本节书摘来华章计算机《Storm实时数据处理》一书中的第1章 ,第1.5节,(澳)Quinton Anderson 著 卢誉声 译更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.5 创建Storm集群——配置机器
本地模式下测试集群对调试和验证集群的基本功能逻辑很有帮助。但是,这并不代表你就能够了解集群在实际环境中运行的状况。此外,只有当系统已经在产品环境中运行时,开发工作才算真正完成。任何开发者都应该重视这一点,并且这也是整个DevOps实践的基础。无论采用什么方法,你都必须能够将代码可靠地部署到产品环境中。本节将展示如何直接通过版本控制创建和配置一个完整的集群。在此之前,需要事先说明一些有关创建和配置集群的基本原则:
- 我们需要时刻了解服务器的会话状态。在没有严格版本控制的情况下,不允许登录和修改服务器的设置或文件。
- 不能随意修改服务器及其独立存储卷中的状态信息,这才能确保服务器的恢复时间。
- 如果在交付过程中遇到了问题,就应该多尝试几次。这对软件开发和信息技术运维中的灾难恢复和集成工作来说,是个不小的负担。而只有恢复和- 集成工作可以自动化进行的时候,我们才能重复操作。
- 本书假定你使用的产品部署环境是具有可伸缩性的集群(基于Amazon Web Services(AWS)EC2)。因为只有具备可伸缩性的集群才能实现自动化配置。
我们会在后续章节介绍AWS集群上部署Storm Topology的方法,在此之前会在本节的开发环境中对此方法做一些基本的介绍。
1.5.1 实战
我们按照下面的方法新建一个项目。
Step01 按照以下目录结构,新建一个名为vagrant-storm-cluster的项目:

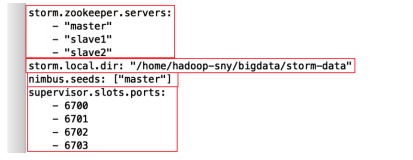
Step02 用你最喜爱的编辑器,在项目根目录下创建一个名为Vagrantfile的文件。在文件里添加文件头和我们想创建的虚拟机的配置。文件中至少包含一个nimbus节点、两个supervisor节点和一个zookeeper节点:
这里要注意的是,由于我们不打算设计具备高可用性的集群,因此在开发环境只用了一个zookeeper节点。该集群的作用是在现实环境中测试你的Topology逻辑,并确定其稳定性。
Step03 然后,就可以为每台机器创建虚拟机配置项了,Vagrant运行的时候会根据这些配置项单独建立每个虚拟机。第一组属性定义了硬件、网络和操作系统:
Step04 使用bash和Puppet混合脚本配置应用程序配置项:
Vagrant文件简单定义了虚拟机管理程序级别的配置项,其余配置项则通过Puppet配置,并定义了两个层次。第一层是安装Ubuntu,为应用程序配置做准备。第二层则包含了实际的应用程序配置操作。要创建第一层的配置项,需要创建用于JDK配置的bash脚本和初始化配置项的Puppet脚本。
Step05 在项目的scripts目录中新建installJdk.sh文件并添加以下代码:
我们将会使用声明式的Puppet脚本调用该脚本文件。
Step06 在manifest目录中新建jdk.pp:
Step07 在manifest目录中新建provisioningInit.pp文件,然后定义需要用到的包和静态变量值:
如果需要了解更多有关Hiera的信息,请查阅Puppet的文档页http://docs.puppetlabs.com/hiera/1/index.html。
Step08 然后,我们就可以克隆包含二级配置项的代码仓库了:
Step09 我们还需要配置Puppet插件Hiera,它能以分层方式分离配置脚本的各项属性:
Step10 最后,还需要在data目录中增加几个文件。创建Hiera基本配置文件hiera.yaml:
Step11 除此之外,你还需要host文件,它在本地集群环境中充当DNS:
在配置完善的环境中不需要host文件,但对于我们这个“只有一个主机”的开发环境来说,host文件还是非常实用的。
这样就完成了整个项目的构建,虽然它能正确配置虚拟机并安装需要用到的包,但我们还是需要创建Application层的配置项,而这些配置项包含在独立的代码仓库中。
Step12 为当前项目初始化你的Git代码仓库,并将其提交至bitbucket.org。
1.5.2 解析
我们在如图1-6所示的三个独立层次上进行配置。

本节内容只涵盖了配置Guest层和Hypervisor层的方法,我们会在下一节介绍Application层的配置。分层的一个重要原因是,你通常会根据不同的部署管理程序为不同层创建不同的配置项。当配置好虚拟机后,所有环境中的应用栈配置项都应该是一致的。保持配置的一致性非常重要,因为只有在这个条件下,我们才能在完成产品开发前对我们部署的产品进行成百上千次的测试,并保证它们处于可重用和版本控制的状态下。
开发环境中的VirtualBox是一个虚拟机管理程序,它通过Vagrant和Puppet提供其所需的配置项。Vagrant通过扩展VirtualBox镜像实现对虚拟机的配置。VirtualBox镜像属于受版本控制的工件。Vagrant文件中定义的每个Box,都需要指定以下参数:
- Base Box
- 网络设置
- 共享目录
- 虚拟机的内存和CPU设置
这些基本配置项并不包含任何产品环境中你期望的基本控制策略,比如安全、访问控制、托管和监控。所以你必须在部署至产品环境中之前配置好这些基本控制策略。你可以在Puppet Forge上找到有关内容:http://forge.puppetlabs.com。
然后调用配置代理来完成剩余的工作:
执行上面这条命令行语句会安装host文件,该文件包含了详细集群信息。
这条语句会更新Ubuntu apt-get缓存中所有的包,然后Vagrant会安装JDK和基本配置项。最后它将调用这些应用程序配置项。
虚拟机镜像可能已经包含了完整的配置,所以不一定要执行以上步骤。但需要知道如何创建合适的镜像,以及如何平衡基本镜像中特定配置的数量,否则你的配置数量会过多。