本节书摘来自华章计算机《Storm分布式实时计算模式》一书中的第1章,第1.6节,作者:(美)P. Taylor Goetz Brian O’Neill 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.6 有保障机制的数据处理
Storm提供了一种API能够保证spout发送出来的每个tuple都能够执行完整的处理过程。在我们上面的例子中,不担心执行失败的情况。可以看到在一个topology中一个spout的数据流会被分割生成任意多的数据流,取决于下游bolt的行为。如果发生了执行失败会怎样?举个例子,考虑一个负责将数据持久化到数据库的bolt。怎样处理数据库更新失败的情况?
1.6.1 spout的可靠性
在Storm中,可靠的消息处理机制是从spout开始的。一个提供了可靠的处理机制的spout需要记录它发射出去的tuple,当下游bolt处理tuple或者子tuple失败时spout能够重新发射。子tuple可以理解为bolt处理spout发射的原始tuple后,作为结果发射出去的tuple。另外一个视角来看,可以将spout发射的数据流看作一个tuple树的主干(如图1-6所示)。
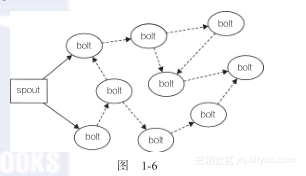
在图中,实线部分表示从spout发射的原始主干tuple,虚线部分表示的子tuple都是源自于原始tuple。这样产生的图形叫做tuple树。在有保障数据的处理过程中,bolt每收到一个tuple,都需要向上游确认应答(ack)者报错。对主干tuple中的一个tuple,如果tuple树上的每个bolt进行了确认应答,spout会调用ack方法来标明这条消息已经完全处理了。如果树中任何一个bolt处理tuple报错,或者处理超时,spout会调用fail方法。
Storm的ISpout接口定义了三个可靠性相关的API:nextTuple,ack和fail。

前面讲过,Storm通过调用Spout的nextTuple()发送一个tuple。为实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SpoutOutputCollector的emit()方法:
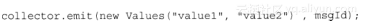
给tuple指定ID告诉Storm系统,无论执行成功还是失败,spout都要接收tuple树上所有节点返回的通知。如果处理成功,spout的ack()方法将会对编号是ID的消息应答确认,如果执行失败或者超时,会调用fail()方法。
1.6.2 bolt的可靠性
bolt要实现可靠的消息处理机制包含两个步骤:
1.当发射衍生的tuple时,需要锚定读入的tuple
2.当处理消息成功或者失败时分别确认应答或者报错
锚定一个tuple的意思是,建立读入tuple和衍生出的tuple之间的对应关系,这样下游的bolt就可以通过应答确认、报错或超时来加入到tuple树结构中。
可以通过调用OutputCollector中emit()的一个重载函数锚定一个或者一组tuple:

这里,我们将读入的tuple和发射的新tuple锚定起来,下游的bolt就需要对输出的tuple进行确认应答或者报错。另外一个emit()方法会发射非锚定的tuple:
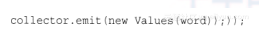
非锚定的tuple不会对数据流的可靠性起作用。如果一个非锚定的tuple在下游处理失败,原始的根tuple不会重新发送。
当处理完成或者发送了新tuple之后,可靠数据流中的bolt需要应答读入的tuple:
" >
如果处理失败,这样的话spout必须发射tuple,bolt就要明确地对处理失败的tuple报错:
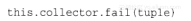
如果因为超时的原因,或者显式调用OutputCollector.fail()方法,spout都会重新发送原始tuple。后面很快有例子。
1.6.3 可靠的单词计数
为了进一步说明可控性,让我们增强SentenceSpout类,支持可靠的tuple发射方式。需要记录所有发送的tuple,并且分配一个唯一的ID。我们使用HashMap来存储已发送待确认的tuple。每当发送一个新的tuple,分配一个唯一的标识符并且存储在我们的hashmap中。当收到一个确认消息,从待确认列表中删除该tuple。如果收到报错,从新发送tuple:


为支持有保障的处理,需要修改bolt,将输出的tuple和输入的tuple锚定,并且应答确认输入的tuple:

