本节书摘来华章计算机《Storm实时数据处理》一书中的第1章 ,第1.1节,(澳)Quinton Anderson 著 卢誉声 译更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.4 创建“Hello World”Topology
“Hello World” Topology和其他所有的“Hello World”应用程序一样,并没有什么实际用途,其目的在于说明一些基本概念。“Hello World” Topology结构将演示如何创建一个包含简单的Spout和Bolt的项目,如何构建项目,并在本地集群模式下运行项目。
1.4.1 实战
Step01 新建一个项目目录,并初始化你的Git代码仓库。
Step02 然后,我们需要通过以下命令创建Maven项目文件:
Step03 使用vim或任何其他文本编辑器,为“Hello World”项目添加基本的XML标签和项目元数据。
Step04 然后,我们需要指定从哪一个Maven仓库获取依赖项。在pom.xml文件的项目标签内添加以下内容:

你可以使用.m2和settings.xml文件替换上面指定的这些仓库,虽然具体方法超出了本书的讨论范围,但对于开发团队来说依赖项管理非常重要,因此这种方法会变得十分有用。
Step05 然后在项目标签中添加我们所需的依赖项:
Step06 最后,我们需要为Maven添加build插件定义:



Step07 当创建好POM文件后,通过“Esc + : + wq + 回车键”保存文件,并为Maven项目创建所需的目录结构:
Step08 然后回到项目根目录,并通过以下命令创建Eclipse项目文件:
Eclipse的项目文件类似于.class文件,属于生成的工件,在提交到Git代码仓库的时候不应该包含此文件,特别是因为它们包含了客户机特定的路径。
Step09 打开你的Eclipse环境并把刚才生成的项目文件导入到工作区中,如图1-3所示。
Step10 接下来就可以创建你的第一个Spout了,在storm.cookbook包中创建名为HelloWorldSpout的类,并继承BaseRichSpout。Eclipse会为你生成一个默认的spouts方法。Spout会生成一个随机数生成的Tuple。添加以下成员变量并构造对象:
Step11 对象构造好后,Storm集群将会打开Spout,为open方法添加以下实现代码:
Step12 Storm集群会重复调用nextTuple方法,该方法包含了整个Spout的逻辑。为该方法添加以下实现代码:
Step13 最后,你需要通过declareOutputFields方法,告诉Storm集群Spout发送了哪些字段:
Step14 导入类所需的包和类后,就可以开始创建HelloWorldBolt了。该类用于读取已产生的Tuple并实现必要的统计逻辑。在storm.cookbook包中创建一个继承BaseRichBolt的新类。为Bolt声明一个私有成员变量并为execute方法添加以下实现代码:
Step15 最后,将所有代码逻辑组织起来,声明Storm Topology。在同一个包中创建名为HelloWorldTopology的主类,并添加以下主函数实现:

这样就搭建好了Topology,并根据传递给main方法的参数,将其提交到本地或远程的Storm集群上。
Step16 解决所有的编译问题后,你就能在项目根目录下,通过以下命令启动集群了: 
1.4.2 解析
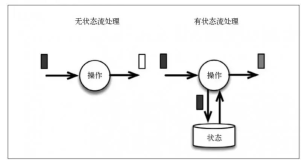
图1-4描述了“Hello World” Topology:

Spout最终会发送一个流(Stream),包含下面两条语句中的任意一条:
- Other Random Word
- Hello World
Spout根据随机概率决定要发送哪一条语句,具体原理是:先在构造函数中生成一个随机数,作为原始变量的值,接着生成随后的随机数,并和原始成员变量的值进行比较。若比较结果一致,就发送“Hello World”,否则会发送另一条语句。
Bolt会简单对比和计算Hello World的数量。在我们当前的实现中,你会注意到一系列通过Bolt打印出来的增量。想要扩展Bolt的规模,只需通过更新以下语句就可以为Topology增加并行程度:
这里parallism_hint是关键参数,你可以根据情况把这个参数值调高。如果重新运行集群,你将能看到三条独立的计数信息交织地打印出来。
部署运行后若要调整集群的大小,可以通过Storm的GUI或CLI来修改并行程度。但无法在没有重新编译和部署JAR包的情况下,直接修改Topology的结构。有关命令行选项的信息,请通过以下链接查看wiki上的CLI文档:https://github.com/nathanmarz/storm/wiki/Command-line-client。
确保POM中指定的项目依赖项正确是很重要的。我们必须将Storm JAR文件的范围设定成provided,否则这些依赖项会被打包进你的JAR,这会导致在一个集群节点中,classpath下出现重复的类文件。而且Storm会检查这种classpath重复的问题。启动集群会因为部署中包含了Storm的文件而失败。
下载示例代码
访问http://www.packtpub.com可下载本书及你所购买的所有Packt图书的示例代码。如果你是从其他地方购买的本书英文版,可以访问http://www.packtpub.com/support并注册,以便通过电子邮件取得示例文件。
作者通过Bitbucket账户来维护开源版本的代码:https://bitbucket.org/qanderson。