本节书摘来自华章计算机《人工智能:计算Agent基础》一书中的第3章,第3.6节,作者:(加)David L.Poole,Alan K.Mackworth 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.6 启发式搜索
前面说的所有的算法都是无信息的,并没有考虑目标节点在哪里。它们没有使用任何指引它们该向哪去的信息,除非它们无意中发现目标。关于哪些节点是最有希望节点的启发信息的一种形式叫做启发函数h(n),这个函数参数为节点n,返回一个非负实数,即为节点n到目标节点的估计花费。如果h(n)的值小于或等于从n节点到目标节点最低花费路径的实际花费,那么就说启发函数是“低估”的。
启发函数是得出目标的搜索方向的一种方式。它提供一个有信息依据的方法来猜测节点的哪个邻居将会通往目标节点。
启发函数没有什么神奇可言。它只能使用可容易地从节点上获取的信息。通常情况下,需要在以下两个值之间做折中:获取一个节点的启发值所花费的工作量,以及一个节点的启发值如何准确地衡量从该节点到目标的实际路径花费。
得到启发函数的一个标准方式是:解决一个更简单点的问题,然后将简化了的问题的实际花费作为原始问题的启发函数。
【例3-12】 图3-2中,从节点到目标位置的直线距离可以作为启发函数。
下述实例中假设如下启发函数:
h(mail)=26h(ts)=23h(o103)=21
h(o109)=24h(o111)=27h(o119)=11
h(o123)=4h(o125)=6h(r123)=0
h(b1)=13h(b2)=15h(b3)=17
h(b4)=18h(c1)=6h(c2)=10
h(c3)=12h(storage)=12
h函数就是一个低估,因为h的值小于或等于从节点到目标的最低花费路径的真实花费。对于o123来说,h的值就是真实花费值。对b1来说,则是很大的低估,看起来b1离目标很近,但其实只能通过一条很长的路径才能到达目标。而对于c1来说,这个h值则差之千里,因为看起来它离目标节点很近,事实上没有从该节点通往目标节点的路径。
【例3-13】 在例3-2中的投递机器人,状态空间包含要运送的包裹。假定花费函数是机器人运送所有包裹走过的总距离。一个可能的启发函数就是一个包裹到目的地的最大距离。如果机器人只能携带一个包裹,那么可能的启发函数就是包裹经过的距离之和。如果机器人一次可以携带多个包裹,那么这个启发函数就不是真实花费的低估了。
h函数也可以扩展适用(非空)路径。路径的启发值是路径最后的节点的启发值。即
h(〈no,…,nk〉)=h(nk)
启发函数的一个简单应用是在深度优先搜索中为邻居排序,这些节点被依次压入堆栈来表示边界,这样邻居被加入边界,因此最先选择的是最优邻居,即所谓“启发式深度优先”(heuristic depth-first search)算法。这种搜索算法可以找到局部最优路径,但是在搜索另一条路径之前,它会遍历所有已选路径。尽管这个算法常用,但也受困于深度优先搜索自身的问题。
启发函数的另一种使用方式是:总是选择边界中具有最低启发值的路径,这叫做最优优先搜索(best-first search)。这个方法通常不太有效,它会选择看上去最有希望的路径,因为他们离目标节点很近,但是路径花费会不断增加。
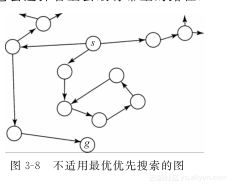
【例3-14】 如图3-8所示,弧线的花费是它的长度。目标是找到从s到g的最短路径。假定到节点g的欧几里得距离是启发函数。启发深度优先搜索将会选择位于s下面的节点,并永远不会终止。相似地,因为位于s以下的所有节点看起来都不错,最优优先搜索将会在它们之间循环,而从不尝试由s开始的其他可替换路径。
3.6.1 A 搜索
A 搜索是最低花费优先搜索和最优优先搜索的结合,它在选择路径扩展时既要考虑路径的花费也要考虑启发信息。对于边界上的每一条路径,A都会估计沿路径从初始节点到目标节点的总路径花费。它使用函数cost(p)(即已找到的路径花费)和启发函数h(p)(即从p的结尾到目标的估计花费)。
对于边界上的任意路径p,定义函数f(p)=cost(p)+h(p),指沿着路径p到目标节点的估计总花费。
如果n是路径p的末节点,那么可以描述为:
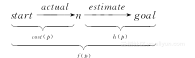
如果h(n)是从节点n到目标节点路径花费的低估,那么f(p)就是从初始节点经过p到目标节点路径花费的低估。
是通过将边界看做按照f(p)进行排序的优先级队列来实现的。
【例3-15】 对例3-4运用A算法进行搜索,并使用例3-12的启发函数。在这个例子中,边界上的路径用路径上最后一个节点来表示,下标是路径的f值。初始边界是:[o10321],因为h(o103)=21,路径花费是0。然后用邻居替换,形成新的边界:[b321,ts31,o10936]。
第一个元素代表路径〈o103,b3〉,它的f的值为:f(〈o103,b3〉)=cost(〈o103,b3〉)+h(b3)=4+17=21。接着b3就被邻居替换,边界变为:[b121,b429,ts31,o10936]。
然后到b1的路径被b1的邻居替换,边界变为:[c221,b429,b229,ts31,o10936]。
接下来,到c2的路径被它的邻居替换,边界变为:[c121,b429,b229,c329,ts31,o10936]。
直到这个状态,搜索一直都在找看起来直接通往目标节点的路径。下面,选择c1被相邻点替代,形成边界:[b429,b229,c329,ts31,c335,o10936]。
直到这一步,到c3有两条不同路径。其中一条不经过c1,它的f值要比经过c1的另外一条路径低。在后面,我们会考虑将其中一个路径剪枝的情况。
这里有两条相同f值的路径。算法没有指定选择哪条。假设下一步选择了通往b4的路径,并被它的相邻点替换,形成边界:[b229,c329,ts31,c335,o10936,o10942]。
然后选择到b2的路径并被邻居替换,但这条路径是空集,所以形成边界:[c329,ts31,c335,b435,o10936,o10942]。
然后到c3的路径被删除,它没有邻居,因此,新的边界变为:[ts31,c335,b435,o10936,o10942]。
注意A算法是如何从一开始寻求多个不同路径的。
最终会找到一个最低花费路径。这个算法会强制尝试很多不同的路径,因为它们其中的一些路径暂时看上去有最低花费。它仍然比最低花费优先和最优优先搜索方法都要好。
【例3-16】 考虑图3-8,对于其他的启发方法,这是个有问题的图。虽然由于启发函数,起始情况从节点s向下搜索,但最终路径的花费变得非常大,因此它选择了在实际最优路径上的节点。
如果解存在,A总是能找到最优解,而且搜索的第一条路径就是最优的,这个性质叫做A的“可采纳性”(admissibility)。它意味着:即使当搜索空间是无限的,如果解存在,那么就一定能找到解,而且找到的第一条路径就是最优解,即从起始节点到目标节点的最低花费路径。
命题3.1(A可采纳性) 如果存在解,A总可以找一个解,并且找到的第一个解就是最优解,如果:
- 分支系数有限(每一个节点有有限个邻居);
- 弧线花费大于ε>0;
- h(n)是从节点n到目标节点的最低花费路径的最小实际花费值的下界。
证明:
A部分:可以找到解。如果弧线的花费都大于ε,ε>0,最终对于边界中所有的路径p,cost(p)会超过任何有限的数。因此,如果存在解,cost(p)会超过解的花费(搜索树的深度不会大于m/ε,这里m是解的花费)。因为分支系数是有限的,在搜索树还没扩展到这个规模之前,只能扩展有限数目的节点,但是那时A算法已经找到了解路径。
B部分:找到的第一条解路径就是最优路径。在最优解路径中,任何一个节点的f值都小于或者等于最优解的f值。这是因为h是从一个节点到目标的实际花费的低估。因此,最优解路径中任何一个节点的f值都小于任何非最优解的f值。所以,当一个节点存在于指向最优解的边界中时,算法永远不会选择一个非最优的路径(因为在每一步中,都会选择f值最小的元素)。因此,在可能选择一个非最优解之前,它肯定已经造访了一个最优路径上的所有的节点,包括每一个最优解。
应该注意到:A的可采纳性不能保证每一个从边界中选择的中间节点位于从开始节点到目标节点的最优路径中。可采纳性使算法不必担心环路问题,保证了第一个解是最优解。但当局部路径最优时,它并不能保证算法不会改变主意。
看一下启发函数是如何提高A算法的效率的,假设c是从起始节点到目标节点的最短路径的花费。A具有可采纳性的启发信息,91扩展集合{p:cost(p)+h(p)如果减少这些集合中第一部分的数量,提高h则会影响A的效率。
3.6.2 搜索策略总结
图3-9中的表格给出了各种搜索策略的总结。
图3-9 搜索策略的总结
注:“终止否”意味着“如果图(可能无穷大)中有一条到目标的路径,该路径上每个节点都有有限个数量的邻居,且每条弧的花费都有正值下界,那么这个方法能否保证搜索终止? ”。那些回答“Yes”的搜索策略的最坏情况下的时间复杂度与路径长度呈指数形式增长。那些不能保证终止的算法有无限最坏情况的时间复杂度。“空间”指的是空间复杂度,它与路径长度是“线性”或是“指数级”关系。
深度优先搜索在空间上与造访路径的长度呈线性增长,但是即使有解存在,它也不能保证能找到解。宽度优先、最低花费优先以及A算法在时间和空间上都是呈指数增长,只要解存在,即使图是无限大的(只要分支系数有界,弧线花费是正非平凡),它们都能保证找到解。
最低花费优先和A搜索算法都能保证第一个找到的解是最低花费的解。









