本节书摘来自华章计算机《 测试反模式:有效规避常见的92种测试陷阱》一书中的第1章,第1.2节,作者:(美) Donald G. Firesmith 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.2 测试和V模型
图1.1展示了一种常见的系统工程建模方式:传统的系统工程活动的V模型。V的左侧是将用户问题分解成小且可管理的部件的分析活动。类似地,V的右侧显示将部件合成(并测试)为能解决用户问题的系统的活动。
传统的V模型虽然有用,但从测试人员的角度来看,它并不能真正代表系统工程。接下来的3个图展示了3个更加详细的V模型,它们更好地把握了系统工程的测试方面。
图1.2展示了面向工作产品而不是活动的V模型。具体而言,这些是主要的可执行的工作产品,因为测试涉及了工作产品的执行。在这个例子中,V的左侧展示了更加详细的可执行模块的分析,而V的右侧展示了相应的实际系统的增量和迭代的合成。这款V模型显示可执行的东西都是经过测试的,而不是生成它们的通用的系统工程活动。
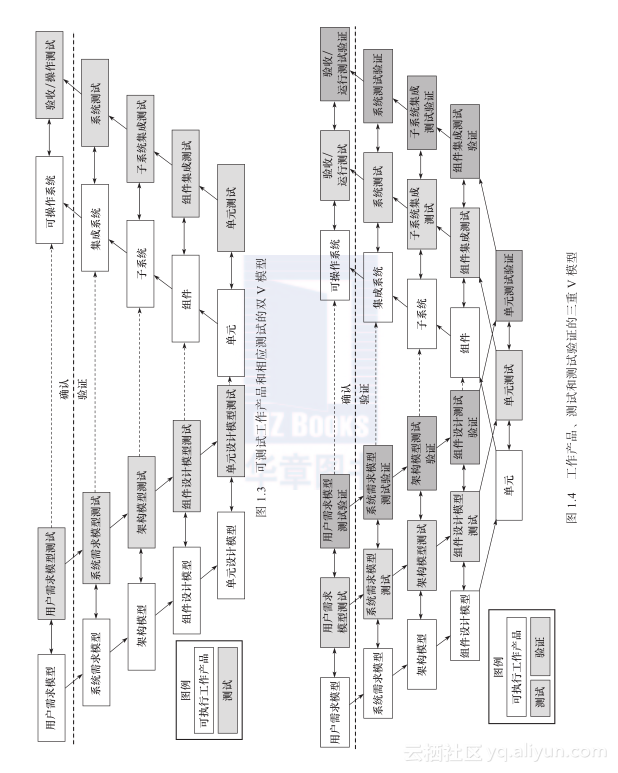
图1.3展示了双V模型,它在单V模型上增加了相应的测试[Feiler 2012]。关键点有:
- 每一个可执行的工作产品都需要测试。测试不需要(而且事实上不应该)限制在所实施的系统和它的部件中。测试任何可执行的需求、架构和设计同样重要。这样才可以在转移到实际系统和其部件之前,发现和修复相关的缺陷。这通常包括对以下内容的测试:可执行需求、架构或者通过建模语言(通常是基于状态且充分正式的)建立的被测系统(SUT)的设计模型,如SpecTRM-RL,结构分析和设计语言(AADL)以及程序设计语言(PDL);SUT的模拟;SUT的可执行的原型。
- 测试应在相应的工作产品创建时创建和执行。带有双向箭头的短箭头是用来表明:可以先开发可执行的工作产品并用于驱动测试的创建;可以使用测试驱动开发(TDD),在这种情况下,测试在它们所测的工作产品之前开发。
- 该模型的顶行使用测试来确认系统是否满足其利益相关者的需求(即建立了正确的系统)。相反,模型底部4行使用测试来验证该系统是否正确地建立(即架构符合需求、设计符合架构、实施符合设计等)。
- 最后,在实践中,底行的两侧通常被整合,从而使单元设计模型纳入单位,并且编程语言用作程序设计语言(PDL)。同样,单元设计模型测试被纳入单元测试,使得同一单元测试可验证单元设计和它的实现。
图1.4记录了三重V模型,其中增加了额外的验证活动来验证测试活动的正常进行。这是为了提供证据表明测试是充分完整的,不会产生大量的假阳性和假阴性的结果。
虽然V模型看起来是展现一个连续的瀑布开发周期,它们也可以用来展现一个渐近的(即增量、迭代和并发)开发周期,结合许多小的、可能重叠的V模型。然而,在大型、复杂系统的敏捷开发中应用V模型时,存在一些潜在的复杂性,需要超过一个简单的小V模型的集合,比如:
- 在架构上重要的需求和相关的架构需要尽可能快地敲定,因为所有后续的增量依赖于架构,一旦最初的增量是基于它的,再做修改是非常困难和昂贵的。
- 多个跨职能的敏捷团队将同时工作于不同的组件和子系统,所以他们的增量必须在团队间进行协调,以产生可以集成和发布的一致的、可测试的组件和子系统。
- 最后,有趣的是,要注意这些V模型不只是适用于正在开发的系统,同样也适用于该系统的测试环境或测试床及其测试实验室或设备的开发。