出大事了!
据可靠消息,位于荷兰海牙的一家云主机商 verelox.com, 一名前任管理员删光了该公司所有客户的数据,并且擦除了大多数服务器上面的内容,客户数据恢复希望渺茫。
引用verelox.com公告全文:
首先,我们想要对由此造成的任何不便表示歉意!
不幸的是,一名前任管理员删光了所有的客户数据,并且擦除了大多数服务器上面的内容。正因为如此,我们已采取了必要的步骤或措施,暂时将我们的网络下线。我们一直在努力恢复数据,但是这个方法可能恢复不了已丢失的所有数据。我们的网络和托管服务会在本周恢复正常,到时会打上安全更新版。仍对我们的服务有兴趣的现有客户将获得服务的相应补偿。
如果客户有重要数据,请联系我们:support@verelox.com。[email protected]�的数据。
我们给出的建议是,更改所有服务器密码。
状态更新1:(最终)位于荷兰的所有专用服务器应该会在协调世界时(UTC)傍晚6点投入正常运行。我们仍在为云服务器制定一套解决方案。
状态更新2:所有专用服务器已正常运行。如果您的专用服务器还是遇到任何问题,请发送电子邮件至support@verelox.com。眼下,所有虚拟机都上传到一台新的服务器。
等等,又是荷兰?!我怎么闻到了似曾相识的味道捏。没错,年初的GitLab的删库事件也发生在荷兰!看来今年不是荷兰的DBA时来运转的好时期。
回到事件,要怎么处理呢?我也不知道啊,静观其变。
不过这惨绝人寰的事情接连发生,让多愁善感的小编又要失眠了。月黑风高,有酒有故事,我们一起来回顾下那些删库跑路的日子吧。
我们一起删库跑路
不知道什么时候开始,有一本红遍大江南北的书叫做《MySQL 从删库到跑路》广泛流传于IT界,并持续阴魂不散,带着一股妖风,影响了整个IT界的风气。广大的运维DBA们,大概是找不到女朋友生活没有什么乐趣吧(小编已经做好被打死的准备了),非得找点好玩的事情来体验下人生。什么最好玩呢,当然是破坏!
来我们玩个游戏!
问:你想删库吗?
DBA:我有病啊
问:你想删库吗?
DBA:不想啊
问:你想删库吗?
DBA:要负责任吗?
问:你想删库吗?
DBA:我操,这么刺激的事谁不想干!
看出来了吧,没有不想删库的DBA,只有不想负责任删库的DBA。但是自从'从删库到跑路'这一思想传遍大江南北,大家都知道了答案,再不济我还可以跑啊!你是不是也是这么想的。
大家都想删库,都想好了出路。果然2017在劫难逃。我们来细数一下2017所遭遇的删库跑路事件。
断电又不怪我
1月20日,大约一定是受到川普上任的影响,突如其来的服务器故障影响了一大批炉石玩家,恢复时间长,由于意外断电,导致数据库损坏,不得不通过游戏回档恢复数据库的使用。(关于炉石传说的Oracle数据库故障不要以为你也可以幸免)
游戏进度回退了,辛辛苦苦挣来的装备都不见了,然而面对网易和暴雪如此诚恳的态度,想发火都不容易。
深夜加班我也累呀
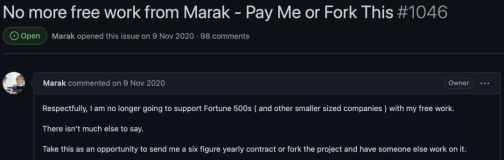
2月1日,除夕刚刚过完,荷兰的一个DBA在数据库复制过程中意外地删除了一个错误的服务器上的目录,删除了一个包含300GB的实时生产数据的文件夹。300G的数据库被删成4.5G,由于没有有效的备份,尝试了所有5个恢复工具都没有完成恢复。在丢失数据并恢复失败后,服务器彻底崩溃。(五重备份无一有效,还有哪些 rm -rf 和GitLab类似的忧伤?)
这估计是春节期间最劲爆的消息了,大过年的大家都放弃了吃肉喝酒的好光阴大半夜守着GitLab的故障分析直播。
讲真,我还真没有见过孩纸们这么热爱学习的时候呢。
老板你总是舍不得买高性能的存储
2月11日,网络剪报服务商 - Instapaper 遭受了超过31小时的服务中断,声明需要一个星期的数据库恢复时间,然而经过10天的恢复,也仅仅恢复了6个星期的数据。(云服务真的靠谱吗? AWS 用户中断31小时仅恢复6周数据)
Instapaper 最初的全文检索使用一台 Sphinx 服务器直接和 MySQL 联合提供搜索,这个搜索使用 AWS EC2 大约70GB 内存,4TB 存储的资源:
Instapaper 的索引数据量(数据库的数据量未知),在2016年5月时数据量2.2TB,每月增长约110GB,后来实在慢的不行,最后选择了 AWS 的 elasticsearch cluster来承载这项服务。而最终,还是败在了存储,数据写入失败直接导致数据库宕机。
别这么看我,我们都犯错,只是我犯的错误更严重罢了
2017-04-05,位于纽约的云服务商 Digital Ocean 遭遇了一次长达4小时56分钟的停机事故,事故的原因是主数据库被删除了(primary database had been deleted),由于配置错误,本应指向测试环境的任务被指向了生产环境,测试任务包含的环境初始化过程删除了主生产数据库。(不以规矩不成方圆:Digital Ocean也删除了他们的数据库)
手动删库简直太low,我都是脚本自动删
又不禁想起了Google曾经轰动一时的流水线删库事件,这可是团队作案哟,这么团结真的好吗?(时移世易:遵从既往经验致 1.5PB 数据删除,Google SRE是如何应对的?)
一个 Google Music 用户汇报某些之前播放正常的歌曲现在无法播放了。Google Music 的用户支持团队通知了工程师团队,这个问题被归类为流媒体播放问题进行调查。3 月 7 日,负责调查此事的工程师发现无法播放的歌曲的元数据中缺少了一个针对具体音频数据文件的指针,于是他就修复了这个歌曲的问题。
但是,Google 工程师经常喜欢深究问题,也引以为豪,于是他就继续在系统中查找可能存在的问题,当发现数据完整性损坏的真正原因时,他却差点吓出心脏病:这段数据是被某个保护隐私目的的数据删除流水线所删掉的。Google Music 的这个子系统的设计目标之一就是在尽可能短的时间内删除海量音频数据。
该流水线任务大概误删除了 60 万条音频文件,大概影响了 2.1 万用户.
办法不早就教你了吗
删库就删库也没有什么了不起,但是千万别说我没有告诉过你处理办法。不信往这里看,岁末警示:当你手抖删了线上数据库..
互联网发展仍是日新月异,挑战无处不在。要想变挑战为机遇,只有创新和技术才有可能。只有重视技术的公司,才能充分发挥技术人员的能动性,也将更容易在技术的竞争中胜出。
我们经常开玩笑,很多公司,做不到技术驱动,因为他的每一步都是领导提出领导拍板,它只能叫领导驱动。而如果一个公司在遇到事情之后就总是想到惩罚,不注意保护和发挥技术人员的能动性,技术导向也只能是一个口号。
所以下次呢,如果你手抖删库了,一定要冷静地到你老板那里说,人家也很伤心,需要抱抱安慰。
好吧你这样就太过了,会被老板轰出去的。但你要记得,不要谈故障的原因,要谈解决方案,Be a man,你自己闯下的祸,自己承担起来!
万一老板真要惩罚你怎么办,一个字,跑啊!说实话,你是不是老早就打算删库跑路了,只是一直没有机会。
小编最近查了一下,发现想跑路的人真是不少。
我说大家都怎么了呢,这是跟世界有多大的仇恨呀。不过考虑到,你们可能真的没有遇到好老板心里苦,你看像我这种生活在幸福深处的员工,有一个超级完美的老板,就完全不能理解你们普通人的心情。
既然你都有了这种想法,我好像也没有什么可说的了。但是我必须要再次苦口婆心地提醒你,备份重于一切!rm是危险的!三思而后行!如果这三句话还没有成为你的座右铭,我觉得你应该需要休个假好好思考一下人生了~
最后,小编实在没实力,得找老板来撑下场子。压轴出场,如何幸存于类似事故?
好吧,我们谈一谈如何避免陷入这样的困境?以下是我们的一些思路,与大家商榷。
首先,要有完善、有效的备份和容灾机制。诚然很多企业都有了一整套的备份、容灾机制,但是这套备份机制能否真实奏效是需要检验的。我接触过某大型企业,投入巨资兴建的灾备中心,从未正式切换过,这样的灾备在故障来临时也很难有人拍板去进行切换,所以备份的有效、容灾手段的有效是必须确保的。注意,备份的恢复速度必须足够的考虑到,磁带的低效备份关键时刻会害死人。
其次,要有完善的故障处理策略和流程。对于不同系统,在关键时刻要优先确保什么,是要订立规则的,有了规则才能照章办事,不走错方向,不无辜背锅。几年前某国内金融系统出现数据坏块,同样选择了带病修复,最终没能解决问题,同样选择了回档承担了数据损失。
再次,要有端到端融会贯通的应急机制。也就是说不仅仅技术上具备容灾应急的响应方案,从业务端同样要有对应的预案,以便应急时同步处理,区别对待。很多时候,有了业务上的应急、降级服务方案,技术层面的处理就能够从容许多。
最后,要有能够快速协同的团队资源。很多时候严重的故障,需要较大规模的专业团队协作处理,原厂商和第三方在其中都承载着重要的角色,所以关键时刻,要能够获得内外部快速及时的支持,尤其是在绵延数天的高强度工作中。
讲真,不要把我们的话当成耳旁风,备份重于一切。预防和检测少不了。
如果真的删库了,请找云和恩墨,我们7*24为你的数据库安全站岗。
本文出自数据和云公众号,原文链接