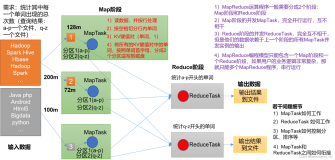
引言
借年底盛宴品鉴之风,继续抒我Hadoop之情,本篇
文章介绍如何对Hadoop的MapReduce进行
单元测试。MapReduce的开发周期差不多是这样:编写mapper和reducer、编译、打包、提交作业和结果检索等,这个过程比较繁琐,一旦提交到分布式环境出了问题要定位调试,重复这样的过程实在无趣,因此先对MapReduce做单元测试,消除明显的代码bug尤为必要。
MRUnit简介
MRUnit是一款由Couldera公司开发的专门针对Hadoop中编写MapReduce单元测试的框架。可以用MapDriver单独测试Map,用ReduceDriver单独测试Reduce,用MapReduceDriver测试MapReduce作业。
实战
我们将利用MRUnit对本系列上篇文章MapReduce基本编程中的字数统计功能进行单元测试。
· 加入MRUnit依赖
|
<dependency>
<groupId>com.cloudera.hadoop</groupId>
<artifactId>hadoop-mrunit</artifactId>
<version>0.20.2-320</version>
<scope>test</scope>
</dependency>
|
· 单独测试Map
|
public class WordCountMapperTest {
private Mappermapper;
private MapDriverdriver;
@Before
public voidinit(){
mapper = newWordCountMapper();
driver = newMapDriver(mapper);
}
@Test
public voidtest() throws IOException{
String line ="Taobao is a great website";
driver.withInput(null,newText(line))
.withOutput(newText("Taobao"),new IntWritable(1))
.withOutput(newText("is"), new IntWritable(1))
.withOutput(newText("a"), new IntWritable(1))
.withOutput(newText("great"), new IntWritable(1))
.withOutput(newText("website"), new IntWritable(1))
.runTest();
}
}
|
上面的例子通过MapDriver的withInput和withOutput组织map函数的输入键值和期待的输出键值,通过runTest方法运行作业,测试Map函数。测试运行通过。
· 单独测试Reduce
|
public class WordCountReducerTest {
private Reducerreducer;
privateReduceDriver driver;
@Before
public voidinit(){
reducer = newWordCountReducer();
driver = newReduceDriver(reducer);
}
@Test
public voidtest() throws IOException{
String key ="taobao";
List values =new ArrayList();
values.add(newIntWritable(2));
values.add(newIntWritable(3));
driver.withInput(new Text("taobao"), values)
.withOutput(new Text("taobao"), new IntWritable(5))
.runTest();
}
}
|
因为reduce函数实现相加功能,因此我们假设输入为<taobao,[2,3]>,
则期待结果应该为<taobao,5>.测试运行通过。
· 测试MapReduce
|
public class WordCountTest {
private Mapper mapper;
private Reducer reducer;
private MapReduceDriver driver;
@Before
public void init(){
mapper = new WordCountMapper();
reducer = new WordCountReducer();
driver = new MapReduceDriver(mapper,reducer);
}
@Test
public void test() throws RuntimeException, IOException{
String line = "Taobao is a great website, is it not?";
driver.withInput("",new Text(line))
.withOutput(new Text("Taobao"),new IntWritable(1))
.withOutput(new Text("a"),new IntWritable(1))
.withOutput(new Text("great"),new IntWritable(1))
.withOutput(new Text("is"),new IntWritable(2))
.withOutput(new Text("it"),new IntWritable(1))
.withOutput(new Text("not"),new IntWritable(1))
.withOutput(new Text("website"),new IntWritable(1))
.runTest();
}
}
|
这次我们测试MapReduce的作业,通过MapReduceDriver的withInput构造map函数的输入键值,通过withOutput构造reduce函数的输出键值。来测试这个字数统计功能,这次运行测试时抛出了异常,测试没有通过但没有详细junit异常信息,在控制台显示
2010-11-5 11:14:08org.apache.hadoop.mrunit.TestDriver lookupExpectedValue严重:Received unexpectedoutput (not?, 1)
2010-11-5 11:14:08org.apache.hadoop.mrunit.TestDriver lookupExpectedValue严重: Received unexpectedoutput (website,, 1)
2010-11-5 11:14:08org.apache.hadoop.mrunit.TestDriver validate严重:Missing expected output (not, 1) atposition 5
2010-11-5 11:14:08org.apache.hadoop.mrunit.TestDriver validate严重:Missing expected output (website, 1)at position 6
看样子是那里出了问题,不过看控制台日志不是很直观,因此我们修改测试代码,不调用runTest方法,而是调用run方法获取输出结果,再跟期待结果相比较,mrunit提供了org.apache.hadoop.mrunit.testutil.ExtendedAssert.assertListEquals辅助类来断言输出结果。
重构后的测试代码
|
@Test
public void test() throws RuntimeException, IOException{
String line = "Taobao is a great website, is it not?";
List<Pair> out = null;
out = driver.withInput("",new Text(line)).run();
List<Pair> expected = new ArrayList<Pair>();
expected.add(new Pair(new Text("Taobao"),new IntWritable(1)));
expected.add(new Pair(new Text("a"),new IntWritable(1)));
expected.add(new Pair(new Text("great"),new IntWritable(1)));
expected.add(new Pair(new Text("is"),new IntWritable(2)));
expected.add(new Pair(new Text("it"),new IntWritable(1)));
expected.add(new Pair(new Text("not"),new IntWritable(1)));
expected.add(new Pair(new Text("website"),new IntWritable(1)));
assertListEquals(expected, out);
}
|
再次运行,测试不通过,但有了明确的断言信息,
java.lang.AssertionError:Expected element (not, 1) at index 5 != actual element (not?, 1)
断言显示实际输出的结果为"not?"不是我们期待的"not",为什么?检查Map函数,发现程序以空格为分隔符未考虑到标点符号的情况,哈哈,发现一个bug,赶紧修改吧。这个问题也反映了单元测试的重要性,想想看,如果是一个更加复杂的运算,不做单元测试直接放到分布式集群中去运行,当结果不符时就没这么容易定位出问题了。
小结
用MRUnit做单元测试可以归纳为以下几点:用MapDriver单独测试Map,用ReduceDriver单独测试Reduce,用MapReduceDriver测试MapReduce作业;不建议调用runTest方法,建议调用run方法获取输出结果,再跟期待结果相比较;对结果的断言可以借助org.apache.hadoop.mrunit.testutil.ExtendedAssert.assertListEquals。
如果你能坚持看到这里,我非常高兴,但我打赌,你肯定对前面大片的代码匆匆一瞥而过,这也正常,不是每个人都对测试实战的代码感兴趣(或在具体需要时才感兴趣),为了感谢你的关注,我再分享一个小秘密:本篇讲的不仅仅是如何对MapReduce做单元测试,通过本篇测试代码的阅读,你可以更加深刻的理解MapReduce的原理(通过测试代码的输入和预期结果,你可以更加清楚地知道map、reduce究竟输入、输出了什么,对结果的排序在何处进行等细节)。
单元测试很必要,可以较早较容易地发现定位问题,但只有单元测试是不够的,我们需要对MapReduce进行集成测试,在运行集成测试之前,需要掌握如何将MapReduce 作业在hadoop集群中运行起来,本系列后面的文章将介绍这部分内容。
最新内容请见作者的GitHub页:http://qaseven.github.io/