今天一位QQ群里的网友说PostgreSQL支持级联复制。我一开始表示怀疑,后来查到9.2的手册里确实有级联复制的说明,于是把9.2的开发版本下载过来测试了一下,以下是测试过程。
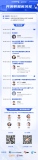
 主节点在杭州IDC,
主节点在杭州IDC,
测试环境如图 :
第一个standby 节点在北京1号机房
第二个和第三个standby 节点在北京的2号机房。
这样做的好处是节约了跨地域复制的带宽,9.1和9.0的版本三个standby都需要直连到master节点进行复制。而9.2的standby节点可以同时启用walreceiver和walsender进程,也就是说支持向下发送流数据。
从TOP输出的结果也可以验证, 如下是其中的一个级联standby节点的top截取 :
说明它的下面还有一个standby, IP地址是172.16.3.150
配置方面和9.1差不多,来看看主节点的配置文件 :
349 pg92 15 0 1231m 2852 1612 S 0.0 0.0 0:00.38 postgres: wal receiver process streaming 0/8000078 362 pg92 15 0 1225m 2692 1328 S 0.0 0.0 0:00.08 postgres: wal sender process replica 172.16.3.150(26943) streaming 0/80配置方面和9.1差不多,来看看主节点的配置文件 :
# REPLICATION
#------------------------------------------------------------------------------
# - Sending Server(s) -
# Set these on the master and on any standby that will send replication data
max_wal_senders = 64 # max number of walsender processes
# (change requires restart)
wal_keep_segments = 64 # in logfile segments, 16MB each; 0 disables
#replication_timeout = 60s # in milliseconds; 0 disables
# - Master Server -
# These settings are ignored on a standby server
#synchronous_standby_names = '' # standby servers that provide sync rep
# comma-separated list of application_name
# from standby(s); '*' = all
#vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed
# - Standby Servers -
# These settings are ignored on a master server
hot_standby = on # "on" allows queries during recovery
# (change requires restart)
#max_standby_archive_delay = 30s # max delay before canceling queries
# when reading WAL from archive;
# -1 allows indefinite delay
#max_standby_streaming_delay = 30s # max delay before canceling queries
# when reading streaming WAL;
# -1 allows indefinite delay
#wal_receiver_status_interval = 10s # send replies at least this often
# 0 disables
hot_standby_feedback = on # send info from standby to prevent
# query conflicts
与9.1相比少了wal_sender_delay参数. 先不管, 9.2的手册上也没说为啥少了这个.
主节点上还需要新建一个replica角色用于复制 :
例如 :
接下来是standby1的配置 :
postgres=# create role replica nosuperuser nocreatedb nocreaterole noinherit login replication connection limit 64 encrypted password 'replica123';接下来是standby1的配置 :
postgresql.conf与主节点一致 .
新建一个~/.pgpass
新建recovery.conf
*:*:replication:replica:replica123
chmod 400 ~/.pgpass新建recovery.conf
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=172.16.3.33 port=1919 user=replica keepalives_idle=60' # e.g. 'host=localhost port=5432'
trigger_file = '/pgdata1919/.trigger.1919.pg92'
然后是新建standby1节点 :
新建PGDATA目录并修改目录权限为700, 然后
接下来是standby2的配置 :
pg_basebackup -D $PGDATA -F p -P -v -h 172.16.3.33 -p 1919 -U replica
pg_ctl start -D $PGDATA接下来是standby2的配置 :
postgresql.conf与主节点一致 .
新建一个~/.pgpass
新建recovery.conf
*:*:replication:replica:replica123
chmod 400 ~/.pgpass新建recovery.conf
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=172.16.3.39 port=1919 user=replica keepalives_idle=60' # e.g. 'host=localhost port=5432'
trigger_file = '/pgdata1919/.trigger.1919.pg92'
然后是新建standby1节点 :
新建PGDATA目录并修改目录权限为700, 然后
(值得一提的是, pg_basebackup需要在主库上获得一个start backup的标签, 所以必须连到master操作. )
(如果数据库很大的话,可以考虑关闭某个standby节点, 直接复制standby的数据过去来建立基准库)
接下来是standby2的配置 :
pg_basebackup -D $PGDATA -F p -P -v -h 172.16.3.33 -p 1919 -U replica
pg_ctl start -D $PGDATA接下来是standby2的配置 :
postgresql.conf与主节点一致 .
新建一个~/.pgpass
新建recovery.conf
*:*:replication:replica:replica123
chmod 400 ~/.pgpass新建recovery.conf
recovery_target_timeline = 'latest'
standby_mode = on
primary_conninfo = 'host=172.16.3.40 port=1919 user=replica keepalives_idle=60' # e.g. 'host=localhost port=5432'
trigger_file = '/pgdata1919/.trigger.1919.pg92'
然后是新建standby1节点 :
新建PGDATA目录并修改目录权限为700, 然后
(值得一提的是, pg_basebackup需要在主库上获得一个start backup的标签, 所以必须连到master操作. )
(如果数据库很大的话,可以考虑关闭某个standby节点, 直接复制standby的数据过去来建立基准库)
至此,整个环境都搭建好了。
pg_basebackup -D $PGDATA -F p -P -v -h 172.16.3.33 -p 1919 -U replica
pg_ctl start -D $PGDATA至此,整个环境都搭建好了。
在主库新建一个测试表看看standby3会不会复制过去,
连接到standby3 , 数据已经复制过去了。
【注意】
postgres=# create table cascading_test (id int,info text);
CREATE TABLE
postgres=# insert into cascading_test select generate_series(1,10000),'digoal';
INSERT 0 10000连接到standby3 , 数据已经复制过去了。
pg92@db-172-16-3-150-> psql -h 127.0.0.1 -p 1919 -U pg92 postgres
psql (9.2devel)
Type "help" for help.
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------------+-------+-------
public | cascading_test | table | pg92
public | test | table | pg92
(2 rows)
postgres=# select count(*) from cascading_test ;
count
-------
10000
(1 row)【注意】
1. 如果在环境中配置了同步流复制,那么同步流复制的备选standby节点中只会选择直连master的节点,级联节点不在备选的角色中,如本例中只有standby1会成为备选角色。
例如我们把master的配置文件修改一下,
通过查看master的视图可以看出这一点 :
synchronous_standby_names = '*'通过查看master的视图可以看出这一点 :
postgres=# select * from pg_stat_replication;
procpid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | s
tate | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
---------+----------+---------+------------------+-------------+-----------------+-------------+-------------------------------+----
-------+---------------+----------------+----------------+-----------------+---------------+------------
14977 | 16384 | replica | walreceiver | 172.16.3.39 | | 38560 | 2012-01-12 16:09:18.166834+08 | str
eaming | 0/70CEC08 | 0/70CEC08 | 0/70CEC08 | 0/70CEC08 | 1 | sync
(1 row)
同时, sync_state也不会传递, 如master配置了synchronous_standby_names = '*', standby1也配置了synchronous_standby_names = '*'
那么standby2会不会是
sync_state = sync的呢?答案是不会. 因为同步止于与master节点直连的节点。
2. 不管是同步还是异步复制,在pg_stat_replication视图中都只能看到与之直连的standby的信息。
例如在本例中的MASTER节点查看
pg_stat_replication视图的时候,只能查看到与之直连的standby1的信息。
在standby1节点查看
pg_stat_replication的信息也只能查看到与之直连的standby2节点的信息。
【小结】
级联复制非常在异地建立多个STANDBY的环境. 可以大大降低网络带宽的开销。
同时级联复制还可以降低主库对网络带宽的需求,因为9.1和9.0的版本如果standby很多或者pg_xlog生成很频繁的话,主库的网络开销很快就会成为瓶颈。