本节书摘来自华章计算机《Spark大数据处理:技术、应用与性能优化》一书中的第2章,第2.2节,作者:高彦杰 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.2 Spark集群初试
假设已经按照上述步骤配置完成Spark集群,可以通过两种方式运行Spark中的样例。下面以Spark项目中的SparkPi为例,可以用以下方式执行样例。
1)以./run-example的方式执行
用户可以按照下面的命令执行Spark样例。
./bin/run-example org.apache.spark.examples.SparkPi
2)以./Spark Shell的方式执行
Spark自带交互式的Shell程序,方便用户进行交互式编程。下面进入Spark Shell的交互式界面。
./bin/spark-shell
用户可以将下面的例子复制进Spark Shell中执行。
importscala.math.random
importorg.apache.spark._
objectSparkPi {
def main(args: Array[String]) {
val slices = 2
val n = 100000 * slices
val count = sc.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
}
}
按回车键执行上述命令。
注意,Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可,否则用户自己再初始化,就会出现端口占用问题,相当于启动两个上下文。
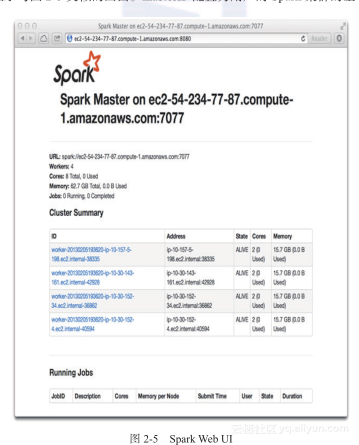
3)通过Web UI 查看集群状态
浏览器输入http://masterIP:8080, 也可以观察到集群的整个状态是否正常,如图2-5所示。集群会显示与图2-5类似的画面。masterIP配置为用户的Spark集群的主节点IP。