本节书摘来自华章计算机《Storm分布式实时计算模式》一书中的第1章,第1.4节,作者:(美)P. Taylor Goetz Brian O’Neill 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.4 Storm的并发机制
在Storm的间接中提到过,Storm计算支持在多台机器上水平扩容,通过将计算切分为多个独立的tasks在集群上并发执行来实现。在Storm中,一个task可以简单地理解为在集群某节点上运行的一个spout或者bolt实例。
为了理解storm的并发机制是如何运行的,我们先来解释下在集群中运行的topology的四个主要组成部分:
- Nodes(服务器):指配置在一个Storm集群中的服务器,会执行topology的一部分运算。一个Storm集群可以包括一个或者多个工作node。
- Workers(JVM虚拟机):指一个node上相互独立运行的JVM进程。每个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
- Executeor(线程):指一个worker的jvm进程中运行的Java线程。多个task可以指派给同一个executer来执行。除非是明确指定,Storm默认会给每个executor分配一个task。
- Task(bolt/spout实例):task是spout和bolt的实例,它们的nextTuple()和execute()方法会被executors线程调用执行。
1.4.1 WordCountTopology的并发机制
到目前为止,在单词计数的示例中没有明确使用任何Storm中并发机制的API,而是让Storm使用默认配置。在大多数情况下,除非明确指定,Strom的默认并发设置默认是1。
在我们修改topology的并发度之前,先来看默认配置下topology是如何执行的。假设我们有一台服务器(node),为topology分配了一个worker,并且每个executer执行一个task。我们的topology执行过程如图1-3所示:
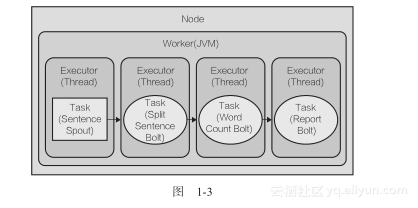
正如在图中看到的,唯一的并发机制出现在线程级。每个任务在同一个JVM的不同线程中执行。如何增加并发度以充分利用硬件能力?让我们来增加分配给topology的worker和executer的数量。
1.4.2 给topology增加worker
增加额外的worker是增加topology计算能力的简单方法。为此Storm提供了API和修改配置项两种修改方法。无论采取哪种方法,spout和bolt组件都不需要做变更,可以直接复用。
在单词计数topology前面的版本中,我们引入了Config对象在发布时传递参数给submitTopology()方法,但是没有做更多配置操作。为了增加分配给一个topology的worker数量,只需要简单的调用一下Config对象的setNumWorkers()方法:

这样就给topology分配了两个worker而不是默认的一个。从而增加了topology的计算资源,也更有效的利用了计算资源。我们还可以调整topology中的executor个数以及每个executor分配的task数量。
1.4.3 配置executor和task
我们已经知道,Storm给topology中定义的每个组件建立一个task,默认的情况下,每个task分配一个executor。Storm的并发机制API对此提供了控制方法,允许设定每个task对应的executor个数和每个executor可执行的task的个数。
在定义数据流分组时,可以设置给一个组件指派的executor的数量。为了说明这个功能,修改topology的定义代码,设置SentenceSpout并发为两个task,每个task指派各自的executor线程。
如果只使用一个worker,topology的执行如图1-4所示。
下一步,我们给语句分割bolt SplitSentenceBolt设置4个task和2个executor。每个executor线程指派2个task来执行(4/2=2)。还将配置单词计数bolt运行四个task,每个task由一个executor线程执行:
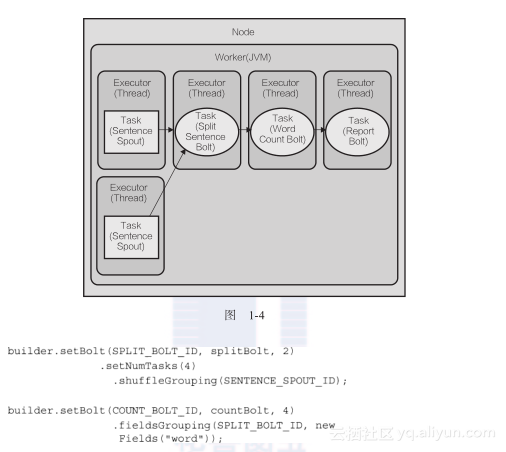
在2个worker的情况下,topology执行如图1-5所示。
增加了topology并发后,运行更新过的WordCountTopology类,每个单词的计数比原topology要多:

" >
spout在topology关闭之前会一直发射数据,单词的计数值取决于计算机的速度,是否有其他程序在运行。总量上看发射和处理的单词增多了。
要重点指出的是,当topology执行在本地模式时,增加worker的数量不会达到提高速度的效果。因为topology在本地模式下是在同一个JVM进程中执行的,所以只有增加task和executor的并发度配置才会生效。Storm的本地模式提供了接近集群模式的模拟,对开发是否有帮助。但程序在投入生产环境之前,必须在真实的集群环境下进行测试。

