本文依据盘古团队的吴洋分享了《盘古:飞天分布式存储系统实践》视频整理而成。
他主要从以下三个方面进行了分享:盘古是什么?盘古是用来解决什么问题的?盘古是怎么解决问题的?他主要介绍了盘古的分布式系统架构和设计理念。

上图列举了目前主流的云计算厂商,我们发现一个很有趣的事情:所有云计算厂商都是“富二代”,它们的分布式存储技术全部采用自研技术,而没有用大家耳熟能详的开源分布式系统。
飞天梦
第一代飞天人的梦想是在大量廉价的PC服务器上,对外提供各种计算和存储服务。具体到以下几个组件:夸父,主要负责网络;女娲,主要负责协同;伏羲,主要负责调度;盘古,主要负责存储;神农,主要负责监控。
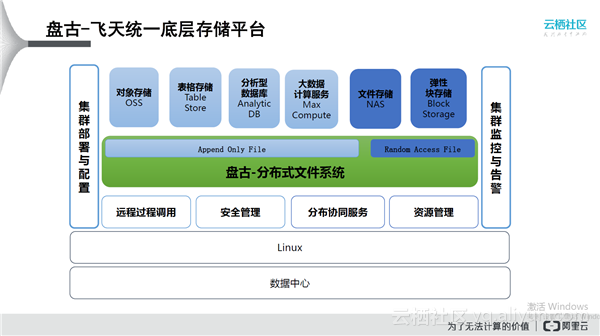
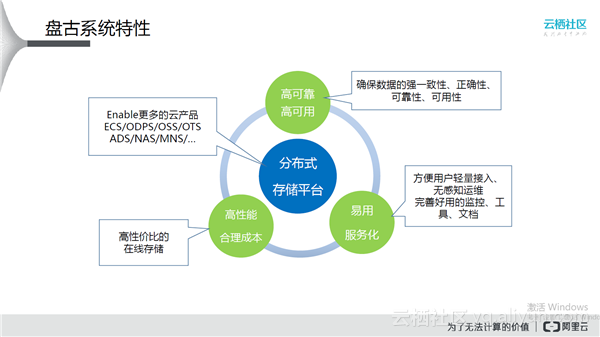
上图介绍了盘古的底层存储平台,其承担承上启下的作用。盘古作为分布式存储系统,主要提供两种类型的接口:Append Only接口,Random Access接口。
盘古是用来解决什么问题的?
单机的硬件或者系统总是不完美的,总是会小概率的出错,但是它又需要具有大规模下水平扩展的能力,因为它要管理大量的机器。这两个层面放在一起意味着出错是常态。
大规模下,小概率事件是常态
- 4%磁盘年损坏率,1%%机器日宕机率
- Raid卡崩溃、电容充放电导致write back模式变成write through
- 网络分割、交换机丢包、升级重启、光纤损坏带宽降低90%、两地机房路由错误
- 机架断电、整个机房掉电
- 网卡TCP校验出错,磁盘访问数据校验出错
- NTP时间漂移、内核IO线程D状态、dirty page cache无法写回
- 系统热点无时不在,瞬时转移
- 程序缺陷导致资源泄露、创建大量文件、访问脏数据
- 误操作:误删数据、拔错磁盘、没有清理测试机器环境上线……
盘古面临的问题和挑战
从上图可以看到,作为统一存储,要支持虚拟机中的块存储,对象存储,表格存储,文件存储,离线大数据处理,大数据分析等诸多业务,其面临的挑战是很大的,甚至有些挑战是自相矛盾的。
盘古是怎么解决问题的?
盘古在系统设计的时候进行了一些取舍。首先盘古使能了更多的云产品,让云产品去对接用户,这样就可以集中精力打造一个稳定可靠的分布式存储平台。高可靠、高可用是不能妥协的部分,在任何情况下要保证数据的强一致性、正确性、可靠性、可用性。有的时候追求低成本会威胁到高可用,所以要做到高性能、合理成本,提供高性价比的在线存储。易用、服务化,方便用户轻量接入、无感知运维完善好用的监控、工具、文档。
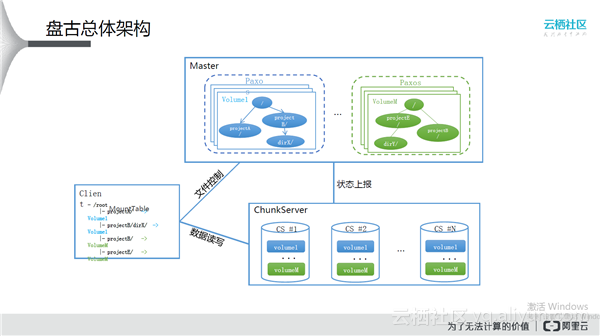
盘古总体架构
分为三个部分:Client,Master,ChunkServer。需要发起一次写入的时候,Client向Master创建一个文件,并且打开这个文件,此时Master会选好三个副本的位置反馈给Client。Client根据三个副本的位置找到ChunkServer,把数据写进去。也就是说,Client做整体的控制,Master提供源数据的存储,ChunkServer提供数据的存储。系统中的单点是非常脆弱的,如何保证其高可用?盘古的第一步是加入一个Paxos,也就是说用很多台Master组成一个group来实现高可用。即使用很多台服务器来实现高可用,最终对外服务的只能是一台服务器,当内存数据足够多的时候,就需要水平扩展。MountTable可以把目录树划分成volume,通过不同的volume就可以实现Master的水平扩展。
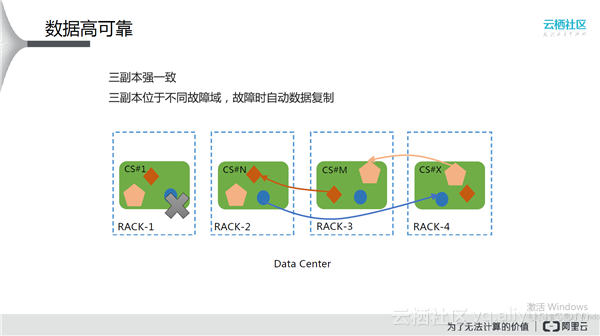
数据高可靠
盘古三副本强一致,三副本位于不同的故障域,故障时自动数据复制。如上图所示,一个数据中心有3份数据存放在4个RACK中,如果RACK-1突然断电或者网络有问题。此时,比如菱形的数据原来在RACK-3、RACK-4上,当RACK-1的菱形数据丢失时,盘古会通过高效的算法从RACK-3上复制一份出来放入RACK-2,保证了数据的安全可靠。
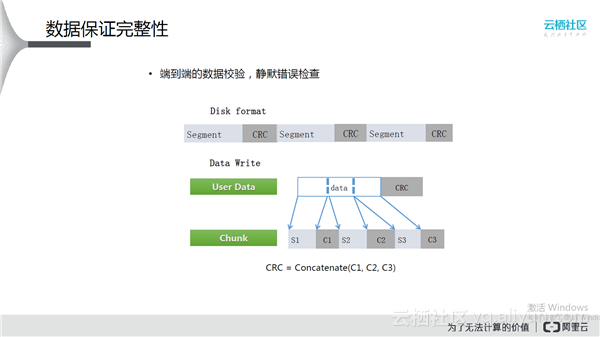
数据保证完整性
盘古主要做了两件事:端到端的数据校验,静默错误检查。在小概率下,内存存储的数据是可能发生变化的,磁盘上存储的数据也会发生变化。每段数据后面都有CRC,这样,一旦写入磁盘,数据和CRC是能够匹配上的,后台周期性扫描,发现数据和CRC不匹配时就判定这段数据发生了位反转,那么用其他好的副本将其覆盖。
合理成本
盘古进行了合理成本的优化。比如,线下运行的单集群有上万台,数百PB的数据。单组Master也进行了优化,读能达到15W QPS,写能达到5W QPS。单数据节点进行了软件栈极限优化,使得软件的消耗非常低,并且分层存储。最后,为了实现低成本,使用了普通PC服务器、Erasure Code。
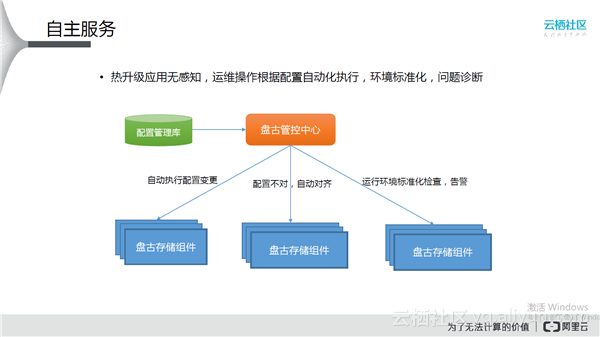
自主服务
运维是非常重要的,盘古实现了热升级应用无感知,运维操作根据配置自动化执行,不需要人工干预,通过环境标准化及时纠正,通过问题诊断自我解决问题。结构如上图所示,有一个集中管理的配置管理库,盘古管控中心会把配置管理库推送到盘古的各个组件,自动执行配置变更,发现配置不对时能够实现自动对齐,运行环境标准化检查对于大规模的分布式系统是非常重要的。
面向容错的设计
分布式系统的核心是面向容错的设计:
- 数据安全是一种信仰:E2E Checksum;后台静默扫描;系统bug,硬件故障,运维操作的容错。大规模的系统中,总会遇到各种各样的问题,当这些问题搅在一起时就会变得非常棘手。
- 环境检查排除隐患:磁盘分区;机架分布;配置错误;软件错误;硬件错误。
- 单机失效无感知:数据复制保证安全;换机器重试保证读写成功;记忆并规避故障机器。
- 监控+自愈:Master自我健康检查进行切换;Chunkserver发现故障磁盘或机器进行隔离;Client检测服务状况进行Master切换;Client自我健康检测并汇报状态。
以上的设计大大减小了运维的压力。
Master
Master需要解决的主要是三类问题:大容量、高效、稳定。大容量是指:Federation水平扩展,内存紧致排列单组支持8亿文件,读写OPS 100K/s。高效意味着最优的算法,硬件错误触发快速复制保证数据安全,数据流量动态规划实现最大吞吐,安全域动态调整保证数据高可用。稳定即Paxos数据一致、防止单点,多角度监控自动触发切换,多用户隔离防打死。由于盘古是多租户的系统,比如一万台的集群上面会跑着各种各样的应用,其相互之间是不知道的,但是它们在共用一个Master机器。如果一个用户大量访问Master,这时整个集群都不能提供对外服务,怎么杜绝这种情况?盘古做了多重隔离解决了上述问题。
Chunkserver
Chunkserver面临的问题是:闪存的价格高,IOPS高;机械硬盘价格低,IOPS低;只写入内存的方案掉电会丢失数据。如果整个集群都掉电,那么内存中还没写入数据就会丢掉,如果三份备份数据都丢掉,这对云计算是不能接受的事情。怎么结合闪存、机械式硬盘以最低的成本解决上述问题?有些解决方案使用UPS,但是UPS也存在不可靠问题,数据仍然会丢失。所以,最终的解决方案是使用少量的缓存搭配大量的机械硬盘,数据前台先写入缓存,后台将其转储到机械式硬盘。
Client
Client面临很多问题,很多现在的编程语言中,协程是非常普及的事情。传统的多线程编程中,多核系统上线程较多时,切换代价非常高,高性能的程序无法容忍这一点。有些解决方案是异步的编程,这样就使用少数的线程、不切线程。怎么样既有同步编程的便利,又有异步编程的性能?协程就是解决方案,很多现在的编程语言本身已经提供了协程,但是C++没有提供协程,所以盘古自己通过实现协程获得了高性能。Client面临的问题是:有些用户需要极致的性能,有些用户需要编程的简便,已有的海量程序要无缝支持。解决上述问题的方案是使用线程同步原语同时支持协程和非协程用户。在协程中是不切线程的,所以意味着所有的Task都在一个线程中执行,如果任何一个Task有阻塞操作,都会导致整个线程吞吐率的降低。