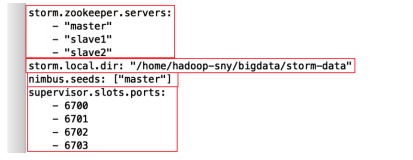
本节书摘来华章计算机《Storm实时数据处理》一书中的第1章 ,第1.2节,(澳)Quinton Anderson 著 卢誉声 译更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.2 搭建开发环境
开发环境涵盖了构建Storm Topology所需的各种工具和系统。虽说本书重点关注的是每个有技术侧重点的Storm交付,但需要指出的是,对于一个软件开发团队来说,无论使用集中式开发环境还是分布式开发环境,都需要更多的工具和流程来保证高效工作,而且不能仅仅局限于本书所讨论的内容。
无论是为了将来的开发工作,还是为了实现书中的例子,以下几类工具和流程都是快速搭建开发环境必不可少的:
- SDK
- 版本控制
- 构建环境
- 系统配置工具
- 集群配置工具
书中描述的配置和安装方法都基于Ubuntu。不管怎么说,适用于Ubuntu的这些方法还是比较容易移植到其他Linux发行版中的。如果将这些方法应用于其他发行版时出现任何问题,你可以通过Storm邮件列表寻求支持:https://groups.google.com/forum/#!forum/storm-user。
环境变量是导致系统可操作性和可用性下降的“罪魁祸首”,如果部署环境与开发环境不同,那么环境变量很可能在这时引起大问题。所以尽可能让开发环境和部署环境保持一致。
1.2.1 实战
Step01 从Oracle网站(http://www.oracle.com/technetwork/java/javase/downloads/index.html)下载最新版本的J2SE 6 SDK,并通过以下命令进行安装:

Step02 然后安装版本控制系统Git:
Step03 接下来,安装构建系统Maven:
Step04 安装Puppet、Vagrant和VirtualBox,以便于对应用程序和环境进行配置:
Step05 最后,你还需要安装一个集成开发环境(IDE):
自从Sun公司被Oracle收购以后,人们就一直在争论该使用哪种Java SDK。虽说作者理解OpenJDK的必要性,但书中的例子都是在Oracle JDK下测试通过的。总的来说,OpenJDK和Oracle JDK没有什么区别,只是Oracle JDK为了追求稳定而在功能方面相对滞后。
1.2.2 解析
对于任何Java开发工作来说JDK都是必不可少的。GIT是近几年被广泛采用的开源分布式版本控制系统。稍后我们将简要介绍GIT。
Maven是一种广泛使用的“约定优于配置”的构建系统。Maven包含了许多有用的功能,比如项目对象模型(POM),POM能够让我们以有效的方式管理库、依赖和版本。Maven在互联网上拥有许多二进制仓库可供使用,所以我们可以直接用恰当的方式来维护二进制依赖项,然后打包部署Topology。
由于DevOps和持续交付的不断发展,Puppet 系统已经被广泛用于为Linux、其他一些操作系统和应用程序提供声明式服务器配置。Puppet能够对服务器的状态和部署环境进行编程,这一点非常重要,因为这样就可以通过GIT版本控制系统管理服务器状态,而且对于服务器的修改都可以安全删除。这么做好处很多,包括可确定的服务器平均恢复时间(MTTR)和审计跟踪,说白了就是让系统更加稳定。这对实现持续交付来说至关重要。
Vagrant是一个在开发过程中非常有用的工具,它能自动配置VirtualBox虚拟机,这对Storm处理系统这样的以集群为基础的技术来说尤为重要。为了测试一个集群,你必须构建一个真正的机群或配置多台虚拟机。Vagrant能准确无误地在本地配置虚拟机。
虚拟机在IT运维和系统开发过程中能够大显身手,但需要指出的是,虽然我们都知道在本地部署的虚拟机性能不太理想,但其可用性却完全依赖于可用的内存容量。处理能力不是需要考虑的主要问题,因为现代处理器的利用率普遍严重偏低,尽管处理Topology时利用率会高一些。建议你的计算机至少保留8GB的内存容量。