本节书摘来自华章计算机《Storm分布式实时计算模式》一书中的第2章,第2.3节,作者:(美)P. Taylor Goetz Brian O’Neill 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.3 在Linux上安装Storm
Storm是设计运行在Unix兼容的操作系统上。但在0.9.1版本,它也支持在Windows机器上部署。
为了简化部署,我们使用Ubuntu 12.04LTS的发行版作为安装服务器。将会使用服务器版本,默认不包括图形界面接口,因为我们用不到。。在实体机和虚拟机上安装ubuntu都是非常方便的。出于学习和开发的目的,你会发现在虚拟机里进行部署更加方便,尤其是手头没有那么多实体机的情况。
OSX、Linux、Windows都有着对应的虚拟机软件。我们建议从下面集中软件中选择一个:
- VMWare(OSX、Linux、Windows)
- VirtualBox(OSX、Linux、Windows)
- Parallels Desktop(OSX)
2.3.1 安装基础操作系统
可以从Ubuntu的安装盘或镜像启动,遵循屏幕上的指令选择基础安装。在Packege Selection在屏幕上出现的时候,选取安装OpenSSH服务的选项。这个安装包允许你从远程ssh登录上服务器。在其他安装界面上,都选择默认选项就可以了,除非是为了兼容硬件修改选项。
默认情况下,进入Ubuntu的初始化用户具有管理权限(sudo)。如果你要重新建一个账户,记得给账户赋予管理权限。
2.3.2 安装Java
首先安装JVM。Storm可以兼容1.6和1.7版本OpenJDK和Oracle发布的JVM。本例中,我们首先更新系统,然后安装1.6版本的JDK。
2.3.3 安装ZooKeeper
在我们的单节点伪集群中,需要安装一个ZooKeeper实例就够了。Storm需要3.3.X版本的ZooKeeper。调用一次下述命令即可:

这个命令会安装二进制版本的ZooKeeper,并且会生成一个服务的脚本来启动和关闭它。还会生成一个cron工作来定期清理过期的ZooKeeper传输记录和快照。如果不按默认设置来清理,ZooKeeper很快就会占用大量硬盘使用空间。
2.3.4 安装Storm
Storm二进制发行版本可以在Storm官网下载到。二进制版本的安装文件夹布局更适合在生产系统中部署。我们会做一些修改,使之更贴近UNIX的风格(比如日志搭在/var/log下而不是搭在Storm的主目录)。
首先新建Storm的用户和用户组。这可以避免Storm进程以默认或者root权限启动:
" >
然后下载和安装Storm的发行版本。我们将Storm安装在/usr/share目录下并且生成一个版本无关的软连接到/usr/share/storm目录下。这种方式便于将来升级版本,或回滚版本,只需要重新建立一个软连接即可。我们在将Storm的可执行程序软连接到/usr/bin/storm目录下:

默认的,Storm会将日志写在$STORM_HOME/logs,而不像其他Unix程序一样将日志写在/var/log下。执行下面的命令,在/var/log生成Storm转述的log目录,并将Storm配置指向那里:
最后,将Storm的默认配置文件移到/etc/storm下,建立软连接以便Storm程序可以找到它:

Storm安装完毕后,可以对Storm守护进程的程序进行配置,使其异常之后可以自动恢复。
2.3.5 运行Storm守护进程
所有的Storm守护进程都是设计为快速失败的,也就是一旦遇到了任何异常错误进程将会终止。这样使得单独的组件可以安全地结束,并且在不影响系统其他部分的情况下恢复。
这意味着,Storm的守护进程无论在什么时候异常终止,都需要立即重启。这个技术称为在监督(supervision)下运行进程。幸运的是,有很多种技术供选择。实际上,ZooKeeper也是一个快速失败的系统,在Debian发行版中特有的基于upstart的init脚本给ZooKeeper提供了这项功能。如果ZooKeeper进程在任意时间退出,upstart会保证重启进程恢复集群。
Debian的upstart系统非常适合这种场景。在其他Linux发行版本还有其他的选择。为了简单起见,我们使用大部分Linux发行版都有的supervisor包来实现这个功能。不巧的是,supervisor的名字和Storm的supervisor后台程序冲突了。为了表明区别,我们将非Storm的supervisior后台程序叫做supervisord(添加了一个d),但后面代码示例中,还是会用没有d的名字来执行命令。
在基于Debian的Linux发行版本中,supervisord包命名为supervisor,其在其他发行版,如RED HAT中,使用supervisord的名字,执行下述命令:

这条命令会安装和启动supervisord服务,服务的主要配置在/etc/supervisor/supervisord中。Supervisord服务会自动包含所有/etc/supervisord/conf.d/目录下的*.conf文件,我们将在这里放置运行Storm后台进程需要的config文件。
每个要在Supervisord监督下运行的命令,都需要创建一个文件,包含下列内容:
- 每个被监督命令要配置一个在supervisord配置中唯一的名字。
- 启动的命令
- 启动时的工作目录
- 当一个命令或者服务终止时,是否要拉起。对于快速失败服务,这项配置永远是true。
切换到Storm命令时使用的目录。这里,我们使用Storm用户来执行所有守护进程
建立下述三个文件使得Storm守护进程由supervisord自动拉起(在遇到异常终止的事件时也会重启)。
- /etc/supervisord/conf.d/storm-nimbus.conf文件内容是:
https://yqfile.alicdn.com/77c2dd0fc5c9107963688db96c414c347fa67767.png" >
- /etc/supervisord/conf.d/storm-supervisor.conf文件内容是:

- /etc/supervisord/conf.d/storm-ui.conf文件内容是:

当文件生成后,通过下述命令终止启动supervisord服务:
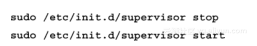
supervisord会载入新的配置文件并且启动Storm的守护进程。片刻后Storm服务就会启动,可以通过在浏览器里访问下述URL来判断Storm伪集群是否已经启动运行(使用实际机器的IP或者hostname来替换URL中的localhost字段):
https://yqfile.alicdn.com/6b5cf007ca51e36c82b2c535c72d3b14d45970e7.png" >
这里提及了Storm UI图形接口。它表明集群正在运行,包含了一个supervisor和四个worker槽位,没有topology在集群中运行(稍后将会将一个topology发布到集群里)。
如果Strom UI因为某些原因未能启动起来,或者看不到集群中活跃的supervisor,可以从下述位置查看错误日志:- Strom UI:在/var/log/storm中查看ui.log文件。
- Nimbus:在/var/log/storm中查看nimbus.log文件。
- Supervisor:在/var/log/storm查看supervisor.log文件。
迄今为止我们都在使用Storm的默认配置,使用localhost作为集群中ZooKeeper、Nimbus等服务的主机名参数。在一个机器上构建单节点伪集群时是可行的,但是实际搭建一个多节点的集群需要重新定义一些默认配置选项。
下来,我们将介绍Storm提供的不同的配置选项,以及这些配置项如何影响集群和topology的行为。
2.3.6 配置Storm
Storm的配置由一些YAML格式的属性组成。当一个Storm的守护进程启动时,会加载默认属性,然后加载$STORM_HOME/conf目录下的storm.yaml(已经软连接到/etc/storm/storm.yaml)文件,然后使用该文件中的值替换默认值。
下面列出了storm.yaml配置文件中必须要重新定义的几项内容:

2.3.7 必需的配置项
下述配置项是生产环境的多节点Storm集群的必选配置:- storm.zookeeper.serviers:这项配置列出了ZooKeeper集群的主机名称。因为我们在一台机器上运行单节点的ZooKeeper,并且Storm的其他守护程序都在同一台机器上,可以使用默认值的localhost。
- nimbus.host:指定了集群中nimbus的节点。worker需要从这项配置知道集群的主节点在哪里,用来下载topology的jar包和配置选项。
- supervisor.slots.pors:这个配置控制每个supervisor节点运行多少个worker进程。这个配置定义为worker监听端口的列表,监听端口的个数控制了supervisor节点上有多少个worker的插槽。例如,如果我们有个集群中有三个supervisor节点,每个节点配置了三个监听端口,整个集群就有九个worker插槽(3×3=9)。默认的,Storm使用6700~6703端口,每个supervisor节点上有4个worker插槽。
- storm.local.dir:nimbus和supervisor守护进程都会存储一些短暂的状态信息,比如JAR报和woker需要的配置文件。这个配置项决定了nimbus和supervisor将信息存储在哪里。这个指定的目录必须已经存在,并且storm的启动用户要有合适的操作权限,可以读或者写这个目录。这个目录下的内容必须在集群运行的过程中一直保存,所以要避免使用/tmp目录作为这个这个配置项,因为重启后/tmp目录的内容会丢失。
2.3.8 可选配置项
一个运营中的Storm集群除了上述必选配置项之外,还有一系列可选配置项,可以按照需要进行重新定义。Storm配置选项使用点号分隔的命名规范,用前缀来识别配置分类;如表2-1所示。
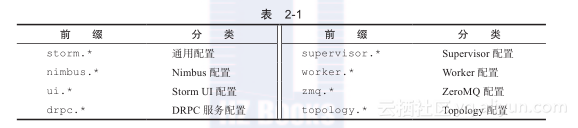
如果需要查看完整的默认配置,可以在Storm的源码中查看defaults.yaml文件(https://github.com/nathanmarz/storm/blob/master/conf/defaults.yaml)。其他几个经常需要重新定义的配置如下:
nimbus.childopts(default:“-Xms1024m”):这项JVM的配置会添加在启动nimbus守护进程的Java命令行中。- ui.port(default:8080):这项配置指定了Storm UI的Web服务器监听的端口。
- ui.childopts(default:“-Xms1024m”):这项JVM配置会添加在Storm UI服务启动的Java命令行中。
- supervisor.childopts(default:“-Xms768m”):这个JVM选项会添加在Supervisor启动的Java命令行中。
- worker.childopts(default:“-Xms768m”):这个JVM选项会添加在启动worker进程的Java命令行中。
- topology.message.timeout.secs(default:30):这个配置项设定了一个tuple树需要应答最大时间秒数限制,超过这个时间的认为已经执行失败(超时)。这个值设置得太小可能会导致tuple反复重新发送。当这个选项生效时,spout必须设定来发送锚定的tuple。
- topology.max.spout.pending(default:null):在默认值null的时候,每当spout产生了新的tuple,Storm会立即将tuple向后端数据流发送。由于下游bolt执行可能有延迟,默认的数据发送行为可能导致topology过载,从而导致消息处理超时。将本选项设置为非null大于0的数字时,Storm会暂停发送tuple到数据流直到发送出去的tuple小于这个数字,起到了对spout限速的作用。这项配置和topology.message.timeout.secs一起,是调节topology性能的最重要的两个参数。
- topology.enable.message.timeouts(default:ture):这个选项用来设定锚定的tuple的超时时间。如果设置为false,则锚定的tuple不会超时。谨慎使用这个选项,将本项配置设置为flase之前,考虑改变topology.message.timeout.secs。本项配置生效后,spout必须配置为发送锚定tuple。
2.3.9 Storm可执行程序
Storm执行程序是一个多用途的命令行程序,可以用来启动所有的守护进程,执行topology管理操作,比如说部署一个新的topology到集群,或者使用本地模式在开发测试阶段执行一个topology。
Storm命令的基础命令如下:
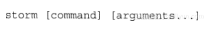
2.3.10 在工作站上安装Storm可执行程序
为了在连接的远程集群上执行Storm命令,需要在本地安装Storm发行版。在工作站上安装Storm发行版很简单,只需要解压缩Storm发行版的压缩包,并且添加Stom的bin目录($STORM_HOME/bin)到PATH环境变量中。下一步在~/.storm/目录下新建storm.yaml文件,文件内容只有一行,告诉storm在哪里可以找到需要连接集群的nimbus服务:
示例:~/.storm/storm.yaml file.

为了让一个Storm集群正确执行,必须正确配置主机名的IP地址解析,无论是通过DNS系统还是通过/etc/hosts文件。
在Storm配置中,也可以直接使用IP来代替主机名,使用DNS系统更好。
2.3.11 守护进程命令
Storm的守护进程用来启动Storm服务,应该在被监督模式下启动,这样,程序如果有异常失败,服务就可以重启。在启动时,Storm守护程序从$STORM_HOME/conf/storm.yaml中读取配置。这个配置文件中的任何配置项都会重新定义内置的默认配置。Nimbus 用法:storm nimbus 这个命令启动nimbus守护进程 Supervisor 用法:storm supervisor 这个命令启动supervisor进程 UI 用法:storm ui 这个命令启动Storm UI的守护进程,提供了一个web的UI界面用来监控Storm集群。 DRPC 用法:storm drpc 这个命令启动一个DRPC服务守护进程2.3.12 管理命令
Storm的管理命令用来发布和管理集群中的topology。管理命令通常在Storm集群外部的工作站来执行,但不是必需的。和nimbus Thrift API通信需要知道nimbus节点的主机名。管理命令在~/.storm/storm.yaml文件中查找配置,Storm的jar包会添加到Java的classpath中。配置中唯一需要的参数是nimbus节点的主机名:

用法:storm jar topology_jar topology_class[arguments...]
jar命令用来向集群提交topology。它会使用指定的参数运行topology_class中的main()方法,同时上传topology_jar文件到nimbus以分发到整个集群。提交后,Storm集群会激活并且开始运行topology。
topology类中的main()方法需要调用StormSubmitter.submitTopology()方法,并且为topology提供集群内唯一的名称。如果集群中已经有一个同名的topology,jar命令会执行失败。通常会通过命令行参数的方式指定topology的名称,这样topology就可以在提交执行的时候再命名。
Kill
用法:storm kill topology_name[-w wait_time]
Kill命令用来关闭已经部署的topology。这个命令使用topology_name来关闭topology。首先,Storm在topology.message.timeout.secs的时间后使toplogy的spout取消激活,这样已经发出去的tuple就可以执行完毕。然后停止worker进程,并且尝试清理所有存储的状态信息。特别是,通过-w参数,可以使用特定的时间间隔覆盖topology.message.timeout.secs参数。Kill命令也可以用在Storm UI上进行操作。
Deactivate
用法:storm deactivate topology_name
Deactivate命令告诉Storm停止特定的topology的spout发送tuple。topology可以在Storm UI上进行取消激活的操作。
Activate
用法:storm activate topology_name
Activate命令告诉Storm重新恢复特定topology的spout发送tuple,topology可以在Storm UI中重新激活操作。
Rebalance
用法:storm rebalance topology_name-w wait_time[-e component_name=
executer_count]...
rebalance命令指示Storm在集群的worker之间重新平均地分派任务,不需要关闭或者重新提交现有的topology。例如,当一个新的supervisor节点添加到一个集群中时,就会需要执行这个命令,因为现有的topology是不会将任务分配到新节点的worker上的。
rebalance命令还可以分别使用-n和-e参数来修改为topology分配的worker的个数以及每个task分配的executor的个数。
当执行rebalance命令时,Storm会先取消激活topology,等待配置的时间使剩余的tuple完成处理,然后在supervisor节点中均匀地重新分配worker。重新平衡后,Storm会将topology恢复到之前的激活状态(意思是,如果是已经激活的topology,Storm会重新激活它,反之亦然)。
下述的例子会等待15秒后重新平衡wordcount-topology topology,指定5个worker,比如去设置sentence-spout和split-bolt使用4个和8个executor线程:

Remoteconfvalue
用法:storm remoteconfvalue conf-name
Remoteconfvalue命令用来查看远程集群中的配置参数值。注意,用这个命令看到的是整个集群的公共配置,看不到单独topology中覆盖的特殊配置。
2.3.13 本地调试/开发命令
Storm的本地命令是用来进行调试和测试用的。和管理命令类似,Storm的调试命令也会读取~/.storm/storm.yaml文件并且使用其值来覆盖Storm内置的默认值。
REPL
使用:storm repl
Repl命令会使用Storm的本地classpath打开一个Clojure REPL会话。
Classpath
使用:storm classpath
Classpath命令打印Storm client使用的classpath值。
Localconfvalue
使用:storm localconfvalue conf-name
Localconfvalue命令在整合~/.storm/storm.yaml和Storm内置默认值后的配置中查找特定配置项的值。
- /etc/supervisord/conf.d/storm-ui.conf文件内容是:
- /etc/supervisord/conf.d/storm-supervisor.conf文件内容是:

