本节书摘来自华章计算机《Storm分布式实时计算模式》一书中的第3章,第3.3节,作者:(美)P. Taylor Goetz Brian O’Neill 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.3 Trident spout
让我们先来看topology中的spout。和Storm相比,Trident引入了“数据批次”(batch)的概念。不像Storm的spout,Trident spout必须成批地发送tuple。
每个batch会分配一个唯一的事务标识符。spout基于约定决定batch的组成方式。spout有三种约定:非事务型(non-transactional)、事务型(transactional)、非透明型(opaque)。
非事务型spout对batch的组成部分不提供保障,并且可能出现重复。两个不同的batch可能含有相同的tuple。事务型spout保证batch是非重复的,并且batch总是包含相同的tuple。非透明型spout保证数据是非重复的,但不能保证batch的内容是不变的。
表3-1描述了这些特性。

spout接口如下面代码片段所示:

在Trident中,spout没有真的发射tuple,而是把这项工作分解给了BatchCoordinator和Emitter方法。Emitter负责发送tuple,BatchCoordinator负责管理批次和元数据,Emitter需要依靠元数据来恰当地进行批次的数据重放。TridentSpout函数仅仅是简单地提供了到BatchCoordinator和Emitter的访问方法,并且声明发射的tuple包括哪些字段。下面列出了示例中的DiagnosisEventSpout方法:
" >
如上述代码中的getOutputFields()方法所示,在我们的实例topology中,spout发射一个字段event,值是一个DiagnosisEvent类。
BatchCoordinator类实现下述接口:
" >
BatchCoordinator是一个泛型类。这个泛型类是重放一个batch所需要的元数据。在本例中,spout发送随机事件,因此元数据可以忽略。实际系统中,元数据可能包含组成了这个batch的消息或者对象的标识符。通过这个信息,非透明型和事务型spout可以实现约定,确保batch的内容不出现重复,在事务型spout中,batch的内容不会出现变化。
BatchCoordinator类作为一个Storm Bolt运行在一个单线程中。Storm会在ZooKeeper中持久化存储这个元数据。当事务处理完成时会通知到对应的coordinator。
在我们的例子中,没有做特定的协调操作,下面就是DiagnosisEventSpout类中使用的协调操作:


Trident spout的第二个组成部分是Emitter。在Storm里,spout使用collector来发送tuple,Emmiter函数在Trident spout中执行这种功能。唯一的区别是,使用TridentCollector类,发送出去的tuple是通过BatchCoordinator类初始化的一批数据。
Emitter方法的接口格式如下所示:
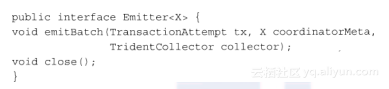
如前面代码所示,Emitter函数只有一个功能,将tuple打包发射出去。为了实现这个功能,函数接收的参数包括batch(由coordinator生成的)的元数据、事务的信息和Emitter用来发送tuple的collector。DiagnosisEventEmitter类的代码如下所示:
" >

发送的工作在emitBatch()中进行。例子中,我们随机分配一个经度和纬度,大体保持在美国范围内,使用System.currentTimeMillis()方法生成诊断的时间戳。
实际场景中,ICD-9-CM的范围在000到999之间。针对本示例,我们仅使用320到327之间的诊断代码。这些代码如下所示:

这些诊断代码随机分配给事件。
在这个例子里,我们使用对象来封装诊断事件。为简化起见,我们将事件的每个组成部分作为tuple的一个独立字段。这里,对象封装还是使用tuple字段进行封装,需要权衡。通常会限制tuple的字段在易于管理的数量之内,但为了数据流控制或tuple的分组策略,将数据放在tuple的字段里还是有意义的。
在我们的例子中,DiagnosisEvent类表示topology处理的关键数据。对象的代码如下所示:

这个对象是一个简单的JavaBean。时间戳使用long变量存储,存储的是纪元时间的秒数。经度和纬度使用dobule存储。diagnosisCode类使用string,以防系统可能需要处理非ICD-9数据,比如有字母的代码。
至此,topology已经可以发射事件了。在实际场景中,我们可能将topology集成到一个医疗请求处理系统或者一个电子健康记录系统来进行实践演练。

