什么是AR? 为什么AR?
Augmented reality译作增强现实。顾名思义,现实就是我们所在的物理世界,而增强则指由计算机所编辑进而与真实世界相融合重新呈现给我们的增强世界。

图1:AR即将改变我们的生活模式,如:出行、阅读、生活、工作、购物和娱乐
AR可以发挥计算机的优势进而强化人自身传感处理能力的不足,可以通过增强世界提供进入虚拟世界的入口,也可以产生人与人、人与世界的全新连通与互动方式。就像图1所示的那样,它即将深刻改变我们的出行、阅读、生活、工作、购物和娱乐等模式。
从集团角度讲,AR可能成为一种为新零售新生活打造的高效连接线上线下的纽带,也可通过其对物理世界与虚拟世界的双重连接更好地形成社区,亦可通过其提供的虚拟世界编辑能力更有效地“生产快乐”以打造生活化平台而不仅仅是电商平台。更重要的是,谁抢占了未来AR的app入口,谁就更有能力获得更多真实物理世界的数字化信息,而这些数据本身将带来更大价值。
AR的核心问题有哪些?
既然AR如此有潜力,那么AR所面对的核心问题都有哪些呢?
AR的核心要素:
AR系统有相互联系、密不可分的三个核心要素:
- 对世界的感知:逆向工程物理世界,将其数字化;
- 对世界的编辑:正向创造一个虚拟世界,并与真实世界融合为增强世界;
- 互动:用户与世界、用户与用户的互动。
AR的核心需求:
在上述核心要素的基础上,AR的核心需求是实时性,因此需要足够高效的算法以及充足的硬件计算处理能力。
AR的研究边际:
真实物理世界的信息维度过高,因此AR只关注那些能被人体传感器系统所截获并呈现在人脑中的方式,例如:可见光(390-700nm)视觉,(20Hz-20KHz)听觉等,因为如果创造的增强世界不能被人所接收和呈现也是意义有限的。
AR核心问题描述:
1. 流程概述: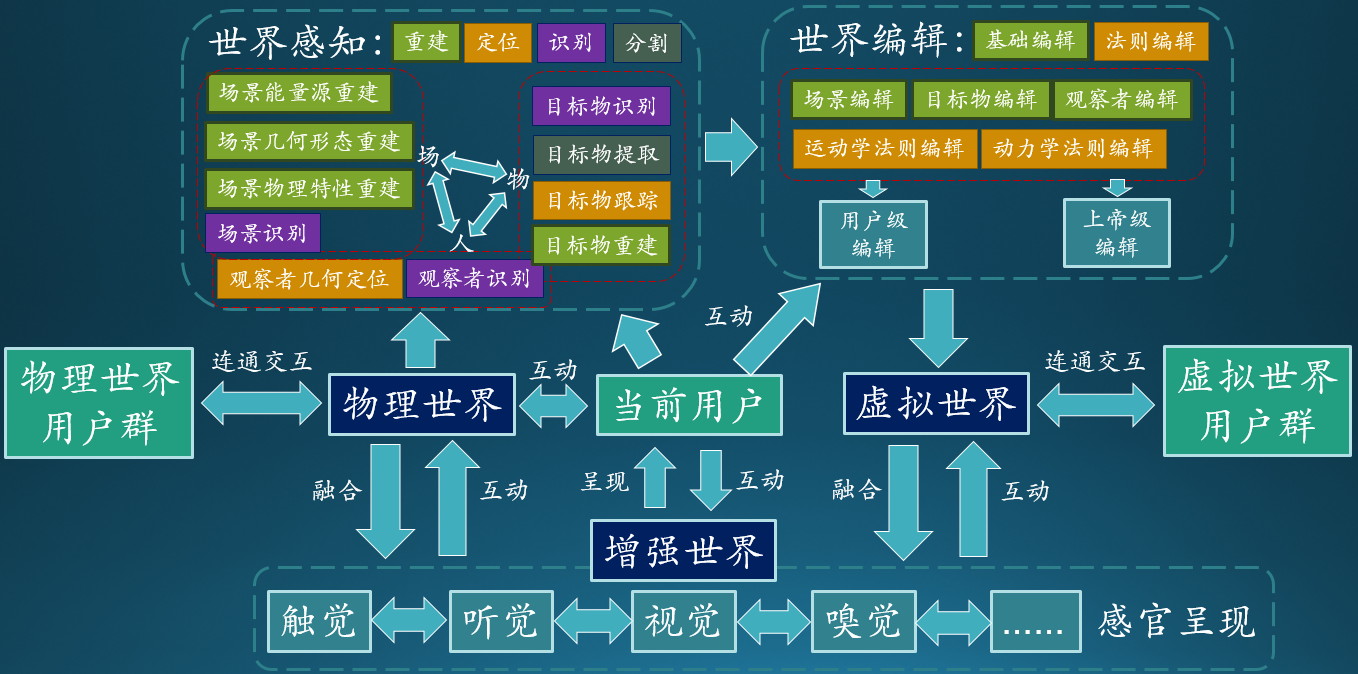
图2:AR流程图与核心问题描述
首先,我们先跟大家解释下这几个名词的含义以便后续理解:物理世界是真实世界,虚拟世界是在电脑中产生的世界(比如:游戏魔兽世界),增强世界是真实和虚拟融合在一起并呈现给用户的世界。
现在,我们将用图2来阐述对AR的理解并描述其核心问题。
AR设备用起来很简单,但这个“黑盒子”里究竟发生了什么呢?下面是AR的大致工作流程:①利用AR设备中的传感器系统,去完成对物理世界的感知并将其数字化;②这些数字化信息进入“世界编辑”流程,用以创造一个和物理世界相关的虚拟世界;③最后,物理世界和虚拟世界相融合,形成增强世界。
用户可以通过与增强世界的在线互动,进而改变虚拟世界,如:在虚拟世界中给家里的沙发换色以搭配家装。用户也可通过与增强世界的交互改变物理世界,如:利用AR设备的无线通信功能打开电器。用户又可通过世界编辑提供的虚拟世界创造功能离线添加虚拟世界的内容。当然也可正常与物理世界进行交互。
通过世界感知这个桥梁,AR连通了物理世界和虚拟世界。通过这两个世界,继而可以跨时空建立起更多用户与用户的联系。世界编辑则提供了建立虚拟世界的基础能力,决定了日后AR社区能否更容易让用户创造内容。用户和世界、用户和用户的可交互维度和便利性,将决定AR最终的成败。
下面,我们将就图2中的世界感知和世界编辑问题进行展开。由于不同的感官呈现方式对世界感知的需求存在很强的共性,下面我们将仅仅以视觉为例。
2. 世界感知:
世界感知,按所感知类别可分为对人、物、场的感知。按照问题描述,又可分为重建、定位、识别和分割问题。其中,重建和定位问题绝大部分属于基于物理模型的传统计算机视觉范畴,而识别和分割问题则随着AI大潮一起被更多地采用数据驱动的方式去解决。下面针对图2中所列的问题,从视觉的角度,简要说明其含义:
2.1 对场景的感知
1) 场景能量源重建:主要指用图像去推断光源的信息。例如:光源的方向,位置,强度以及颜色等。这些信息可帮助还原场景中光度不变性信息(photometric invariant)以获得场景本体反射图(intrinsic image),继而在编辑世界(渲染)的过程中辅助数字化重打光(digital relighting)以达到更加真实的渲染效果。

2) 场景几何形态重建:主要指构建三维世界的空间几何形态,解决空间中有没有物体的问题。构建起的几何形态,可被用来当作空间地图使用以完成精确定位,可渲染生成可视化三维模型进行展示,也可利用几何形态信息完成对三维场景的空间分割。
3) 场景物理特性重建:主要用来还原场景中区域的反射性质(如BRDF)。可利用材质库反射信息推断物体材质,渲染替换真实物体中特定材质的区域。对物体材质的推测,也可帮助更好地完成物体识别等视觉任务。

图5:技术实例:对材质信息进行感知,根据材质的不同对场景区域进行分割,并将真实物体中的特定材质渲染成为新材质并呈现
4) 场景识别:主要可用在分辨当前场景最有可能出现的地点,筛选后可完成基于视觉的粗定位。
2.2 对人的感知
1)观察者几何定位:主要感知人与场景的相对位置关系,通常和场景几何形态重建共同完成(如SLAM,VO)。
2)观察者识别:包括人脸识别相关的应用场景,主要解决人是谁的问题,也可识别人的心情等。同时,也包括手势、动作识别等以更有效地进行人机交互。
2.3 对目标物的感知
1) 目标物识别:主要识别图像中的目标物体并定位其在二维图像中的位置。如果有场景额外三维信息,可推测目标物在三维空间中的位置。目标物的位置又可辅助完成基于high-level语义信息的定位。

图6:技术实例:左:2D目标物识别和定位;右:3D目标物识别和定位
2)目标物提取:主要识别并提取图像中的目标物,可将目标物传送到任意其他场景,或将其他物体渲染到目标物位置。这个提取过程可能在二维图像中完成,若有三维几何信息,也可在三维世界中完成。
图7:技术实例:上:2D目标物提取;右:3D目标物提取
3) 目标物跟踪:通常识别到目标物后,需要跟踪目标在图像中的位置。跟踪的意义主要在于其快速性和稳定性。
4) 目标物重建:与场景几何形态和物理特性重建类似,但目标物重建额外需要目标物从场景中的分割提取。重建目标物,可生成三维渲染模型,将其以最简化的表达任意传送至其他渲染目的地。建立起的三维模型库也将对三维物体识别等问题产生深远影响。
3. 世界编辑:
在世界感知过程中,我们得到了场景、目标物和人的数字化信息。在世界编辑过程中,我们可以利用这些信息,按照真实世界的物理规则和人眼作为受众去创造(渲染)虚拟世界并呈现给人们。我们也可以改变观察者特性,呈现给人一个完全不同的对真实世界的感知体验,例如提供小动物眼睛的模拟器去看世界。
更有意思的是,这个计算机所生成世界的运行法则可以由我们来制定,我们就是这个世界的上帝。就像黑客帝国中所描绘的那样,可以扭曲虚拟世界中的物理定律。随着AR技术的进步,我们将来很可能傻傻分不清什么才是真实,要不要从违反物理定律角度开个后门呢?~
对于世界编辑来说,上帝级开发者编辑虚拟世界中事物的运行法则,而开放给普通用户一些基础世界编辑能力也很必要,靠大众去创造更多的内容。小编想起了很早以前流行的一款叫《孢子》的游戏,其中所有事物都可以由玩家所创造,玩家间也可以共享创造,这样就形成了社区。据游戏发行公司EA统计,创造器发布18天,玩家群体一共上传了1,589,000种生物。设计师莱特曾幽默地说,玩家已经高效地完成了上帝38%的工作。可见用户参与编辑设计的力量。若加之一些合理的主干引导和支线剧情,游戏本身可以说就有千变万化的玩法。回想Pokemon go,是不是离成功就差了更多用户参与的内容迭代机制呢?我们可不可以借鉴类似的思路用在我们AR内容的创造上呢?
图8:《孢子》生物创造器
AR已有哪些技术落地?业务场景有哪些?
前面讲了这么多对AR的理解,想必大家要问:AR目前真正落地的技术有哪些,业务场景又有哪些呢?由于小编来自算法团队,主要做利用视觉进行世界感知部分,因此只适合从这方面介绍。虽然技术是为业务需求服务的,但是如果按照业务线梳理过于庞杂,很难有系统性,因此我们按照技术线去梳理,从视觉AR基础技术的角度出发,进而讲述哪些业务应用到了这些技术。由于篇幅有限,主要介绍两类关键技术:1)自然特征检测和跟踪;2)SLAM。其他技术,比如LBS AR,三维物体识别与跟踪等技术均已落地一些业务场景(如:双十一寻找狂欢猫),但在此不做展开。
自然特征检测和跟踪
自然特征(nature feature)通常是指一个平面图案(marker),比如是公司的logo等。借助这个marker,可以帮助我们建立起相机和三维世界的(6自由度)相对姿态关系,如图9所示。
图9:通过Marker建立相机与世界相对姿态原理图
要将自然特征有效运用,就需要完成两项基本任务:检测和跟踪。检测解决的是判断目标marker是否出现在画面中并且初始化世界坐标系(marker坐标系)的问题。而跟踪则解决在初始化完成后,如何稳定跟踪marker的位置并实时算出相机相对世界坐标系的姿态(camera pose)。
Marker的检测主要通过存储的marker特征点描述和场景中的特征点描述进行匹配来完成。若匹配成功,则代表已检测到marker。随即,通过在二维图像中特征点的对应关系,在已知相机内参(camera intrinsics)的情况下,可以利用解决perspective-n-point (PnP) 问题的各种算法解算camera pose以完成初始化。
关于marker检测环节,还有一些额外的技术考量。首先,marker检测可能要求同时检测多种不同的marker,如果对于每一种marker都进行一次匹配显然是不可行的,因为这种方式不scalable。这就要求我们建立起marker的索引树,例如应用Bag-of-Words(BoW)方法。这样可以让我们像查字典一样快速检索,让同时在线检测多个marker成为可能。其次,之所以选用特征匹配方式(feature-based matching)而不是图像块匹配(patch-based matching,又通常叫direct method),因为相比patch而言,feature拥有更好的尺度不变性和方向不变性,而且对光照变化更加不敏感,因此可以提供更加鲁棒的特征点。然而feature相比patch的缺点也十分明显,即其计算代价相对较高。对于实时性要求很高的AR应用来说,有些特征描述的计算代价甚至是不可接受的(如SIFT)。平衡计算代价和准确程度,我们最终倾向采用Freak或ORB。在实际操作中,我们采用了Freak特征。
第二个基本任务是marker的跟踪。有人可能要问,为什么不对每一帧marker都做检测,那样不就不用跟踪了吗?之所以用跟踪,主要有三点考虑:其一,跟踪较之识别,计算代价更小;其二,应用跟踪可以防止相机姿态的跳变;其三,利用跟踪,可以建立起相机的运动模型,若突然哪一帧图像质量不好,还可以通过相机运动模型进行预测(prediction),例如应用卡尔曼或粒子滤波等,以减少跟丢概率。
在marker跟踪过程中,由于特征提取很耗费计算资源,因此对于当前帧,只提取上一帧Freak位置一个特定大小neighborhood内的特征点并进行特征匹配以找到两个相邻帧Freak特征的对应点关系。在前一帧图像中,每一个Freak特征都对应了一个世界坐标系下的三维点坐标,这些点映射回当前帧画面的点的坐标是我们之前找到的对应点,我们的优化目标是计算当前帧相机相对世界坐标系的姿态。我们可以利用reprojection error最小作为目标建立起最优化目标函数,初始化前一帧相机姿态作为当前相机姿态,利用梯度下降等数值方法求解最优解。这个求解过程转化为了求解典型的bundle adjustment问题。这样做的优点相较于已知二维特征对应点关系直接应用PnP来讲,可以减少相机姿态跳变的概率,这也是很多主流Visual Odometry (VO) 算法所采取的方式。
Marker的检测和跟踪作为AR的一种基础能力,对手淘的多种业务产生了影响,例如:AR互动营销,双十一跨屏抢星衣和AR Shoes等。手淘的AR MagicEye互动平台就是以此技术为原点建立起来的。
AR互动营销落地的业务有中秋抢月饼。扫一下一个淘公仔的形象,一个动态的淘公仔就展现在你手机里。上传一张照片,它就可以拿着这照片到处抖起来了~
类似的业务还有扫五环,哈根达斯logo等出各种AR效果并和用户产生互动。

图10:AR互动营销案例
双十一抢星衣活动也是主要依赖marker快速检测技术完成的。如图11所示,在林志玲准备抛衣服前一刻,电视屏幕上会显示出marker,当然这个marker只占电视屏幕的一小部分。这就要求当marker在手机屏幕占比足够小时,算法仍需要快速准确检测出来。用户打开手机瞄准电视,检测到了这个marker也就完成了抢星衣过程。
图11:双十一跨屏抢星衣
AR Shoes主要目的是提供一种视觉测量手段使用户能够方便测量自己脚的尺寸以买合适大小的鞋。如图12所示,用户将身份证作为Marker去定基准面。身份证大小已知,假设脚在基准面上,这样就有了绝对尺寸信息。用户在图像中框出自己的脚,已知相机内参,也就可以计算出在基准面上所框区域的长宽,而这就是脚的尺寸。这里之所以选择身份证,是因为人人都有,能让更多人用起这个功能。
图12:AR Shoes 视觉测量
Simultaneous Localization and Mapping (SLAM)
SLAM(同时定位并建图)技术是除marker外另一项AR的基础能力。顾名思义,它的目的是同时计算相机姿态和环境三维几何信息。
我们关注的是基于视觉的SLAM(VSLAM),因此不关注利用其它传感器(如激光雷达)的SLAM问题。在VSLAM中,我们只关注基于单目摄像头的SLAM,因为我们的传感器主要依赖用户手机的摄像头。对于手机AR应用来说,SLAM的侧重点在其定位而不是建图功能,因此我们暂时不关注那些semi-dense或者dense的SLAM算法,只用稀疏点云(sparse point cloud)来描述三维地图。
VSLAM(又作structure from motion)的原理类似于双目视觉,采用的是三角定位(triangulation)原理。VSLAM需要两张有足够视差的图像帧去还原图像中对应特征点在三维空间中的坐标,同时算出这两帧图像所对应的相对相机姿态。严格上说,VSLAM只能还原3个转动自由度和2个平移自由度信息(一个normalized的3维平移向量),无法获得绝对距离信息,因此需要额外融合手机IMU提供的信息,以获得真正的三维空间。对类似双目视觉基础原理感兴趣的同学可以参考这个领域的经典书籍《Multiple View Geometry in Computer Vision》。随着相机的移动,SLAM观测到了更多环境中的特征点并加入三维地图,同时可以计算出此时相对前一帧的相机姿态。此外,VSLAM还涉及关键帧筛选(key-frame selection),闭环检测(loop-detection),光束优化(bundle-adjustment)等技术点。
结合已有的大量VSLAM领域文献和我们的工程实践,针对移动端AR的具体需求,我们总结了一套针对移动端AR的VSLAM算法流程(AliSLAM),如图13所示。由于各中细节考量众多,篇幅有限,在此就不一一赘述。

图13:AliSLAM算法流程图
AliSLAM针对移动端AR需求已完成的优化,包括但不限于:缩小BoW词库大小以降低分发成本,并行框架加速和GPU加速,IMU传感器融合以防抖防丢,基于patch取代基于feature的跟踪以提速等。优化后性能参数如下表所示。与PC端SLAM的优化目标不同,AliSLAM的主要优化目标是在精度可接受范围内尽可能提高其快速性以提升用户流畅性体验和降低用户应用门槛。 AliSLAM已集成到手淘并应用在多个业务场景,如极有家AR Detail,AR电器说明书。
AliSLAM已集成到手淘并应用在多个业务场景,如极有家AR Detail,AR电器说明书。
极有家AR Detail是利用用户操作,通过SLAM在三维世界中的定位功能,放置一个虚拟物体在实际三维世界的某个位置。当放置成功后,用户可从各个角度观察这个虚拟物体的细节,并仿佛它就摆在你面前一样。这个功能将为以后的各种虚拟或增强购物打底。想象一下,以SLAM技术为基础,我们可以提供操纵图14中这台虚拟手机的能力,是不是很有意思~
图14:AR Detail案例展示
AR说明书是利用AR的方式展示实际生活、生产环节中一些器械的使用方式或是工作原理。比如家电(洗衣机、电饭煲等)的3D形式说明书(如图15),工厂内一些机器的虚拟操作指南等。这项业务主要依托于三维物体跟踪和SLAM技术。

图15:AR说明书示例图
其他技术
AR已落地的其他技术还有很多,如:三维物体识别和跟踪,LBS AR。双十一寻找狂欢猫作为不得不提的典型案例成为了应用LBS AR技术的经典。作为2016双十一最火爆的线上线下造势和预热活动,总PV为16亿,日均PV 3亿多,UV 3100万,同时支持星巴克、KFC等60多款品牌猫。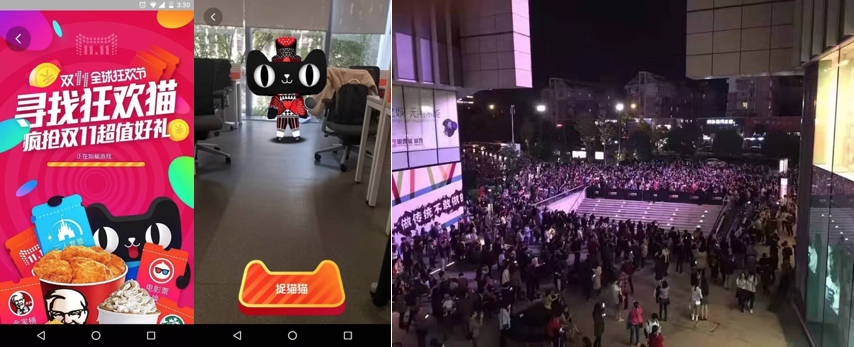
如果您已经耐心看到这里,说明您是我们的知音。无论您对AR有哪些思考,想到了哪些新玩法,或是想和我们讨论一些技术层面的问题,非常欢迎您致信hexa_ar@list.alibaba-inc.com。发挥您的想象力,一不小心,未来生活的方式将因您这封邮件而改变,why not?
本文主要由阿里AI LAB源方执笔。文中涉及的技术是全组人共同的结晶@方如@烁凡@水源@紫炎@煦深,我们是阿里AI LAB AR算法团队。
本文部分图片取自互联网,在此鸣谢所有原图分享者。