog/static/163877040201141134748660/
9. 《New replication mode: async, write, fsync, replay》
http://blog.163.com/digoal@126/blog/static/16387704020121231117557/
10. 《PostgreSQL HOT STANDBY using log shipping》
http://blog.163.com/digoal@126/blog/static/1638770402010113053825671/