本节书摘来自华章计算机《高性能科学与工程计算》一书中的第2章,第2.5节,作者:(德)Georg Hager Gerhard Wellein 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.5 C++优化
目前,有大量关于如何编写高效C++代码的文献[C92,C93, C94, C95]。我们的目标不是取代它们。所以我们特意忽略了引用计数、写时复制、智能指针等关键技术。本节以循环代码为例,根据我们的经验指出C++编程中经常存在的性能错误和误解。
C++编程存在着一个根深蒂固的假象:编译器应该能够识别高级C++程序包含的所有抽象和代码混淆。首先,C++是一门支持复杂管理的高级编程语言,且自身特征明显(如运算符重载、面向对象、自动构建/销毁等)。然而,这些特征绝大多数都不适合编写高效的低层次代码。
2.5.1 临时变量
C++具有一个“隐式”的编程风格:自动机制为程序员隐藏了C++编程的复杂性。然而,在表达式含有运算符重载链时,经常会出现一个问题。例如,假设有一个表示三维向量的类vec3d,该类实现了算术运算符重载以支持更有表现力的编码:

这里我们只给出了vect3d::operator+和友元函数vect3d::operator*(与一个标量相乘)的实现。其他有用函数都以类似的方式定义。注意这里只给出了复制构造函数和赋值运算符的函数声明,这两个函数都是隐式定义的。因为对于这个类来说,默认的复制和赋值操作已经足够了。
下面代码段作为一个启发式的例子,说明了当类被调用时,背后究竟发生了什么:
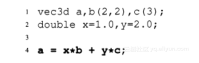
在这个实例中,会按顺序逐步发生如下操作:
1)调用构造函数实例化a、b、c、d对象(根据参数调用相应的构造函数)。
2)调用operator*(x, b)函数。
3)调用构造函数初始化operator*(double s, const vec3d& v)中的tmp变量(这里,我们没有使用默认构造函数,而是选择了更加高效的接受三个参数的构造函数)。
4)因为在函数operator*(double, const vec3d&)返回时,tmp变量会被销毁。所以vect3d的复制构造函数被调用,以创建一个临时变量存储tmp结果,并将其作为“加”运算的第一个参数。
5)调用operator*(y, c)。
6)调用构造函数初始化operator*(double s, const vec3d& v)中的tmp变量。
7)因为函数operator*(double, const vec3d&)返回时,tmp变量会被销毁。所以vect3d的复制构造函数被调用,以创建一个临时变量存储tmp结果,并将其作为“加”运算的第二个参数。
8)第一个临时对象调用vec3d::operator+(const vec3d&)函数,第二个临时对象作为其参数。
9)调用默认构造函数,初始化vec3d::operator+函数中的tmp对象。
10)调用vec3d的复制构造函数,完成运算结果的临时拷贝操作。
11)调用vect3d的赋值运算符,临时拷贝作为其参数。
尽管编译器可能会使用所谓的返回值优化消除本地变量tmp[C92],而直接使用隐式临时变量而不是tmp。然而,完成一个看起来如此简单的表达式所要执行的代码数量是如此的复杂(使用调试工具可查看相关详细信息)。对此,一个直接的优化策略是使用复合计算或赋值运算符(以牺牲可读性为代价),如+=:
这里仍然需要两个临时变量将operator*(double, const vec3d&)函数的结果返回到主函数。但是它们直接被赋值运算符和vec3d::operator+=应用,这样就不需要第三个临时变量。该优点在较长操作链中体现得更加明显。
然而,即使处理临时变量(比如,调用复制构造函数)消耗了大量的计算时间,标准函数剖析文件(见2.1.1节内容)也不一定能将此清楚显示。C++编译器非常擅长函数内联,由此会引发许多“神奇”的事情:比如一个包含复杂表达式函数的独立运行时间。在这种情况下,禁用函数内联功能(虽然一般情况下不支持这么做)可能会得到更多的信息。然而这样会严重干扰剖析结果。
尽管会积极使用内联功能,编译器也不太可能生成“最优”代码。其生成的代码大致上是这样的:
表达式模板(expression template)[C96,C97]是一种先进的编程技术,应该可以解决很多临时变量引发的性能问题。实际上,通过高级表达式它也会生成这样的代码。
应该明确的是,C++内联功能不是为了生成最优代码,而是要弥补因语言规范导致的最严重的性能损失。受内存带宽甚至cache带宽或者算术吞吐量限制的循环代码,最好用C或者Fortran编写(2.5.3节将进行详细讨论)。
2.5.2 动态内存管理
C++代码中另一个常见的性能瓶颈是频繁的内存分配和释放。上节讨论的vec3d类,由于没有涉及动态内存,所以不存在大量内存分配(释放)的问题。如果我们选择一个类似于vec3d但所占内存空间可变的类,其构造函数和析构函数会分别调用malloc()和free()函数。因此,临时变量对性能的影响会更加严重。而标准库函数并没进行最佳性能优化,因此会严重损害程序的整体性能。这就是C++程序员竭尽全力试图减小内存分配和释放对性能影响的原因。
上节讨论的是避免临时变量而采取的其中一个关键措施。除此之外,还有另外两个有效策略:延迟构造和静态构造。这两个策略看起来是对立的,但它们都是有用的策略。
1.延迟构造
将C++作为“第二语言”的C程序员一般会在函数的开始就声明所有变量,而不是需要时才声明。前者是C语言所需的,只要使用的是基本数据类型就不存在性能问题。然而,要尽量避免“昂贵”的构造函数如下所述:
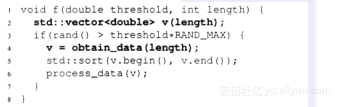
尽管使用变量v的概率可能会非常低(依赖于threshold),但第2行代码还是无条件对变量v进行了声明。一个更好的方案是在需要它时再声明:
这样编写代码的另一个好处是:可以直接调用std::vector<>(第3行)的复制构造函数。而不像之前那样:首先调用构造函数(带int型参数),然后再调用赋值运算符。
2.静态构造
如果对象的使用非常频繁,将其构造放在循环或者代码块的外面,或者声明为static变量,其性能可能会比延迟构造要高得多。如上例,如果数组的长度是个常量且threshold值接近1,那么静态分配可使构造开销忽略不计(因为只构造一次)。

向量对象只实例化一次(第4行),并且没有后续分配开销。然而,如果向量长度可变,那么内存不得不重新分配,从而产生了和正常构造相同的开销(见习题2.4)。一般情况下,如果赋值操作比内存分配快(平均值),则静态分配性能会更高。
并行程序中存放在共享内存的静态数据要特别关注,详细内容见6.1.4节。
2.5.3 循环与迭代器
循环(或者循环嵌套)在科学应用程序的运行时中占主导地位。编译器对这些循环的优化能力是获得高性能代码的关键。运算符重载可能会对编程带来很多便利,但不利于循环优化。下面的例子中,模板函数sprod<>()实现了两个向量的内积。

在代码第7行,const T& vector::operator[]被调用了两次,分别获得向量a和b的相应分量。STL定义这个操作的方式如下(改编自GNU ISO C++库代码):

尽管代码看起来足够简单,可以有效内联。然而,目前编译器拒绝为上例中的求和循环进行SIMD向量优化。一个单一的抽象层(索引运算符的重载)就可以阻止最优循环代码的生成(我们甚至都没有提及第3章中列举的更复杂、更高层次的循环转换)。然而,当使用迭代器进行数组元素访问时,向量优化将不是问题:

因为vector::const_iterator是const T*,所以编译器认为这是正常的C代码。在C++编程中,使用迭代器进行数据访问是一个有效的优化方法。如果有可能,低层次循环代码甚至应该驻留在单独的编译单元上(用C或者Fortran编写),并且迭代器可作为指针参数传递过去。保证尽量不干扰编译器对高级C++代码的编译。
std::vector<>模板(最常用的容器)是一个特例,因为它的迭代器实现和标准(C)指针一样。而越复杂的容器则有更复杂的迭代器类,可能不太容易转换为原始指针。这种情况下,可使用包含多个类vector<>组件的“分段”结构表示数据(矩阵就是一个典型例子)。分段迭代器的使用还可实现快速低级别算法。详细信息见[C99, C100]。
