首发地址:https://yq.aliyun.com/articles/65356
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文:

深度学习中的记忆和注意力前沿
作者 Stephen Merity

当你有好的数据集时候,深度学习在图像和文字分类方面可以给出高的精度,这是由于大数据可以很好的训练自己的分类器,而且几乎没有用到经验知识。

对于低年级学生而言,也可以很容易获得好的分类器,图中显示的是给TrashCam创建的一个定制视觉分类器[Trash,Recycle,Compost],精度能够达到90%
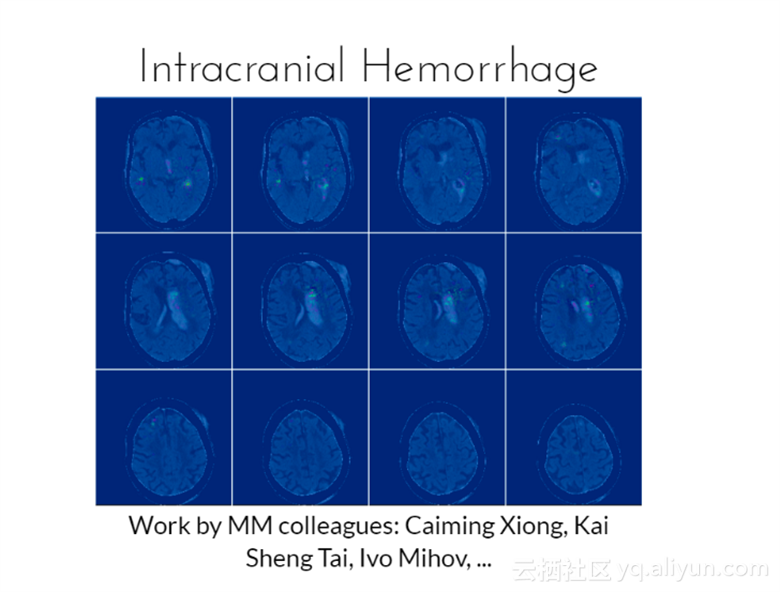
图中是颅内出血的检测,该分类器是由MM大学的 Caiming Xiong,Kai Sheng Tai等人创建,能够很好的识别颅内出血的情况
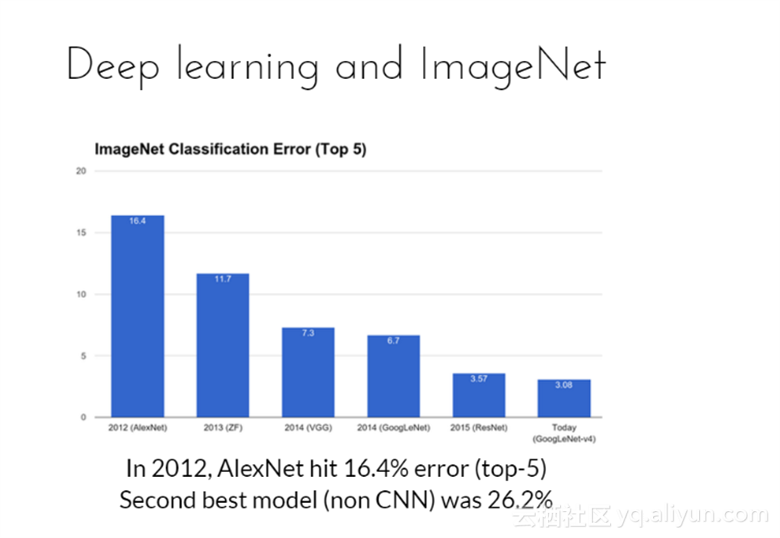
深度学习和ImageNet挑战,在2012年的挑战中,AlexNet网络实现了16.4%的错误率,而最好的第二名网络模型(non CNN)错误率为26.2%,领先第二名接近10%。
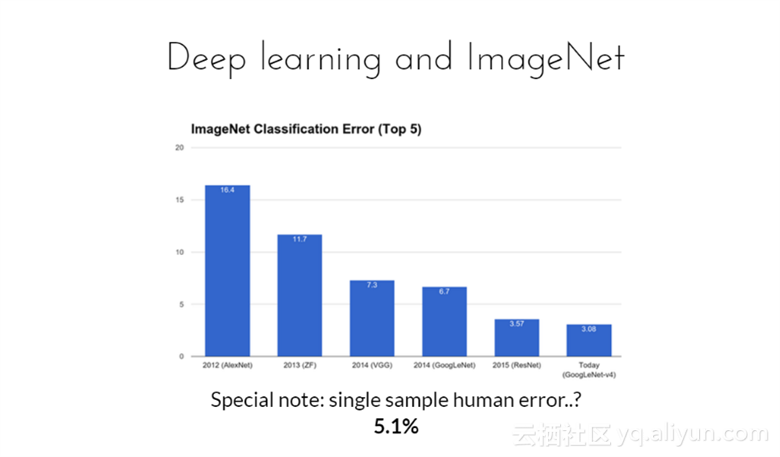
特别注意到,人的识别错误率为5.1%
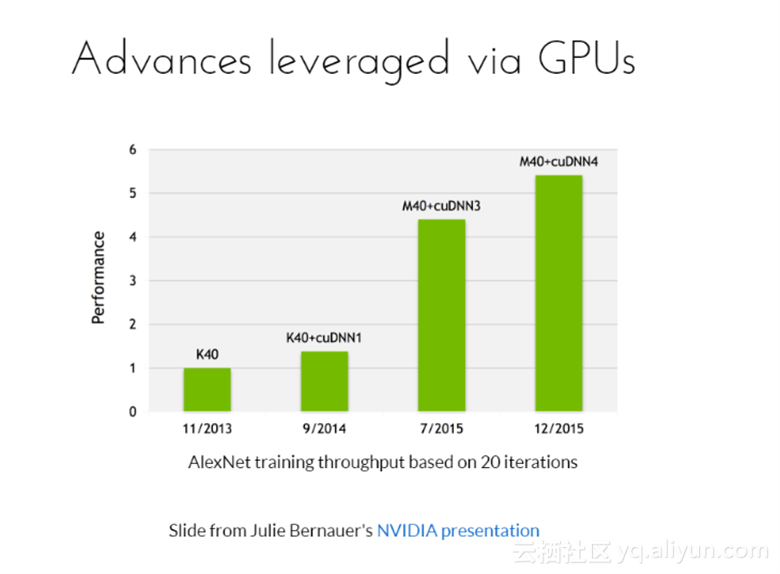
取得这么好的原因很大一部分归功于硬件的发展,从图可以看出,AlexNet网络训练了20个迭代,是通过GPU联合Cudnn加速训练的。

但也不要将深度学习应用到任何地方,在深度学习中,结构工程师是未来新的工程师;这是机器学习,不是魔法。

除了分类之外,可以进行图片内容识别,常用的数据库有VAQ数据库;从图中看到,识别的是一个人在雪地里穿着背着双肩包;
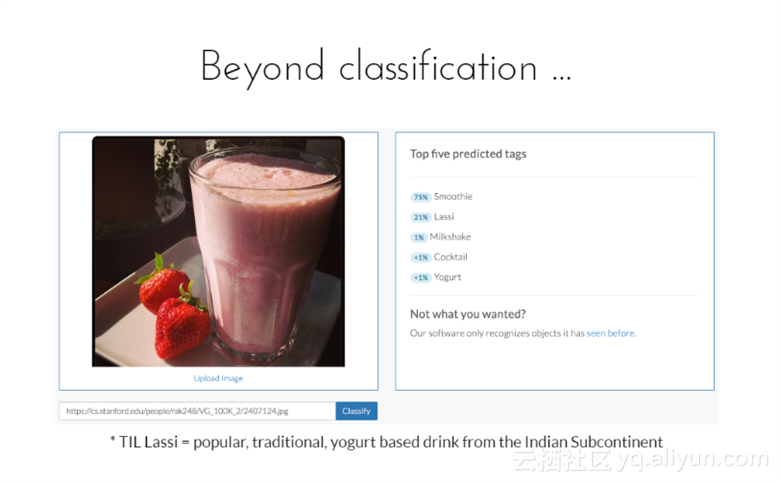
比如识别口味,上传一张照片,然后分析该饮料是哪种口味。如图所示,分析出来的口味有五种,Smoothie、Lassi、Milkshake、Cocktail以及Yogurt。其中为Smoothie口味的可能性为75%,Lassi口味的可能性为21%,Milkshake口味的可能性为1%,其它两种口味的概率低于1%;

自动回答相关问题:图片中有人吗,回答是没有;图片是什么时候拍摄,回答是白天;图片中饮料类型,回答是smoothie等

自动识别:从图中看出,Visual Gennome模型可以识别图中的物体与活动并针对不同问题的回答,比如河流在哪里,回答是在桥下;这座拱桥有几个拱,回答是两个等。

Facebook的 bAbl 数据集是将几种问题回答任务放在一起,从该数据集中提取出来的片段如图所示,可以根据句子回答相应的问题。

人类问答过程
想象下我给你一篇文章或一幅图片,并要求你记住它,之后将其拿走并问你一些问题,及时你再聪明,你也将会获得一个糟糕的分数。这是因为你不能在工作的记忆中存储任何东西;没有一个问题是针对你的关注点的,你关注在一些不重要的细节上是一种浪费
最佳情况:给你一个输入数据,然后问你一个问题,你回答的时候允许尽可能多的扫视数据。

考虑信息瓶颈
你的模型是在哪里被强制使用压缩表示?更重要的是,使用后效果是不是很好?

神经网络,压缩,这些术语我们之前有没有听到过?
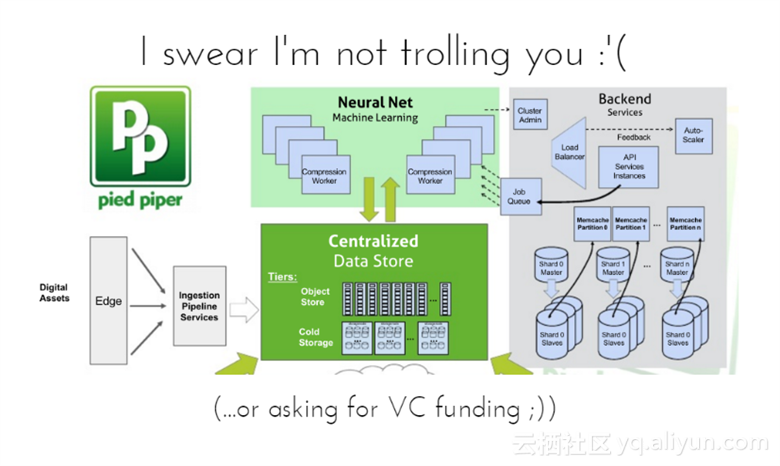
发誓没有引出争议或者是要求风险投资;数字资源的边缘信息送入流水线服务中,中央数据存储与神经网络中的机器学习相互交换数据,后端提供相应的服务。


图中是一个真实的世界,没有人正在做CNN压缩。

除了Magic Pony在做CNN压缩外。MagicPony由帝国理工学院(Imperial College London)几位研究生创立,主要业务是通过大规模神经网络处理视觉信息,特别的地方在于,通过部分无监督学习的方式,基于以前的训练来自行产生图像。简单的说,就在处理过大量碎片化的视频片段之后,算法能够自动生成视频来进行补充,或者增强像素化视频游戏图像的解析度。
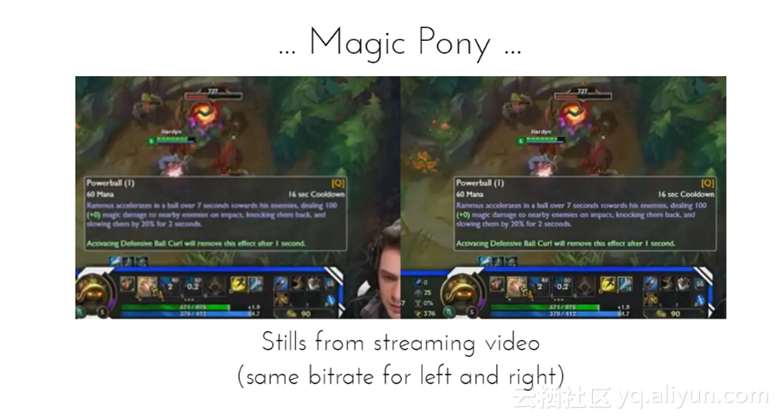
两幅图片来自视频流,左右图像是相同的比特率,而右图比左图稍微清晰些。

现在是bird+Magic Pony,原因是Twitter收购了Magic Pony。这是鉴于Twitter在视频直播方面的巨大资金投入,以及处理这些视频所需的海量储存与计算设备投入。

从压缩的角度考虑神经网络

比如文本向量,将“dog”转化为100维向量;



转化为100维向量的效果如图所示

Word2vec 是 Google 在 2013 年年中开源的一款将词表征为实数值向量的高效工具, 其利用深度学习的思想,可以通过训练把对文本内容的处理简化为 K 维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。Word2vec输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分析等等。如果换个思路,把词当做特征,那么Word2vec就可以把特征映射到 K 维向量空间,可以为文本数据寻求更加深层次的特征表示。文本向量通过word2vec模型,可以识别句子中含“dog”的位置。


CBOW与skipgram是word2vec中的核心概率之一,两个模型都是以Huffman树作为基础的。前者是给出句子,来猜测句子中空的内容;而skip-gram的输入是当前词的词向量,而输出是周围词的词向量。也就是说,通过当前词来预测周围的词。

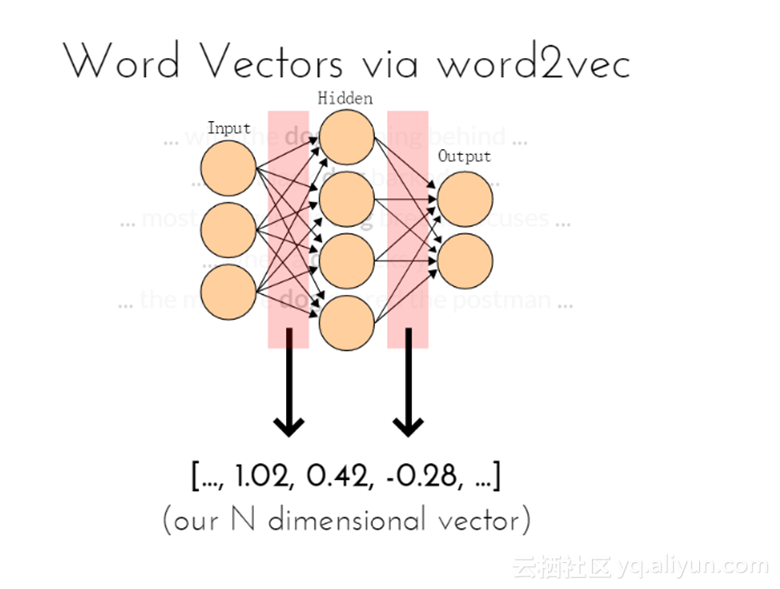
文本N维向量在神经网络中可以看作是隐层之间的连接权重值;
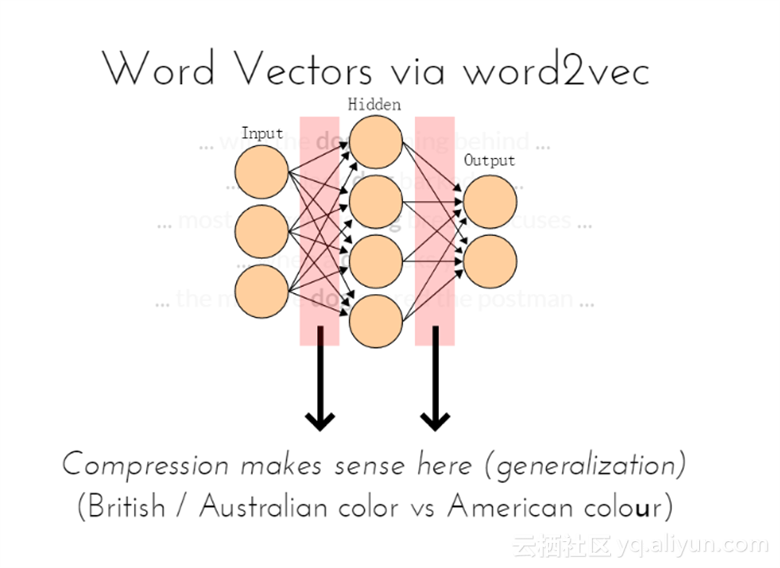
在这里压缩是有意义的(通用化)
英国和澳大利亚的颜色是用color表示,而美国则是使用colour表示;
动词、单复数等问题
通过它周围的单词意思,你可以知道这个单词,
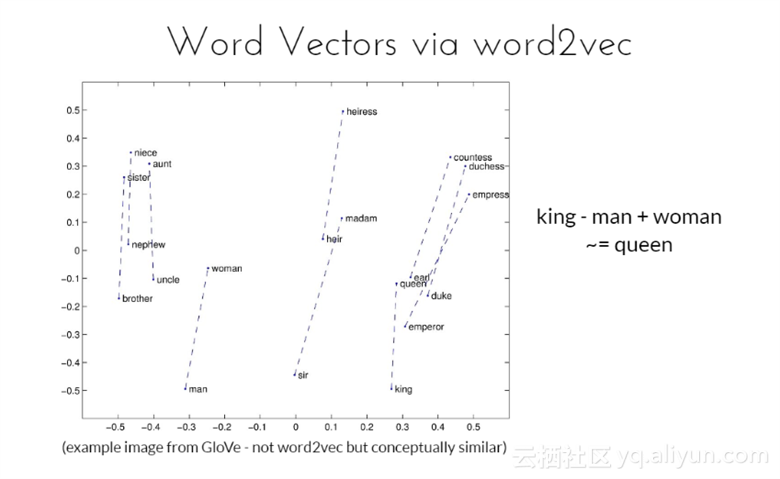
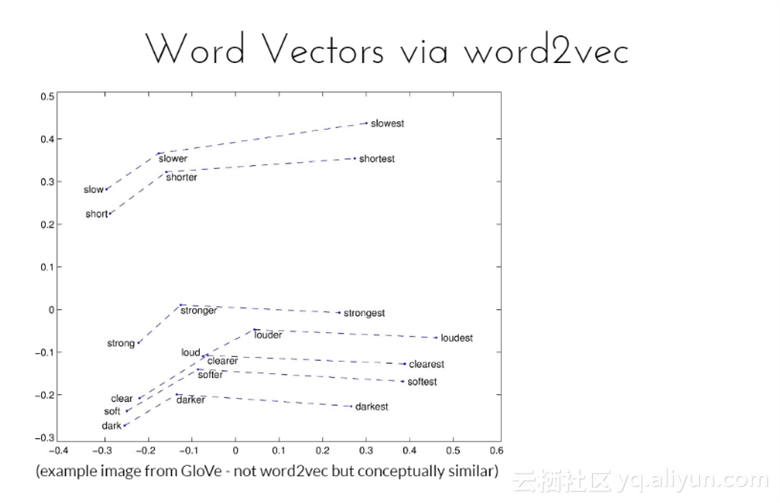
上面两幅图均来自GloVe的示例图片,GloVe与word2vec不同,但是基本概念相似,是一种无监督学习算法获取向量表示的单词。

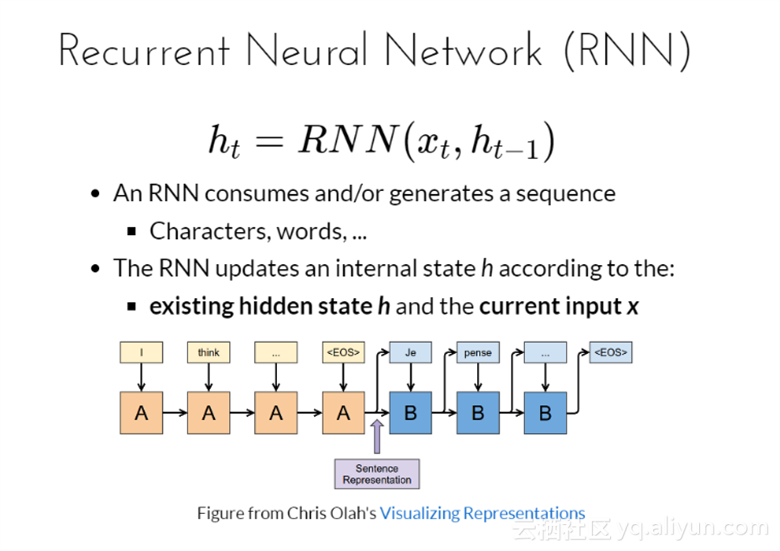
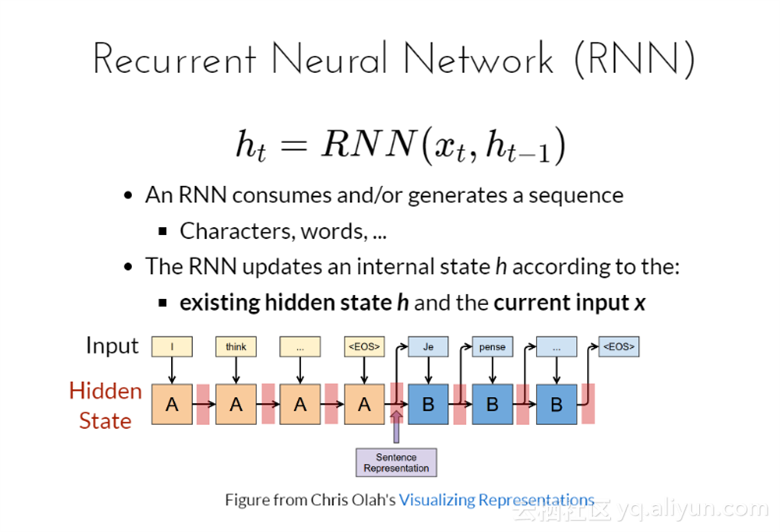
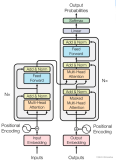
循环神经网络(RNN)
RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
因此有 ![]()
一次RNN消耗会生成一个序列、字母、文本等
RNN是根据现存的R隐层状态h和循环输入x更新内在状态的;
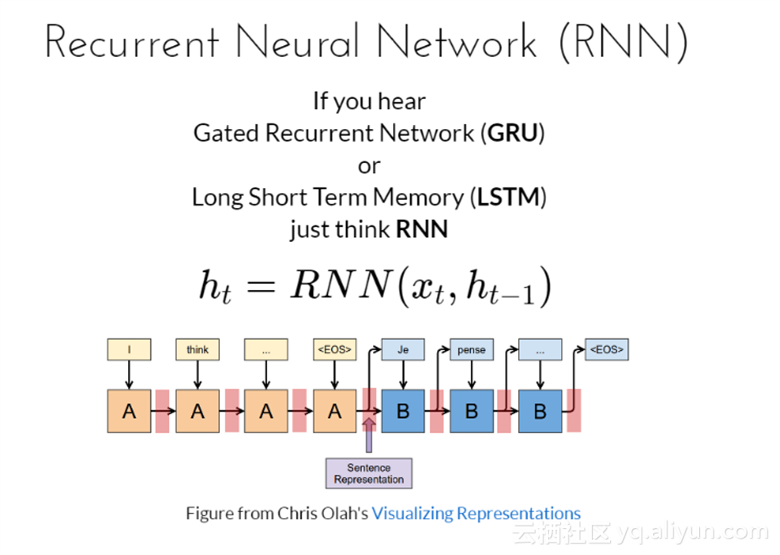
如果你听过GRU网络或者LSTM,这两种网络较RNN而言设计得更加精密,但只需要考虑RNN更新公式
![]()
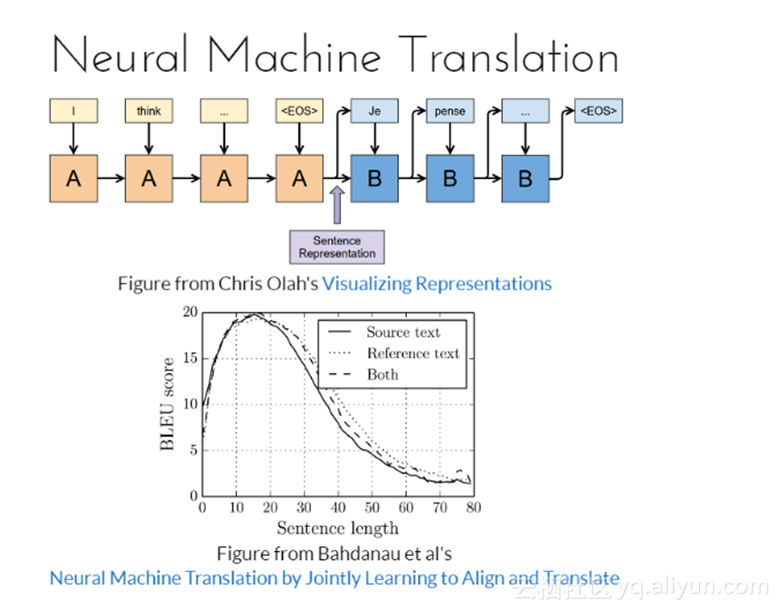
神经元机器翻译通过联合学习以便进行调整和翻译。从图中可以看到,随着句子长度的增加,刚开始时候BLEU分数是逐渐上升的,但超过一定长度后下降得很快,这说明,神经元机器翻译所适合的句子长度不宜较长。

神经元机器翻译
Quora是一个问答SNS网站,由Facebook前雇员查理·切沃(Charlie Cheever)和亚当·安捷罗(Adam D' Angelo)于2009年6月创办。该网站需要用户使用真实名字注册,而不是一个网名(账户名);并且游客不愿意登陆或使用小型文本文件的话必须绕路才能使用该网址。
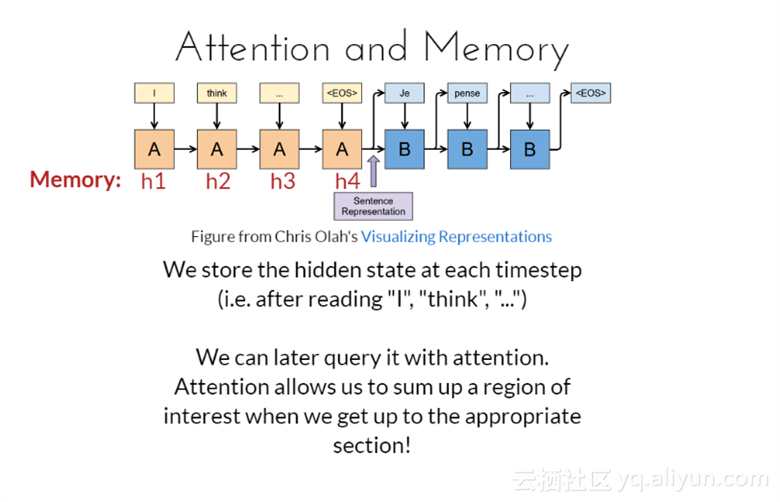
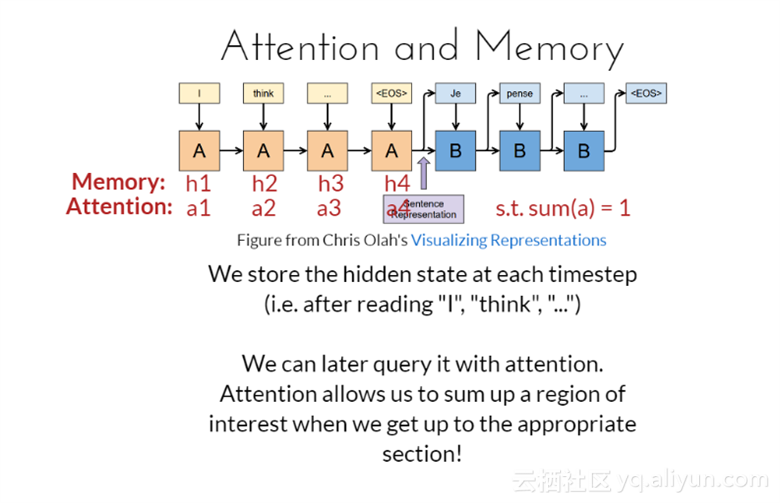
注意力与记忆
在每一时间步都会保存隐藏状态(比如,读了“I”、“think”、“...”);在之后查询相关事情的时候,可以通过之前我们所关注的内容得到。当想到合适部分时,注意力允许我们概括感兴趣的区域。
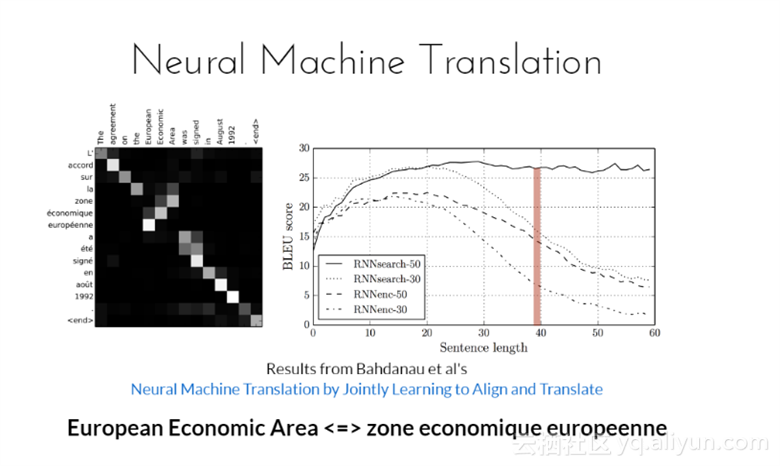
European Economic Area与zone economique europeenne意思等价

1. 针对QA的模块化和弹性的深度学习框架;
2. 能够处理宽范围的任务以及输入格式的能力;
3. 甚至能够针对一般的自然语言处理任务使用(比如非问答、感情、翻译等);

相关的注意力/记忆工作
1. 序列到序列模型是由谷歌研究员Sutskever等人在2014年提出,该模型是将目标序列排列成源序列顺序形式那样;
2. 神经图灵机模型是由Graves等人在2014年提出,该模型主要包含两个基本组成部分:神经网络控制器和记忆库;
3 学习无限的转换模型是由Grefenstette在2015年提出,该模型的性能优于深度RNN模型;
4. 结构记忆感知图灵机模型是由WeiZhang在2015年提出,该模型提出了几种不同结构的NTM内存,其中的两种结构能够导致更好的收敛;
5. 记忆网络模型是由Weston等人在2015年提出,该模型能够实现长期记忆,并且实现如何从长期记忆中读取和写入,此外还加入了推理功能;
6. 端到端的记忆网络模型是由Sukhbaater等人在2015年提出,该模型让记忆网络端到端地进行训练,不考虑任何中间过程。
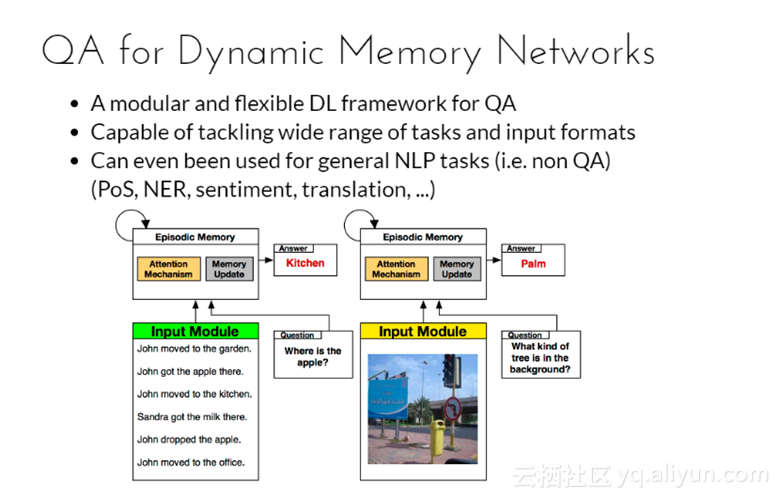
针对动态记忆网络的问答模型
1. 模块化以及灵活的深度学习框架;
2. 有能力处理宽范围的任务和输入格式;
3. 甚至能用来处理一般的NLP任务;
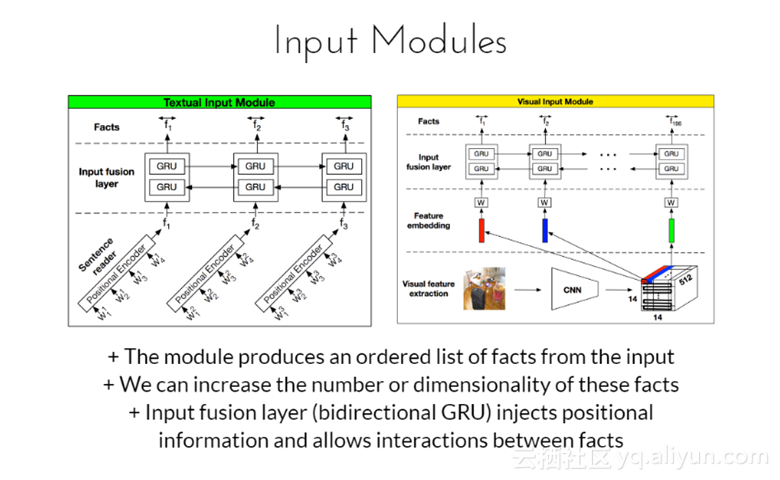
输入模块:该模块根据输入产生有序列表的事实,并且可以增加这些事实的数量或者维数,输入融合层(双向GRU)注入潜在信息并允许事实之间相互作用。
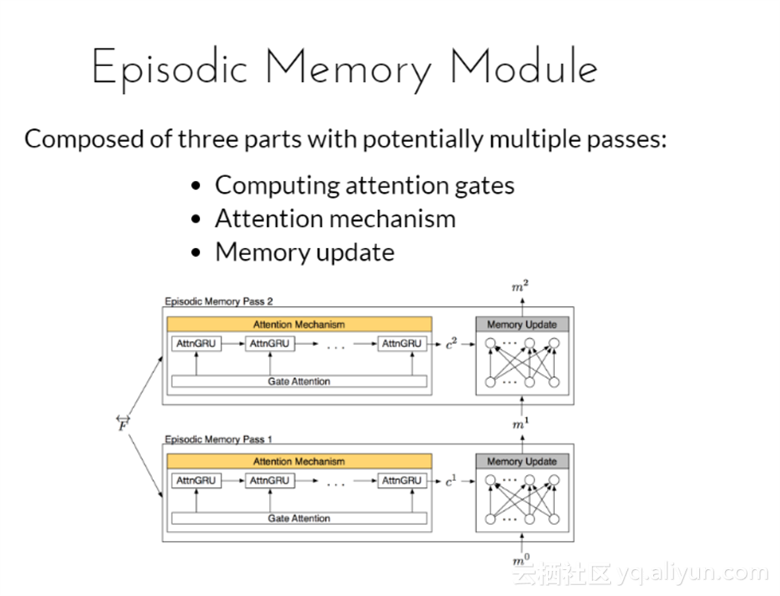
情景记忆模块是由潜在多个通道的三部分组成,分别为注意力门的计算、注意力机制以及记忆更新;

软注意力机制
给定注意力门限,现在想要从输入事实中提取出上下文向量,如果门限值是通过softmax,上下文向量是输入事实的权重总和;
问题:潜在的求和损失以及顺序信息

计算注意力门限
每个事实接受一个大小为[0,1]之间的注意力门限值,该值是通过分析[事实、疑问以及情景记忆]得到,通过在注意力值上使用softmax强制性执行稀疏。
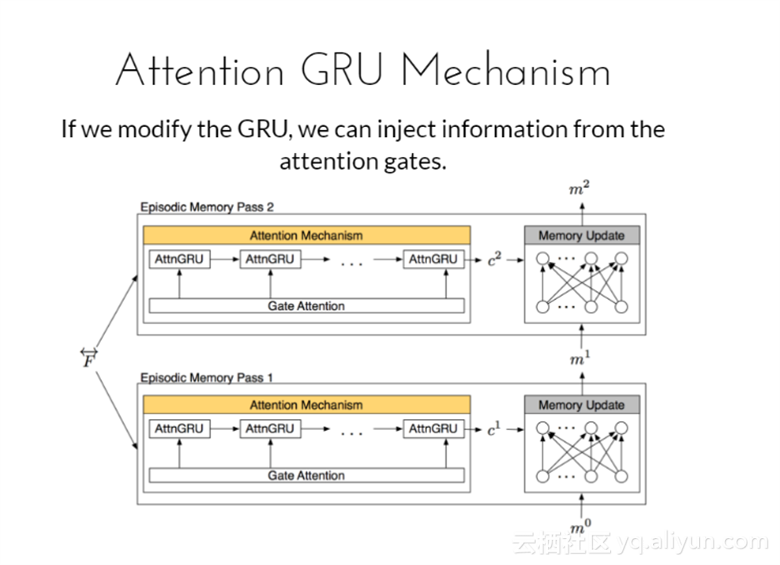

注意力GRU机制
如果修改GRU,我们能够通过图中式子将信息从注意力门限中注入,通过激活门限g代替更新门限u,更新门限能够利用好问题和记忆。

结果
关注三个实验,分别为文本、视觉以及注意力可视化;
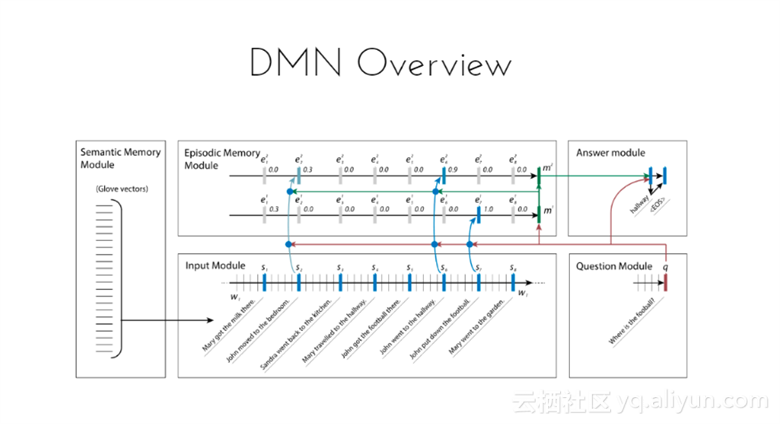
动态记忆网络概览
该框架由Semantic memory模块、Input模块、Episode memory模块、以及Answer模块和question模块组成,首先从Input模块接受未加工的输入,之后生成问题的表示,再将问题以及显性基础知识一起传送给Episode memory模块,该模块会推理得到一个回答。
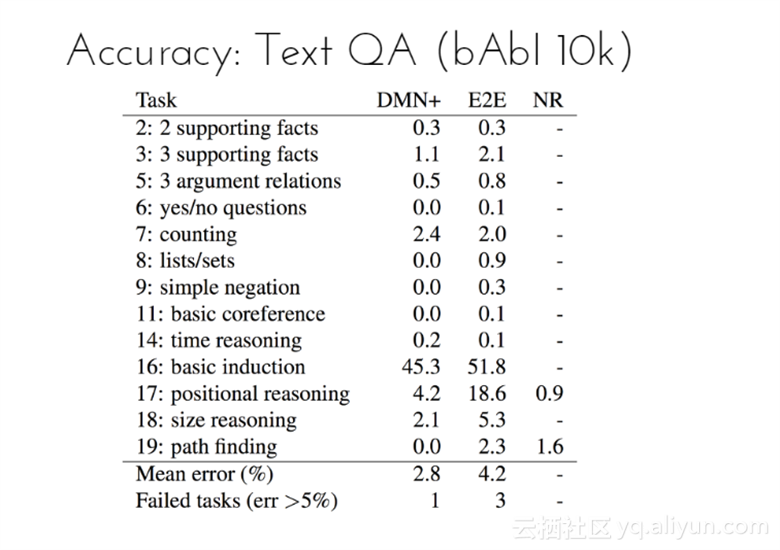
在上下文问答中的准确率(bAbI 10k数据集),可以从表格中看到,DMN+模型的平均错误率为2.8%,远小于E2E模型的4.2%;任务失败(错误率大于5%)次数为1,而E2E模型的次数为3。

视觉问题回答的精确度
如图所示,可以根据图片中的内容回答相关问题,比如图中公交车的主要颜色,回答是蓝色等。
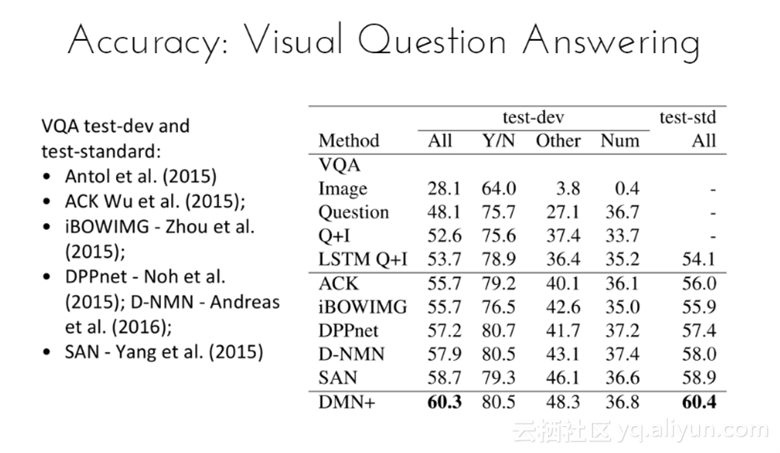
VQA test-dev和test-standard有如下几人提出的标准:
2015年有Antol、ACK Wu、iBOWIMG -Zhou、DPPnet-Noh以及SAN-Yang等人;2016年有D-NMN-Andress。
测试结果表明,DMN+模型对于所有的测试标准结果最高,为60.4%,领先第二名1.5%;对于所有的测试-dev而言,DMN+模型的结果也是最高,为60.3%,领先第二名1.6%。

当知道被问的问题时,我们能够提取的只是相关信息,这意味着我们不计算或存储不必要的信息,更加有效并能帮助我们避免信息瓶颈。

指针网络
如果你是在外国并且你正在点餐,你可以在菜单上看见你想要的,但是你不会发音,这种情况下指针网络能够帮助你解决词汇问题。(大多数的模型仅限于预先建好的词汇表)
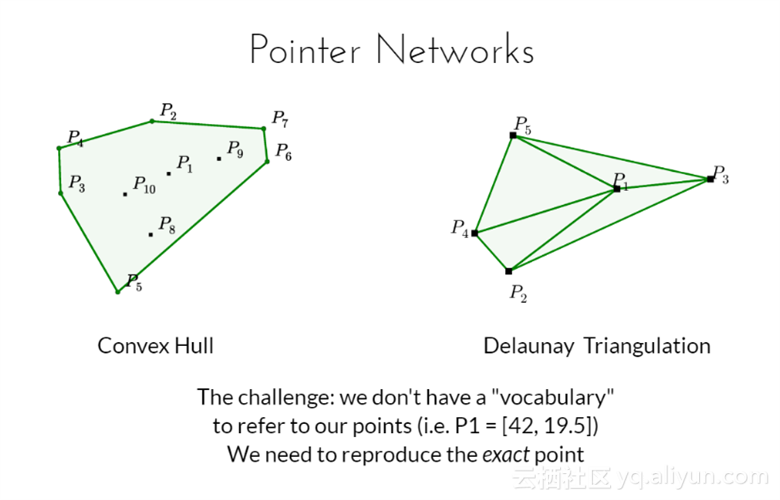
挑战:我们没有词汇去指向指针,需要重现准确的指针。
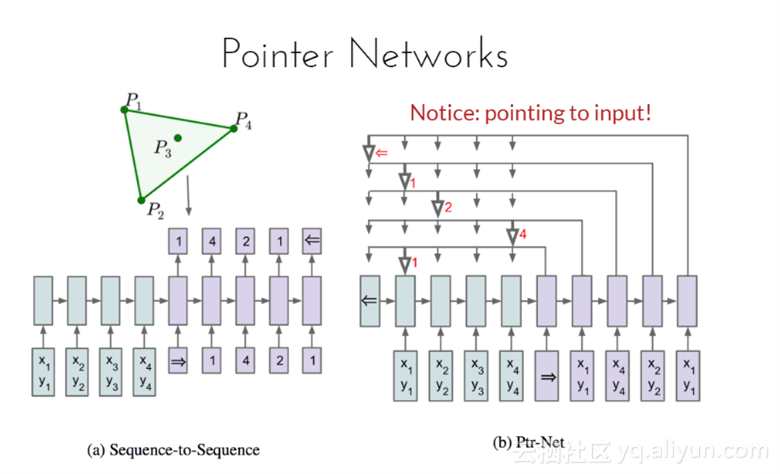
上图(a)蓝色部分是RNN处理输入序列,{(x1,y1), (x2,y2),(x3,y3),(x4,y4)},右面紫色是输出序列,表示解的序列顺序{1,4,2,1};上图(b)输出则直接是调整顺序后的序列{(x1,y1), (x4,y4),(x2,y2),(x1,y1)},(序列顺序同样是(1,4,2,1))
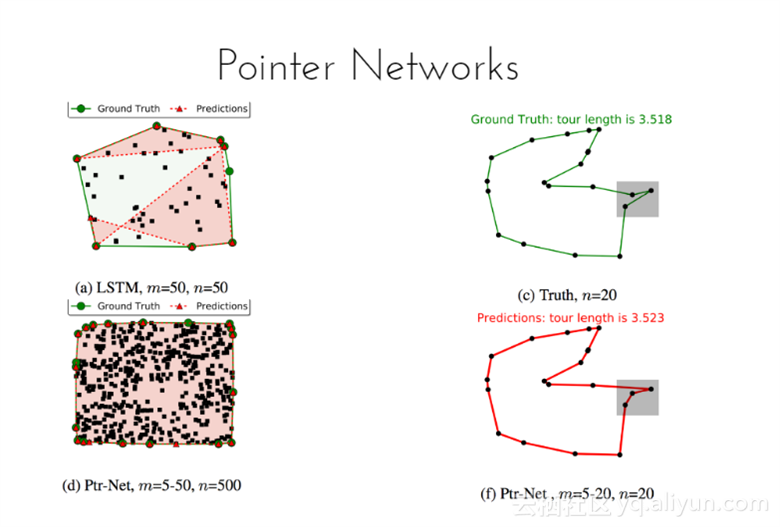
从图中可以看到,Ptr-net比LSTM的预测巡回线长。
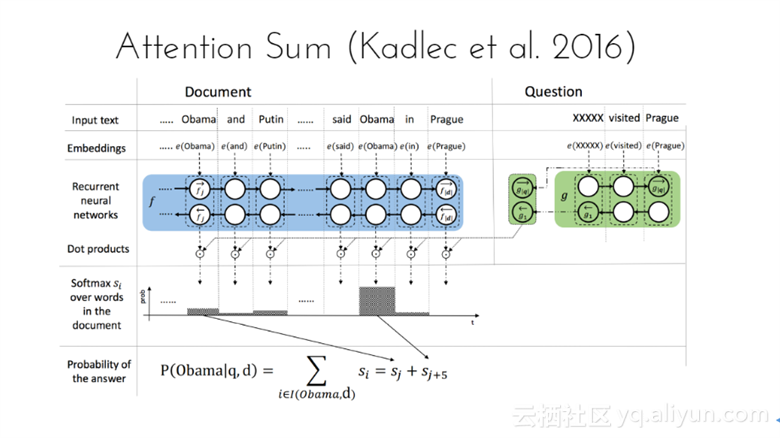
首先通过Embedding层将document和query中的word分别映射成向量;之后对其编码得到文本表示;每个word vector与query vector作点积后归一化的结果作为attention weights;最后做一次相同词概率的合并,得到每个词的概率,最大概率的那个词即为answer。

指针网络避免存储冗余的数据,这是很重要的,因为在许多任务中,名字是一个占位符,文档占位相当的长。
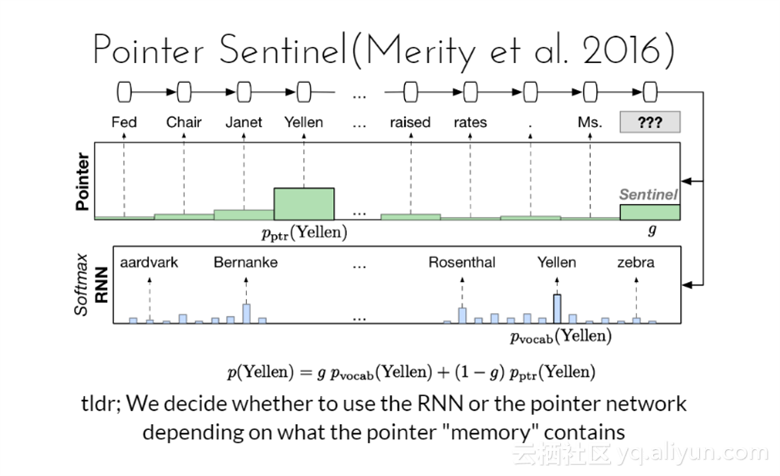
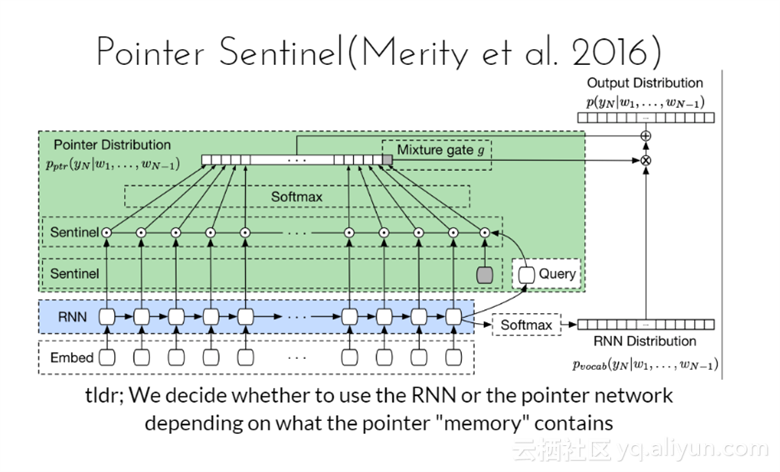
决定是否使用RNN或者指针网络,这是取决于指针“存储”包含的内容。

Pointer Sentinel-LSTM模型在语言建模上最先进的结果
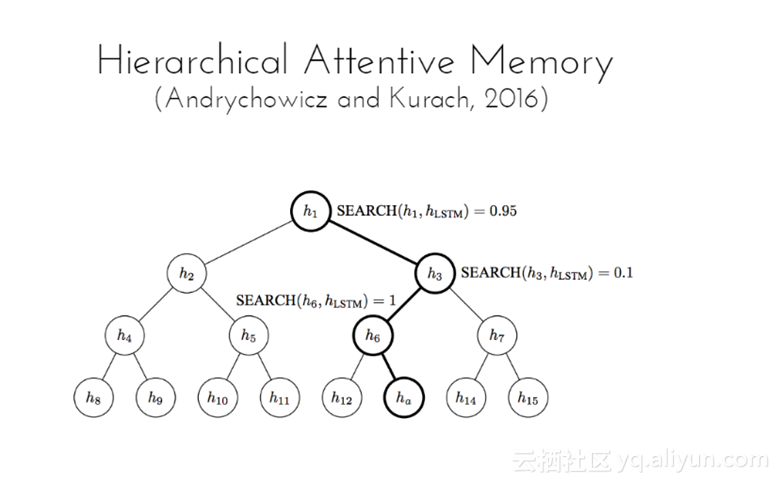
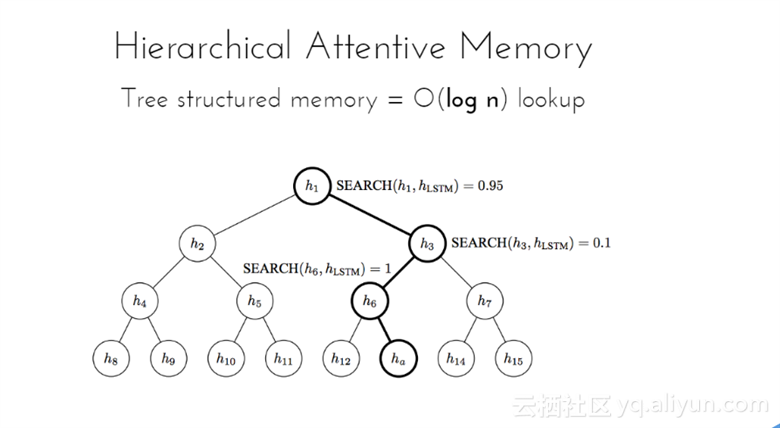
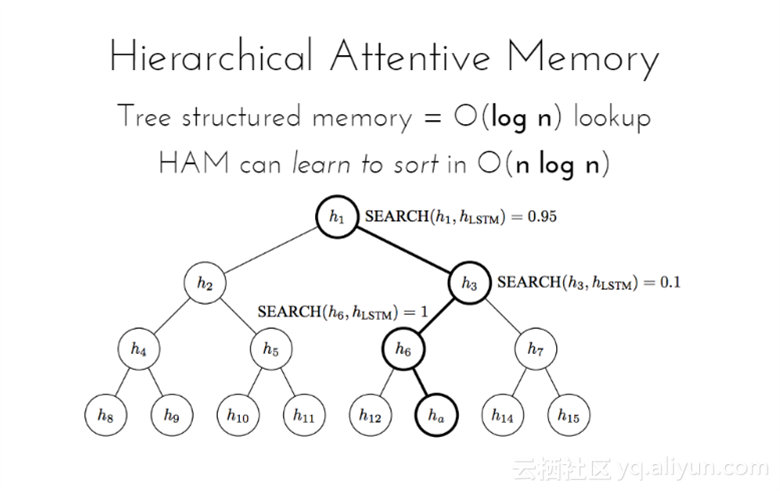
Hierarchical Attentive Memory模型是基于二叉树与记忆细胞。该模型的复杂度为O(log n),学会排序n个数字所需要的时间为O(nlogn)。

深度学习发展非常迅速,如果你停止不前或者左顾右盼的话,你可能会错过它;

对于深度学习感兴趣的话,我强烈推荐Kears模型,该模型是一个极度简化、高度模块化的神经网络第三方库。基于python+Theano开发,充分发挥了GPU和CPU操作。其开发目的是为了更快的做神经网络实验。适合前期的网络原型设计、支持卷积网络和反复性网络以及两者的结果、支持人工设计的其他网络、在GPU和CPU上运行能够无缝连接。
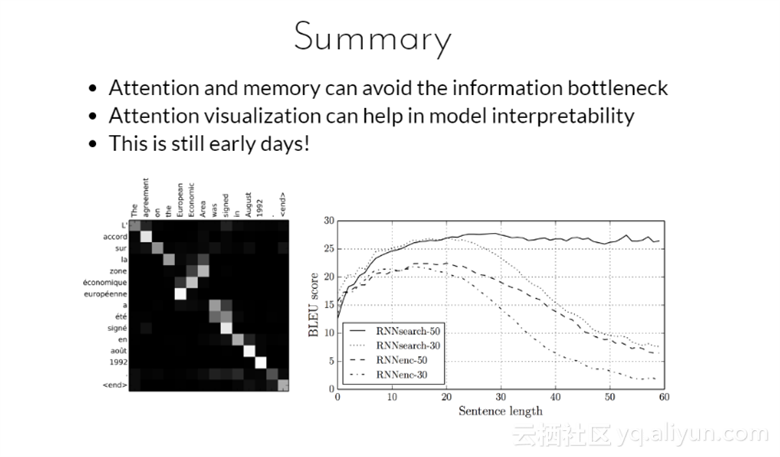
总结
1. 注意力以及记忆能够避免信息瓶颈;
2. 注意力可视化能够有助于在模型上的可解释性;
3. 这些仍然处于初期阶段;
文章原标题《The Frontiers of Memory and Attention in Deep Learning》,作者:Stephen Merity
文章为简译,更为详细的内容,请查看原文