摘要
利用systemtap脚本分析系统中dentry SLAB占用过高问题
原创文章:来自systemtap脚本分析系统中dentry SLAB占用过高问题
背景
长时间运行着的tengine主机有内存占用75%以上的报警.
操作系统版本: 2.6.32.el6.x86_64
原因定位
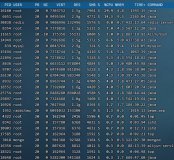
收集内存使用的相关信息如下:
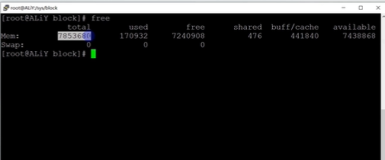
因内存占用率报警mem:76.28%先看一下内存的总体使用状况,从下图中可以看出used占用较高,buffers/cached占用较少(关于cached占用过高的分析处理请参见另一篇文章), 这时首先想到是不是有进程内存泄漏,经查询tengine和别的进程没有发现有占用大量内存即不存在内存泄漏。
cat /proc/meminfo细化查看内存各部分的使用,可以发现slab占用过高约40GB,同时也可以观察到SReclaimable也很高,即SReclaimable指可收回Slab的大小。
查看监控中的slab曲线一直处于增长状态
详细查看slab中各部分内存的占用,可以看出dentry占用的很多,大约在40GB内存。
dentry的作用:当读写文件时内核会为该文件对象建立一个dentry,并将其缓存起来,方便下一次读写时直接从内存中取出提高效率。

再详细查看一下dentry的使用情况:
$cat /proc/sys/fs/dentry-state
209815031 209805757 45 0 0 0
从上查看dentry使用数量,可以发现有大量unused dentries占用率很高,没有释放掉。
以上数据的详细含义可以man proc查看,下边是可以从网上查到的中文含义
dentunusd:在缓冲目录条目中没有使用的条目数量.
file-nr:被系统使用的文件句柄数量.
inode-nr:使用的索引节点数量.
pty-nr:使用的pty数量.
1)dentunusd
dentunusd数据的数据来源是/proc/sys/fs/dentry-state的第二项数据.
要弄明白它的意义,我们首先要弄明白dcache(目录高速缓存),因为系统中所有的inode都是通过文件名来访问的,而为了解决文件名到inode转换的时间,就引入了dcache.
它是VFS层为当前活动和最近使用的名字维护的一个cache.
dcache中所有处于unused状态和negative(消极)状态的dentry对象都通链入到dentry_unused链表中,这种dentry对象在回收内存时可能会被释放.
如果我们在系统中运行ls -ltR /etc/会看到dentunusd的数量会多起来.
而通过mount -o remount /dev/sda1会看到dentunusd会迅速会回收.
2)file-nr
file-nr的的数据来源是/proc/sys/fs/file-nr文件的第一项数据.
实际上file-nr不是一个准确的值,file-nr每次增加的步长是64(64位系统),例如现在file-nr为2528,实际上可能只打开了2527个文件,而此时你打开两个文件后,它就会变成2592,而不是2530.
3)inode-nr
inode-nr的数据来源是/proc/sys/fs/inode-nr文件的第一项数据减去第二项数据的值.
inode-nr文件的第一项数据是已经分配过的INODE节点.第二项数据是空闲的INODE节点.
例如,inode-nr文件里的值为:13720 7987
我们新建一个文件file1,此时inode-nr第一项数据会加1,就是13721,表示系统里建立了这么多的inode.
我们再删除掉file1,此时就会变成13720.
空闲的INODE节点表示我们已经里这么多的INODE节点曾经有过被利用,但没有被释放.
所以INODE节点总数减去空闲的INODE,就是正在被用的INODE.
最后通过使用mount -o remount /dev/sda1命令,空闲节点会被刷新,所以inode-nr的值会有所变化.
4)pty-nr
pty-nr的数据来源是/proc/sys/kernel/pty/nr
表示登陆过的终端总数,如果我们登录过10回,退出了3回,最后的结果还是10回.
也可用于sar命令查看dentunusd以秒为间隔查看dentry的变化。
$sar -v 1
12:07:09 AM dentunusd file-nr inode-nr pty-nr
12:07:10 AM 183107848 1088 42210 44
12:07:11 AM 183107871 1088 42245 44
12:07:12 AM 183116550 1152 42290 44
12:07:13 AM 183116581 1088 42343 44
12:07:14 AM 183116617 1216 42396 44
12:07:15 AM 183116059 1216 40585 44
关于linux dentry的介绍可以搜出来一大把,包括dentry占用过高,不外乎两种处理方法,一种是直接通过proc系统清理dentry,命令如下:
sudo sh -c "echo 2 > /proc/sys/vm/drop_caches"
缺点是执行命令过程容易hang住几分钟,而且redhat官方也不建议使用这种方式清理cache等;另外一种方法是通过调整内核参数vm.vfs_cache_pressure,含义如下,先调整为vm.vfs_cache_pressure=10000观察一天也没有发现能使dentry降下去。
vm.vfs_cache_pressure控制内核回收用于dentry和inode cache内存的倾向。 默认值是100,内核会根据pagecache和swapcache的回收情况,让dentry和inode cache的内存占用量保持在一个相对公平的百分比上。减小vfs_cache_pressure会让内核更倾向于保留dentry和inode cache。当vfs_cache_pressure等于0,在内存紧张时内核也不会回收dentry和inode cache,这容易导致OOM。如果vfs_cache_pressure的值超过100,内核会更倾向于回收dentry和inode cache。
细节分析
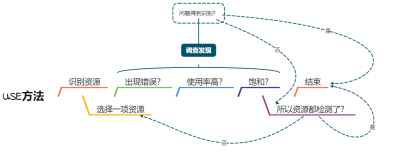
即然上述两个办法都不是完美的方法,就需要确认这么多unused dentries到底是那些文件占用的? 按正常理解情况下linux内核不太可能释放不了dentry。
首先通过查看内核dentry结构部分的代码(fs/dcache.c),搞清楚了所有的unused dentries挂在了super_blocks 结构的s_dentry_lru链表上,可以通过遍历此链表上的节点输出这些节点代表的文件名,就可以知道dentries被那些文件占用。
思路:用systemtap工具做内核探测,将每个节点的文件名写入到log文件。guru模式关键代码如下:
if (!list_empty(&sb->s_dentry_lru)) {
list_for_each_entry(dent, &sb->s_dentry_lru, d_lru) {
spin_lock(&dent->d_lock);
if (dent->d_flags & DCACHE_REFERENCED) {
dcache_referenced_nr++;
}
spin_unlock(&dent->d_lock);
memset(path, 0, 2048);
cp = dentry_path_stp(dent, path, 1024); //解析每个dentry的文件路径,参考char *dentry_path(struct dentry *dentry, char *buf, int buflen)的实现
if (!IS_ERR(cp)) {
if(strlen(cp))
//offset += snprintf(buf+offset, PAGE_SIZE-offset, "%s", cp);
;
else
cp = path+1024;
}
pp = path+1024;
pp += sprintf(path+1024, "%d ", dcache_referenced_nr);
if (offset + (pp-cp) + 3 >= PAGE_SIZE) {//\r\n space
fp->f_op->write(fp, buf, offset, &fp->f_pos); //将文件路径写log
offset = 0;
memset(buf,0,PAGE_SIZE);
}
offset += snprintf(buf+offset, PAGE_SIZE-offset, "%s %s\r\n", cp, path+1024);
}//end list_for日志分析
查看某一台主机上的dentry条目如下,约3.3亿。
$cat /proc/sys/fs/dentry-state
338031179 338022259 45 0 0 0
systemtap脚本执行完成后,生成日志文件,经分析/etc/pki/nssdb/xxxx,占用量最大1点多亿条dentry.
$sudo grep "/etc/pki/nssdb" dcache.log |wc -l
131071404
$grep '/etc/pki/nssdb' dcache.log | more
/etc/pki/nssdb/._dOeSnotExist_-869749107.db 223
/etc/pki/nssdb/._dOeSnotExist_-869749108.db 224
/etc/pki/nssdb/._dOeSnotExist_-869749109.db 225
/etc/pki/nssdb/._dOeSnotExist_-869749110.db 226
/etc/pki/nssdb/._dOeSnotExist_-869749111.db 227
/etc/pki/nssdb/._dOeSnotExist_-869749112.db 228
/etc/pki/nssdb/._dOeSnotExist_-869749113.db 229
/etc/pki/nssdb/._dOeSnotExist_-869749114.db 230
/etc/pki/nssdb/._dOeSnotExist_-869749115.db 231
/etc/pki/nssdb/._dOeSnotExist_-869749116.db 232
/etc/pki/nssdb/._dOeSnotExist_-869749117.db 233
/etc/pki/nssdb/._dOeSnotExist_-869749118.db 234
/etc/pki/nssdb/._dOeSnotExist_-869749119.db 235
/etc/pki/nssdb/._dOeSnotExist_-869749120.db 236
/etc/pki/nssdb/._dOeSnotExist_-869749121.db 237
/etc/pki/nssdb/._dOeSnotExist_-869749122.db 238
/etc/pki/nssdb/._dOeSnotExist_-869749123.db 239
/etc/pki/nssdb/._dOeSnotExist_-869749124.db 240
/etc/pki/nssdb/._dOeSnotExist_-869749125.db 241
/etc/pki/nssdb/._dOeSnotExist_-869749126.db 242
/etc/pki/nssdb/._dOeSnotExist_-869749127.db 243
/etc/pki/nssdb/._dOeSnotExist_-869749128.db 244
/etc/pki/nssdb/._dOeSnotExist_-869749129.db 245
/etc/pki/nssdb/._dOeSnotExist_-869749130.db 246
……
从上边可能看出只有/etc/pki/nssdb/._dOeSnotExist_ 的使用不明确搜索一把,发现redhat 6系列的系统中存在的问题, bug分析详细参考:
Can curl HTTPS requests make fewer access system calls?
https://bugzilla.redhat.com/show_bug.cgi?id=1044666
因为tengine主机上调用了大量的curl https做探测(curl的版本7.19),使用如下命令做了一下分析可以明确发现一次curl有上百次的访问/etc/pki/nssdb/.xxx文件产生大量的dentry,
sudo strace -f -e trace=access curl 'https://www.taobao.com'
另外由于agent周期性的在拉取配置文件这些配置文件以当前时刻做文件名,也造成大量的dentry。两者加起来的数量基本符合/proc/sys/fs/dentry-state查出来的数量。
至此问题的两个主要原因已经比较清楚。
解决方案
- 保留系统和应用程序所需要的可用内存,如调整vm.min_free_kbytes = 4194304 vm.extra_free_kbytes = 4194304 使系统free的内存最少保持在8GB以上(注意6U系统才有extra_free_kbytes)
- 升级curl更高版本
- 升级nss-softokn 与nss-util rpm包到较高的版本 3.14.3-22,3.16.2.3(未验证参考http://support.huawei.com/huaweiconnect/enterprise/thread-333119.html)
- 优化tengine的配置与日志文件使尽可能少的产生文件dentry
案例小结
此例问题对所有linux主机上dentry占用较高分析有借鉴参考意义。
备注
内存回收主要的两大机制:kswapd和“Low on Memory Reclaim”。即当系统中的可用内存很少时,守护进程kswapd被唤醒开始释放页面,如果内存压力很大,进程也会同步地释放内存,这种情况被称为direct-reclaim.
kswapd释放内存页面的数量是有一定的比例的(有兴趣可以查阅pages_min, pages_low and pages_high这些参数),但是当内存的分配占用率高于释放率时,就引起了上述的问题即看到内存一直在增长。