本节书摘来自华章计算机《高性能科学与工程计算》一书中的第3章,第3.5节,作者:(德)Georg Hager Gerhard Wellein 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.5 算法分类和访存优化
在基于cache的处理器上,许多循环的优化潜力可以通过观察某些基本参数(像数据传输、算术运算和问题规模的伸缩性)很容易地估算出来。从而进一步确定优化的努力是否有意义。
3.5.1 O(N)/O(N)
如果算术运算量和数据传输量(加载/写入)与问题规模(或者“循环长度”)N成比例,那么优化潜力是非常有限的。标量乘、向量加和稀疏矩阵向量乘都是这类问题的典型实例。当N取值较大时,其性能不可避免地受访存限制,并且使用编译器生成的代码就可以达到较高的性能。这是因为O(N)/O(N)循环往往很简单,正确的软件流水策略的作用非常明显。但是嵌套循环是一个不一样的问题(具体见下面的分析)。
然而,即使循环不嵌套,优化空间还是经常存在的。作为一个实例,考虑下面的向量加代码:

左边代码的每一个循环都没有优化空间。每个循环包含两次数据读取操作、一次数据写入操作和一次加法操作(没有计算写分配),因此循环代码均衡值为3/1。然而,数组B在第二个循环中被重新加载了一次,这是非常没有必要的:将两个循环整合为一个,数据B的元素就可以只被读取一次,循环代码平衡值降为5/2。在其他条件都一样的情况下,代码性能(访存受限)将会提高6/5(如果写分配时不可避免,这个值将是8/7)。
对于这两个循环来说,循环整合实现了O(N)的数据重用,减少了一个数组的数据读取操作。像这种简单情况,编译器一般会自动使用该优化方法。
3.5.2 O(N2)/O(N2)
典型的循环长度为N的两层嵌套循环中,有O(N2)算术运算操作和O(N2)数据读取和写入操作。稠密矩阵向量乘、矩阵转置以及矩阵加都是这类问题的典型实例。尽管内层循环的情况和O(N)/O(N)相似,并且都访存受限,但嵌套却开启了新的优化空间。然而,优化又一次仅限于一个常数因子的改善。考虑下面的稠密矩阵向量乘(Matrix-Vector Multiply, MVM)代码:
上面代码的代码平衡值为1W/F(矩阵A、B两次数据读取和两次算术运算)。数组C由外层循环变量索引,所以其更新可以在寄存器中进行(这里我们通过使用标量tmp来说明,尽管编译器可以自动进行这些转换),从而不计算其读取和写入操作。矩阵A只被加载一次,但是B却被加载了N次(见图3-11,外层循环每迭代一次,B就被加载一次)。我们可以采用上节所讲的循环整合方法,但是这里需要整合的内层循环有N个而不是两个。解决方案是循环展开:外层循环间隔m遍历,内层循环重复m次。我们必须要面对外层循环长度不能被m整除的情况。在这种情况下,要单独处理剩余的循环。
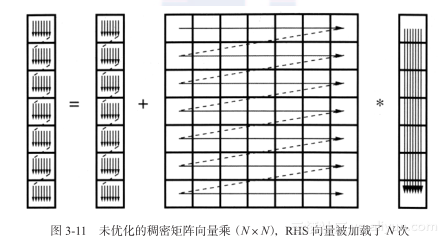

“剩余循环”可以采用同原始循环一样的优化方法,但这不重要了。我们在下面的讨论中将忽略这些“剩余循环”。
仅应用外层循环展开方法,除了代码膨胀外我们什么也没有得到。然而,现在可以非常容易地使用循环整合方法了:
将外层循环展开,然后整合通常称为展开与合并(unroll and jam)。m路展开与合并实现了寄存器中B每个元素的m次复用,代码平衡值减小为(m+1)/2m。当m>1时,该值显然小于1。如果m取值非常大,由于B加载的次数大为减少,因此可获得接近两倍的性能提升。在理想情况下,B只需加载一次。因为A(大小为N2)只需加载一次,m路展开与合并的总数据传输量为N2(1+1/m)+N。图3-12显示了两路展开的稠密矩阵向量乘的访存模式。
冲突被大约降低了一半,剩余的循环在外层调用本例
然而,所有这一切都假设寄存器的压力不会太大。即假设CPU有足够多的寄存器来容纳循环体内部数量相当可观的操作数。如果不能,编译器必须溢出寄存器数据到cache中,这样会降低计算性能(见2.4.5节)。再一次强调,可用的编译日志可以帮助确定这种情况。
循环展开与合并在高级别优化上可由有些编译器自动实现。一个复杂的循环体可能会隐藏一些重要的优化信息,因此手工优化是必需的:通过手工优化或者编译器指令来指定像循环展开等高级别转换。如果可用,编译器指令是首要选择的优化方法。这是因为指令比较容易维护且不会导致明显的代码膨胀。可惜的是,编译器指令本质上是不可移植的。
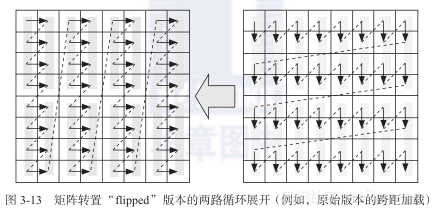
尽管同稠密矩阵向量乘相比,上节所讨论的矩阵转置算法没有直接机会优化数据传输(两个矩阵只需读写各一次),该算法同样是O(N2)/O(N2)问题的典型实例。通过在矩阵转置算法的“flipped”版本上应用循环展开与合并方法,得到了将近50%的性能提升(参见图3-8的虚线)。
不要期望m = 4时会有明显效果,因为基本性能分析没有发生变化:当N取值中等时,可用的cache行数目足够可以容纳Lc列数据。图3-13显示了m = 2的情况。每一次加载操作中,cache行中的m个元素可以连续访问。因此,尽管TLB依然太小而不能映射到整个工作集,但还是减少了TLB未命中。
尽管如此,当N取值较大从而使cache不能容纳N个cache行的数据时,减少TLB未命中并不能阻止性能的下降。最好能有一个策略重用非连续cache行剩下的Lc-m个元素,从而使cache行可以很快替换出去而不需要再次加载。一个“野蛮”方法是Lc路循环展开,但是这个方法会导致写操作时更大间隔的非连续访问。同时,由于循环展开因子过大,导致循环体中寄存器使用量的增加(算术操作引起的),因此这并不是一个通用的优化方法。循环分块(loop blocking)能够在不增加寄存器使用的情况下实现cache的最优使用。该方法不会减少数据读取或者写入操作,但是会增加cache的命中率。对于深度为d的嵌套循环,分块引入了d个额外的外层循环,将原来的内层循环切分成块:
" >

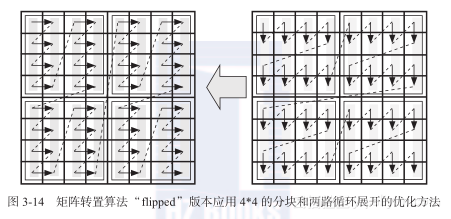
在这个例子中,除m路的循环展开与合并外,使用了二维分块(分块因子为b)方法。这个变化并没有改变主循环体,因此并没有改变保存操作数的寄存器数目。然而,却极大改进了cache行的访存模式,如图3-14所示,两路循环展开与4 4分块的结合。如果分块因子选择恰当,那么非连续写操作中的cache行将会在每一个分块的最后得到充分利用,而且会快速地置换出去。因此,N取值较大时的性能下降现象将不复存在。图3-8的虚线说明了5050的分块结合4路循环展开消除了非连续内存访问带来的所有访存问题。
循环分块是非常普遍和强大的优化方法,并且编译器不会自动执行。最佳分块因子应该通过精心的基准测试实验获得。然而,cache的大小也可以指导最佳分块因子的选择。即,当对L1 cache分块时,内层循环中所有分块的大小总和不应该超过cache大小的一半。究竟对哪一级cache进行分块依赖于具体的算术操作,这里没有通用的指导建议。
3.5.3 O(N3)/O(N2)
如果算术计算量随着问题规模的扩大以一定的因子增长而大于访存数据量,那么这类算法具有巨大的优化空间。通过上述优化技术(循环展开与合并、循环分块)的使用,这类算法性能可能不会受cache限制。这类算法展现了O(N3)/O(N2)特征,稠密矩阵矩阵乘(Matrix-Matrix Multiplication,MMM)和稠密矩阵对角化是这类算法的典型实例。开发一个精心优化的MMM程序已经超过了本书的范围,更不用说特征值计算。但是我们可以通过一个简单的实例(实际O(N2)/O(N)类型)来说明这类算法优化的基本原理。
上面代码的数据集大小为O(N),但是却进行了O(N2)运算(额外调用了foo()函数)。其中B从内存中被加载了N次,所以总存数据传输量为N(N+1)。使用m路循环展开与合并优化方法后,可将其减少到N(N/m+1)。但是循环展开因子过大的缺点在上节中已经指出。而内层循环的分块(分块大小为b)有两个作用:

- B从内存中仅加载一次,可使b足够小以使b个元素可以加载到cache中,直到不需要它们为止。
- A加载N/b次,而不是一次。
尽管A通过cache被加载了N/b次,但当前B分块被置换出cache的可能性非常低。这是因为根据LRU置换算法,当该cache行被频繁使用时是不会被置换出去的。这使得内存传输非常高效:共传输N (N/b+1)个字。因为b的取值可以比典型循环展开因子大许多,所以分块是最好的优化策略。此外,循环展开与合并方法依旧可以用来增加cache内部(in-cache)的代码平衡值。基本的N2依赖还是存在的,但是结合前因子可以说明内存受限和cache受限程序的差异。当内存带宽和访存延迟不是性能限制因素时,该代码是cache受限的。cache受限代码在特定架构上能否达到预期性能目标依赖于cache大小、cache和内存间的数据传输速度,当然还有算法本身。
O(N3)/O(N2)算法是经过精心优化、其性能可以接近硬件理论峰值性能的典型候选算法。如果循环分块和展开因子选择恰当,则对于N×N的矩阵(当N取值不会过小时),稠密矩阵向量乘的性能经常会达到峰值性能的90%。系统厂商会提供该算法的高度优化版本,一般包含在BLAS(Basic Linear Algebra Subsystem,基本线性代数子系统)库中。既然循环分块已经完成了将代码转化为cache受限的绝大部分重要工作,为什么还要应用循环展开方法?这是因为即使所有的数据都位于cache中,但许多处理器架构在每个时钟周期内也不能持续维持足够的加载和写入操作来满足算术运算的需要。例如,当前英特尔的x86架构处理器每个时钟周期内只能进行一次数据加载和一次写入操作,这就使得当内核的循环嵌套使用多于一个数据加载操作时(特别是上例中O(N2)/O(N)算法的cache受限分块),就需要使用循环展开与合并方法。
这里的讨论是出于教育目的,因此没有必要手工编写和优化标准线性代数和矩阵操作。这些函数一般总是从高度优化的函数库中调用。尽管如此,这里讨论的优化方法是能够应用到许多实际代码中去的。稀疏矩阵向量乘就是一个有趣的例子(见3.6节)。
