本节书摘来自华章计算机《人工智能:计算Agent基础》一书中的第1章,第1.5节,作者:(加)David L.Poole,Alan K.Mackworth 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.5 复杂性维度
从自动调温器到在竞争性环境中有多种目标的企业,Agent在环境中行为的复杂性各不相同。Agent的设计存在多个维度的复杂性。这些维度可以分开来考虑,但建造智能Agent时必须组合起来。这些维度定义了人工智能的一个设计空间,空间里的不同点可以通过改变维度值来得到。
这里我们介绍9个维度:模块性、表示方案、规划期、感知不确定性、效用不确定性、偏好、Agent数量、学习和计算限制。这些维度对智能系统的设计空间做了粗糙的划分。有时为了建立智能系统必须做出很多其他的选择。
1.5.1 模块性
第一维是模块性的层次。
模块性是系统可以分解成能被独立理解的交互模块的程度。
模块性对降低复杂性是重要的。它在脑部结构中很明显,是计算机科学的基础,也是任何大型组织的重要部分。
模块性主要通过层次结构分解体现。例如,人的视觉皮层与眼睛组成了一个模块,可以采光,还可以达到更高层的目标,输出一些简化的情景描述。如果模块再分成更小的模块,并以此类推,还可以分成更小的模块,直至分成最原始的操作,我们说模块性是分层的。这种分层组织正是生物学家研究的一部分。大型组织都有一个分层结构,这样高层决策者才不会被细节压倒,也不必过问所有的组织细节。计算机科学中的抽象编程和面向对象编程,就是利用模块性与抽象性,使系统更为简化。19
在模块性维度中,Agent的结构是下列一种:
- 扁平的:系统中没有组织结构;
- 模块化的:系统可被分解成独立的可理解的交互模块;
- 分层的:系统是模块化的,模块本身分解成了交互模块,它们中的每一个又都是一个分层系统,由此循环下去,直到分解成最简单的组件。
在扁平结构或模块化的结构中,Agent主要进行单层抽象上的推理,而在分层结构中,Agent主要是在多层抽象上进行推理。低层结构主要涉及低层抽象的推理。
【例1-3】 一个Agent,比如你自己,从家中到海外的度假目的地去旅行,必须从家里到机场,然后飞到目的地附近的机场,再从飞机场到达目的地。它还可以将实际的移动分解成一系列的腿部运动或车轮滚动。在扁平结构表达中,Agent会选择某一层抽象表达并在该层进行推理。模块化表达将任务分解成很多可以独立解决的子任务(例如,订票,到达出发地机场,到达目的地机场,到达度假的地点)。在分层结构表达中,Agent将用分层的方式解决这些子任务,直至将问题分解成一些简单的问题,例如传送http请求或采取一种特定的步骤。
对于降低构建能在复杂环境中动作的Agent的复杂性,层次分解是重要的。然而,为了考察其他维度,我们首先忽略分层结构,而假设它是一个扁平结构。忽略层次分解这种做法通常适用于中小型问题求解,它适用于低等动物、小型组织或中小型的计算机程序。当问题或系统较为复杂时,就需要一些分层结构了。
如何建立具有分层结构的Agent将在2.3节进行讨论。
1.5.2 表示方案
表示方案维度主要讨论如何描述世界。状态是指世界中影响Agent行为的各种方法。我们可以将世界的状态分解成Agent的内部状态(它的信念状态)和环境状态两个部分。
在最简单层次上,Agent可以以一系列独立的确定状态来进行推理。20
【例1-4】 加热器的自动恒温器一般有两个信念状态:关闭和加热。环境有三个状态:冷、舒适和热。信念状态与环境状态的不同组合,可以组成相对应的六种状态。这些状态可能无法完全形容世界,但它们足以来描述自动恒温器的所有行为了。如果环境处于冷状态,自动恒温器应该调到或停留在加热状态;如果环境处于热的状态,自动恒温器应该调到或停留在关闭状态;如果环境处于舒适状态,自动恒温器停留在现在所在的状态下即可。Agent在加热状态可以加热,而在关闭状态则不能加热。
用状态特征或状态真假的命题进行推理,要比列举一系列状态进行推理更容易些。状态可以用一系列的特征来描述,其中每个特征在每个状态中都有一个值(见4.1节)。
【例1-5】 用来看护房屋的Agent可能必须对灯泡是否被破坏进行推理。它可能有每个开关的位置、状态(是否工作良好,是否短路,是否被破坏)和每个灯泡是否能够正常工作的特征。特征pos_s2有这样的特点:当开关s2调上去时,pos_s2的特征值为up;当开关调下来时,pos_s2特征值为down。房间里照明设备的状态可以用这一系列的特征值来描述。
布尔型命题的值只有真、假两种情况。30个命题经过编码可以有230=1073741824种状态。用这30个命题来阐述和推理可能比使用100多万个状态更容易些。另外,用状态的紧凑表示法会更容易理解些,因为它意味着Agent已经掌握了本领域内的一些规律。
【例1-6】 考虑一个能够识别字母表里字母的Agent,假设这个Agent在观察一个30×30像素的二值图像,这900个网格点中的每一个或开启或关闭(也就是,没有使用任何色彩或灰度信息)。这个行为将决定图像中绘出的是字母{a,…,z}中的哪一个。这个图像有2900种不同的状态,从图像状态到{a,…,z}这26个字母的映射函数会有262900种。我们甚至无法用状态空间来表达这些函数。因此,我们定义了图像的特征,例如线段,并用这一系列的特征定义了从图像到字母的映射函数。
当描述复杂世界时,特征可以依赖于关系与个体。单个个体上的关系是一种属性,个体之间的每一种可能关系上都存在特征。
【例1-7】 在例1-5中看护房屋的Agent可以将灯泡与开关看做个体,并有它们之间的位置关系position与有向连接关系connected_to。用位置关系position(s1,up)21来表示position_s1=up这个特征。当Agent遇到开关并且具有此开关的先验知识时,Agent就能根据关系对这些开关进行推理。
【例1-8】 假设Agent是一个学生课程登记系统,用特征grade来描述一个学生所选的一门课程的成绩。对于每一组学生课程对(student,course),存在特征passed,特征passed依赖于特征grade。用学生个体、课程个体、成绩个体以及grade和passed的关系来进行推理,可能会更容易些。通过定义特征passed是怎样依赖于特征grade的,Agent便能将其应用于每个学生与每门课程。而且,在Agent知道任意个体及其所有特征之前,这些就能完成。
因此,用个体及他们之间的关系进行相关性描述,比对那些特征或命题进行处理,可能更为简便。例如,100个个体和其二值关系可以用1002=10000个命题及210000个状态来表示。通过一系列的关系与个体推理,Agent可以只通过状态对全部类型的个体进行解释推理,而不用枚举特征或命题。Agent有时不得不对无限个体集进行推理,如所有数的集合或所有语句的集合。对于无限个体集,Agent无法用状态或特征进行推理,只能在关系层面上进行推理。
在表示方案维度中,Agent可以通过以下几个方面进行推理:
- 状态;
- 特征;
- 从个体与关系角度进行的关系描述。
一些框架结构是通过状态来描述的,而有些则是通过特征完成的,另外有些则是建立在关系的基础上。
我们将在第3章介绍状态推理,在第4章介绍特征推理,关系推理将在第12章介绍。
1.5.3 规划期
下一个维度是用来说明Agent规划的向前时间的程度。例如,一只狗被叫过来,它会为了未来能得到奖励而奔跑,而不仅仅是为了得到即时的奖励而行动。狗不会为了未来任意无限期长的目标而行动(例如几个月后),而人类可以(例如为了得到明年的假期而努力工作),这个说法看来是对的。
当Agent决定做什么时,能够观察到未来的远近,我们称之为规划期。也就是说,22规划期是Agent认为它的动作结果所能影响的向前程度。从完备性上来说,包括Agent不能及时进行推理的非规划情况。我们把Agent做规划时所考虑的时间点称为阶段。
在规划期维度中,Agent可以分为以下几种:
- 非规划Agent,是指在决定做什么时,不考虑未来的影响,或者不涉及时间的Agent。
- 有限期规划者,是指遵循固定有限时间步的Agent。例如,医生治疗病人,但之前一般会花一些时间做一些检查,所以整个过程可以分为两个阶段来规划:检查阶段、治疗阶段。在退化状况下,Agent可能只进行一个时间步,我们称它是贪婪的或目光短浅的。
- 不确定期规划者,是指能够向前探索几步但是不预先确定多少步的Agent。例如,一个Agent必须到达一个位置,但是预先不确定到达那个位置需要多少步。
- 无限期规划者,是指一直在进行规划的Agent。通常称之为过程。例如,腿式机器人上的稳定模块永远在运行;只有在达到稳定状态时才会停止,因为这种机器人永远在为了防止摔倒而维持稳定。
1.5.4 不确定性
Agent可以假设没有不确定性,也可以把不确定性考虑进去。不确定性可以分为两部分:感知不确定性和效用不确定性。
1.感知不确定性
在一些情况中,Agent能够直接观察到世界的状态。例如,在一些棋类游戏中,或在工人工作的场地,Agent能够精确地知道世界的状态。在许多其他情况中,Agent能对世界的状态有一个带噪声的感知,它所能做的最好的就是在它所感知的状态集上建立概率分布。例如,给定一个病人的症状,医师实际上可能不知道病人患了什么病,而只有病人可能患有疾病的概率分布。
感知不确定性维度主要是用来说明Agent能否从观察中得到世界的状态。
- 完全可观察,是指Agent能够从观察结果中得到世界的状态。
- 部分可观察,是指Agent不能直接观察到世界的状态。出现这种情况可能是相同的观察结果导致很多可能的状态或是观察结果有噪声。
将世界假设为完全可观察的是一种简化假设,其目的是为了使推理更容易进行。
2.效用不确定性
在一些情况中,Agent能够知道动作效果,也就是说,给定一个状态和动作,它能精确地预测出在那种状态下运行那种动作后的状态。例如,与文件系统进行交互的Agent能够在给定的文件系统的状态下预测出删除一个文件后的效果。在很多情况下,Agent很难预测动作效果,最好也只能有一个效果的概率分布。例如,即使一个人知道狗的状态,他可能也不会知道对狗进行命令后的效果,但基于经验,他可能会知道这只狗可能会做些什么。即使是那些他以前没有见过的狗,狗的主人甚至也会知道在他发出命令时那些狗会做些什么。
效用不确定性从动力学方面可以分为:
- 确定性的——动作所导致的状态由动作及之前的状态决定。
- 随机的——对于结果状态,只能给出一个概率分布。
本维度只在世界完全可观察时成立。如果世界是部分可观察的,针对动作效果依赖于不可观察的特征的情况,随机系统可以建立一个确定性系统模型。它是一个单独的维度,因为我们建立的很多框架都是针对完全可观察的、随机动作的情况。
对确定性行为的规划将在第8章介绍,对随机动作及部分可观察域的规划将在第9章介绍。
1.5.5 偏好
Agent会为自身获取更优的结果,做出某一动作优于另一动作选择的唯一原因是其偏好动作会导致更理想的结果。
一些Agent可能会有一个简单的目标,可能是要达到的状态或是要证明为真的命题,例如为主人拿一杯咖啡(在她有咖啡的状态时结束)。另外一些Agent则可能会有更为复杂的偏好。例如,医师一般会考虑痛苦、预期寿命、生命质量、金钱成本(对病人、医生和社会)、在诉讼案例中为决定辩护的能力以及其他一些必要的东西。当这些条件发生冲突时,正如他们总是做的那样,医师必须对这些考虑做出折中处理。24
偏好维度是看Agent是否有:
- 目标。此目标可能是在某一最终状态下要达到的完成目标,或是在所有已访问过的状态中必须被保持的目标。例如,机器人的目标可能是拿到两杯咖啡和一只香蕉,并且在这期间不能制造混乱或伤害任何人。
- 复杂偏好。复杂偏好涉及在不同时期权衡各种期望的结果。序数(ordinal)偏好就是只注重偏好的排序。基数(cardinal)偏好涉及有关值的大小。例如,比起黑咖啡来说,山姆更喜欢卡布奇诺,而比起茶来说,更喜欢黑咖啡,这是序数偏好。基数偏好给定等待时间与饮料类型间的权衡,各种味道之间的权衡,如果咖啡的味道特别好,Sam就能在等待咖啡的过程中容忍时间的煎熬。
目标将在第8章介绍,复杂偏好将在第9章介绍。
1.5.6 Agent数量
仅一个Agent在它所属的环境里进行推理就已经足够困难。然而,如果有多个Agent进行推理将更为困难。多Agent背景中的Agent应该具备对其他Agent进行策略性推理的能力,其他Agent可能会对它进行欺骗或操纵,也可能会与它进行合作。对于多Agent,因为其他Agent可以采取确定性策略,因此最优的选择经常是随机动作。即使当Agent之间进行合作,具有共同目标时,协商与交流的问题也使得多Agent推理更具挑战性。然而,许多领域包含多个Agent,而且忽略其他Agent策略的推理并不是最好的方式。
从单个Agent的角度来看,Agent数量维度主要是考虑Agent是否进行:
- 单个Agent推理。Agent会假设其他的Agent为环境的一部分。如果没有其他的Agent,或者其他Agent的动作不会因为这个Agent的动作而改变,那么这个假设是合理的。
- 多Agent推理。Agent会将其他Agent的推理考虑进来。当其他Agent的目标或偏好部分依赖于此Agent的行为,或Agent必须与其他Agent通信时,这种情况就会发生。
如果Agent同时进行动作,或环境只是部分可观察的,那么与其他Agent一起进行的推理将会更为困难。多Agent系统将在第10章介绍。25
1.5.7 学习
在某些情况下,Agent设计者可能为Agent建立了一个比较好的模型及环境。但通常情况下,Agent设计者无法建立完美的模型,Agent需要一些先验知识或其他的资源来帮助它进行决策。
学习维度由以下两方面决定:
- 已有的知识。
- 学到的知识(从数据或先前经验中获取)。
学习一般意味着要找到与数据相符的最好模型,有时候这就像调整固定参数集一样简单,但这也就意味着要从一类表达中选择最优的表达。学习本身就是一个很宽泛的领域,但不是孤立于人工智能的其他领域。除了拟合数据外,还有其他很多问题,包括如何合成背景知识,需要搜集什么样的数据,如何表达这些数据以及结果,什么样的学习偏差是合适的,怎样合理使用学习到的知识去影响Agent的行为。
学习将会在第7、11和14章介绍。
1.5.8 计算限制
有时候Agent可以足够迅速地决定它的最好的行为,但通常会有很多计算资源限制,阻碍实施这些最好的行为。也就是说,由于Agent的内存限制,尽管某个动作是最好的,但是它可能不能够迅速地找到这个最好的动作。例如,如果Agent必须现在动作,在十分钟之前花费十分钟的时间来推理最好应该做什么,就没有什么用处。通常情况下,Agent必须权衡得到一个解所花费的时间和解的好的程度;有时候迅速地找到一个合理解可能要优于花费更长时间来寻求一个更好的解,因为在计算期间世界可能会改变。
计算限制维度由Agent是否具有以下性质来决定:
- 完全理性:Agent可以推出最佳行动方案,而不考虑有限的计算资源;
- 有限理性:在给定的计算限制上,决定它所能找到的最佳行为方案。
计算资源限制包括计算时间、内存和数值精度。其中数值精度的限制是由于计算机不能准确地表示实数而引起的。
任意时间算法是解的质量随时间的推移而提高的一种算法。实际上,它可以在任意时间产生当前最佳解,但如果给定更多的时间,可能会产生更好的解决方案。通过允许Agent存储迄今为止发现的最佳解,我们可以确保得到解决方案,并且解决方案的质量不会下降。26然而,等待Agent动作需要花费一定的时间;对于Agent来说,在找到最佳解之前动作可能更好些。
【例1-9】 图1-5说明了任意时间算法的计算时间是如何来影响解的质量的。Agent实施一个动作时,能做一些计算来决定要做什么。绝对的解的质量,在时间零点执行的动作,如顶端的短划线所示,会随着Agent利用时间推理而提高。然而,花时间去行动会有损失。在本图中,如底部的虚线所示,这个损失与Agent执行动 图1-5 对任意时间算法来说,解的质量是一个时间函数。Agent必须选择一个动作。随着时间的推移,Agent能够决定更好的动作。短划线表示的是,如果它一开始就实施,Agent迄今为止所能找到的最佳动作值。虚线表示Agent在等待行动时减少的行为值。实线表示Agent的净值,是一个时间函数作之前的时间成比例。这两个值相加就能得到折扣的质量,依赖于时间的计算值,这就是中间部分的实线。如图1-5所示,一个Agent计算大约需要2.5个时间单元,然后执行动作,在该点折扣质量达到最大值。如果计算持续长于4.3个时间单元,产生的折扣质量将会比仅仅输出算法的初始猜测而实际不进行计算时更糟糕。解的质量有一个跳跃性的提高是非常典型的;当现有的最好解发生变化时,解的质量会有一个跳跃性的变化。然而,与等待相关的损失通常并不是一条简单的直线。
将有限理性考虑在内,Agent必须决定是应该立即实施动作还是进行更多的思考。这是一项具有挑战性的难题,因为Agent通常无法确定,当它仅花费多一点时间进行推27理时,到底会有多好。而且,在考虑是否进行推理上花费的时间会减少实际推理的可用时间。无论如何,有限理性可以作为近似推理的基础。
1.5.9 多维交互
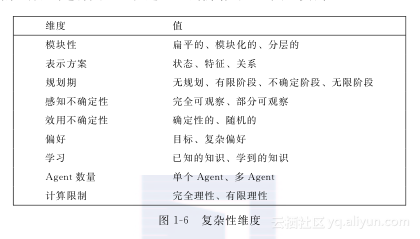
图1-6总结了一系列复杂性的维度。不幸的是,我们无法单独研究这些维度,因为它们以各种复杂的方式进行交互。在这里,我们给出一些交互实例。
维度值模块性扁平的、模块化的、分层的表示方案状态、特征、关系规划期无规划、有限阶段、不确定阶段、无限阶段感知不确定性完全可观察、部分可观察效用不确定性确定性的、随机的偏好目标、复杂偏好学习已知的知识、学到的知识Agent数量单个Agent、多Agent计算限制完全理性、有限理性
表示维度与模块性维度进行交互。一些层次上的模块甚至简单到可以用一系列有限状态集进行推理,而其他的抽象层次可能要对个体及关系进行推理。例如传送机器人,维持平衡的那个模块可能仅有一小部分状态,而必须优先考虑将多个包裹传递给多个人的模块可能必须对多个个体(比如,人、包裹和房间等)及他们之间的关系进行推理。在更高层次上,对一天内执行的动作进行推理可能只需几个状态来概括这一天内的不同阶段(如,可能有三个状态:忙时、可请求时和再充电时)。
规划期与模块性维度进行交互。例如,在较高层次时,跑过来并得到治疗后,小狗可能会得到即时的奖励。当决定将它的爪子放在哪里时,可能会需要很长时间来得到奖励,这时就不得不规划一个无限阶段。
感知不确定性可能对推理的复杂度有很大影响。对Agent来说,当它知道世界的状态时比不知道时更容易进行推理。尽管对状态的感知不确定性很好理解,28但是对个体及关系的感知不确定性是现在研究的热点。
效用不确定性与模块性维度进行交互:在分层结构的某个层次上,某个动作可能是确定性的,但在另外的层次则可能是随机的。例如,你跟一个你正试图讨好的同伴飞到巴黎,在某个层面上来说,你可能知道你所在的位置(巴黎),在较低层面上,你可能会完全迷失并不知道自己在哪儿。在负责维持平衡的更低层面上,你会知道你在哪儿:你正站在地上。在最高层面上,你可能根本不能确定是否给同伴留下了好印象。
偏好模型与不确定性交互,是因为Agent必须权衡满足有一定概率的主要目标,还是满足具有更高概率的次要目标。这个问题将在9.1节进行讨论。
模块性可以使用多Agent。设计单个Agent的一种方式是构造多个拥有共同目标的交互Agent,这样能够使较高层次的Agent智能地执行动作。一些研究者,例如Minsky[1986],认为智能是非Agent社会的一个涌现特征。
学习可以通过特征来进行描述,决定哪个特征值能够最好地预测其他特征的值。然而,学习也可以通过个体及关系来进行。我们现在已在学习层次结构、在部分可观察领域内学习和多Agent学习等方面做了很多工作。即使不考虑与其他多重维度的交互,这些研究方向本身也都具有很大的挑战性。
维度中模块性和有限理性能使推理更有效。虽然它们使形式化体系变得更为复杂,但却能够通过将系统分解成更小的组件并提供所需的近似值,使Agent能够在有限时间和有限的内存中及时地执行动作,来帮助构建更为复杂的系统。
