热门
【信息安全管理与评估】2024年北京市职业院校技能大赛高职组“信息安全管理与评估”赛题模块(理论技能)
【信息安全管理与评估】2024年北京市职业院校技能大赛高职组“信息安全管理与评估”赛题模块(三)
【信息安全管理与评估】2024年北京市职业院校技能大赛高职组“信息安全管理与评估”赛题模块(二)
【信息安全管理与评估】2024年北京市职业院校技能大赛高职组“信息安全管理与评估”赛题模块(一)
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项例题(六)
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项例题(五)
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项例题(四)
2024年广东省网络系统管理样题第4套服务部署部分
2024年广东省网络系统管理样题第4套网络搭建部分
2024年广东省网络系统管理样题第5套网络搭建部分
2024年广东省网络系统管理样题第5套服务部署部分
2024年广东省网络系统管理样题第3套服务部署部分
2024年广东省网络系统管理样题第3套网络搭建部分
电子好书发您分享《阿里云产 品手册2024版》
2024年广东省网络系统管理样题第2套服务部署部分
2024年广东省网络系统管理样题第2套网络搭建部分
2024年广东省网络系统管理样题第1套网络搭建部分
2024年广东省网络系统管理样题第1套服务部署部分
【信息安全管理与评估】2024年河北省职业院校技能大赛高职组“信息安全管理与评估”赛项规程
2024年河北省职业院校技能大赛高职组“信息安全管理与评估”赛项样题
【网络建设与运维】2023年浙江省职业院校技能大赛中职组“网络建设与运维”赛项规程
【网络建设与运维】2024年浙江省职业院校技能大赛中职组“网络建设与运维”赛项规程
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项例题(二)
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项例题(一)
【信息安全管理与评估】2024年浙江省职业院校技能大赛高职组“信息安全管理与评估”赛项规程
【网络建设与运维】2024年河北省职业院校技能大赛中职组“网络建设与运维”赛项规程
【题目】【网络系统管理】2022 年全国职业院校技能大赛 网络系统管理赛项 模块 A:网络构建
【评分标准】【网络系统管理】2019年全国职业技能大赛高职组计算机网络应用赛项H卷 无线网络勘测设计
【题目】【网络系统管理】2019年全国职业技能大赛高职组计算机网络应用赛项H卷
国家信息安全水平考试NISP一级理论真题答案2
国家信息安全水平考试NISP一级理论真题答案1
【题目】【网络系统管理】2022年甘肃省职业院校技能大赛-网络构建-试卷
【题目】【网络系统管理】2022年江苏省职业院校技能大赛 高职竞赛样题
2022年浙江省职业院校技能大赛信息安全管理与评估 理论题答案
2022年浙江省职业院校技能大赛信息安全管理与评估 理论题一阶段
电子好书发您分享《2023龙蜥操作系统大会主论坛-聚力生态 · 共筑未来》
2022 年浙江省职业院校技能大赛“高职组”“信息安全管理与评估”赛项规程
电子好书发您分享《2023龙蜥操作系统大会阿里云分论坛:释放云算力 繁荣云生态》
电子好书发您分享《2023龙蜥操作系统大会浪潮信息分论坛:智算系统软件分论坛》
2023 年浙江省职业院校技能大赛信息安全管理与评估赛项规程
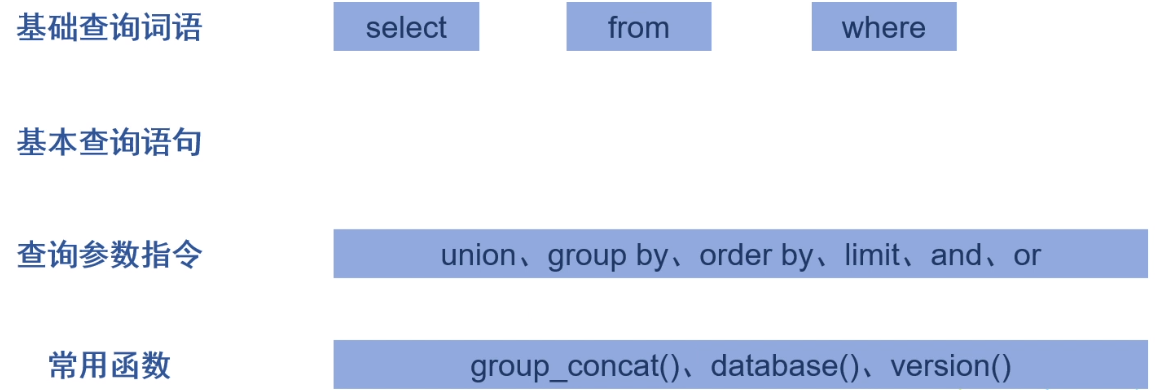
SQL数据库基础语法-查询语句
SQL数据库基础语法-增删改
PWN入门必读
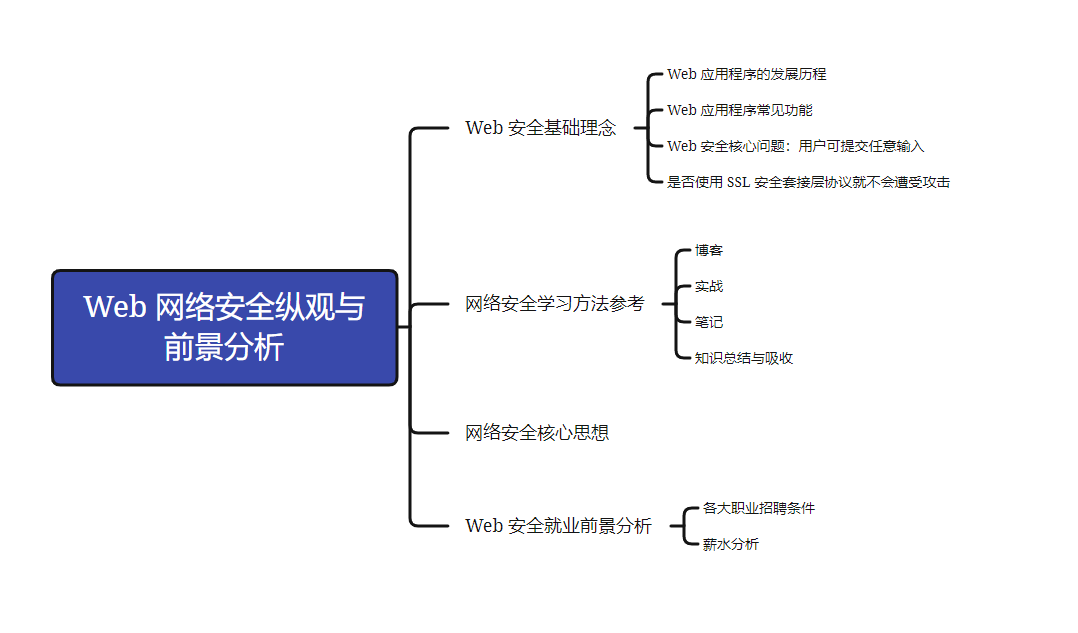
01-Web 网络安全纵观与前景分析
2023-2024年广东省职业院校技能大赛信息安全管理与评估赛项规程
2022年至2023年广东省职业院校技能大赛高职组“信息安全管理与评估”赛项样题
【答案】2023年国赛信息安全管理与评估正式赛答案-模块3 CTF
【答案】2023年国赛信息安全管理与评估正式赛答案-模块3 理论技能