本节书摘来自华章计算机《大规模Java平台虚拟化与调优》一书中的第2章,第2.1节,作者:(美)Emad BenjaminLiang) 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第2章 现代化可扩展的数据平台
尽管你可以采用多种方式现代化应用的架构,但是核心的趋势如下:
-围绕Spring框架所提供的灵活性现代化应用架构;
-现代化数据。
就数据现代化来说,现在有很多不同的方式。本章主要关注的是日渐流行的一种趋势,那就是使用可水平扩展的内存数据库来提升扩展性和响应时间。在这里使用VMware vFabric SQLFire来阐述内存数据管理系统的功能,你可以使用它来构建可水平扩展且支持硬盘持久化的数据fabric。
讨论这种工作负载也会帮助Java平台的工程师强化其Java平台的调优能力。这种类型的内存数据库主要由第2类的工作负载所组成。但是,根据你所选择的拓扑结构,你可能还需要处理第3类的工作负载。理解如何优化这种系统能够让你解决可能面临的最难的优化任务。在深入学习如何优化之前,最好先理解一下此类工作负载的功能。
vFabric SQLFire是一个内存分布式数据管理平台,它可以跨多个虚拟机(virtual machine,VM)、Java虚拟机以及vFabric SQLFire服务器来管理应用数据。借助于动态复制(dynamic replication)以及分区(partitioning),vFabric SQLFire在平台中提供了如下的特性:数据持久化、基于触发器的事件通知、并行执行、高吞吐、低延迟、高扩展性、持续可用性以及WAN分布。
图2-1展示了vFabric SQLFire作为数据中间层,组织数据并将其交付给使用数据的企业级应用。随着使用数据的应用的增长,中间数据层需要进行扩展从而适当地应对季节性的工作负载变化。vFabric SQLFire是一个完整的数据管理系统,能够管理事务和数据持久化,因此使用数据的企业级应用可以依赖于vFabric SQLFire,将其作为记录系统(system of record)。
" >
图2-1 使用vFabric SQLFire的企业级数据管理
对于额外的持久化操作,数据可以写入后端支撑的存储(如关系型数据库)或其他硬盘存储,以实现归档的目的。vFabric SQLFire提供了完整的持久化机制,使用了其自身原生的非共享持久化机制(native shared-nothing persistence mechanism)。图2-2阐述了vFabric SQLFire如何同步/异步的在外部数据存储中读取和写入数据。
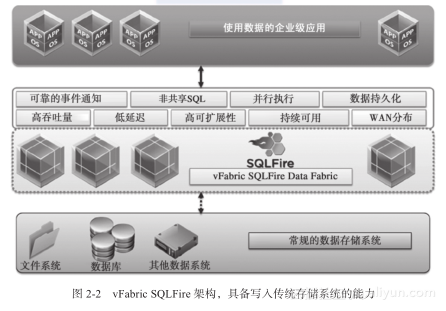
图2-2 vFabric SQLFire架构,具备写入传统存储系统的能力
vFabric SQLFire基于VMware vFabric GemFire分布式数据管理产品以及Apache Derby项目。如图2-3所示,Apache Derby用于其关系型数据库关系系统(RDBMS)组件、Java数据库连接(Java Database Connectivity,JDBC)驱动、查询引擎以及网络服务器。GemFire的分区技术被用来实现vFabric SQLFire的水平分区。
" >
图2-3 vFabric SQLFire内部架构
vFabric SQLFire增强了Apache Derby组件,如查询引擎、SQL界面、数据持久化以及数据回收(data eviction),另外还提供了其他的组件,如SQL命令、存储过程、系统表、函数、持久化硬盘存储、监听器与定位器(locator),据此来操作高度分布式与容错性的数据管理集群。
最佳实践1:通用的分布式数据平台
当数据需要以最快的速度进行交付时(也就是毫秒和微秒级),正确的方式是将vFabric SQLFire搭建为企业级数据fabric系统。如图2-2所示, 在内存中引入一个通用的数据交付和使用层,它服务于众多需要数据的企业级应用。这样企业级应用就能从vFabric SQLFire的可扩展性、可用性以及执行速度等特性中受益。
尽管vFabric SQLFire是具有强大功能的数据平台,主要用于大事务量的数据转移(每秒钟上千的事务),但是它也可以用于较低事务量的场景之中(每秒钟几十或上百个事务),实现企业级应用响应时间以及数据库弹性的快速提升。vFabric SQLFire遵循SQL-92,这样客户的企业级应用重新配置来使用vFabric SQLFire相对就没有侵入性。
2.1 SQLFire的拓扑结构
搭建vFabric SQLFire的3种主要拓扑结构如下:
- 客户端/服务器(client/server)
- 端对端(peer-to-peer)
- 多点(multisite)
以上的每种拓扑结构可以单独使用,也可以组合起来扩展形成功能完备的分布式数据管理系统。
2.1.1 客户端/服务器拓扑结构
客户端/服务器拓扑结构包含了两层:客户端层和服务器层,如图2-4所示。
客户端层与服务器层进行交互,以查找和更新来自于服务器层的数据对象。
" >
客户端/服务器拓扑结构是第三类的工作负载,在这里成百上千的Java客户端(运行在应用服务器中的企业级应用)会使用来自于vFabric SQLFire集群中的数据,这个集群可能会有十几个SQLFire JVM所组成。
服务器层由众多的vFabric SQLFire节点所组成,每个都运行在自身的JVM进程中,这个进程提供网络分布式、内存以及磁盘持久化数据管理的功能。进一步来讲,尽管每个vFabric SQLFire成员运行在其自身的JVM进程空间之中,但是vFabric SQLFire成员之间确实也存在网络连接,因此形成了一个数据管理集群并服务于客户端层。
客户端通常是分布于组织中的企业级应用,位于vFabric SQLFire集群之外,但是需要对vFabric SQLFire进行数据访问。客户端会使用一个客户端驱动程序,对Java应用来说就是轻量级的JDBC驱动,对.NET应用来说就是ADO.NET。瘦客户端并不会持有或持久化集群数据,它们并不会直接参与集群中所执行的分布式查询。客户通常会有成百上千个使用数据的企业级应用,这些应用会访问vFabric SQLFire集群中所管理的数据,但是客户端本身并不是vFabric SQLFire集群的一部分。
客户端会使用两个或更多可容错的定位器(locator)进程,定位器进程会提供对vFabric SQLFire成员的定位服务。vFabric SQLFire定位器进程会告知新连接的端点(peer)以及瘦客户端如何去连接正在运行中的已有端点。在客户端/服务器部署拓扑结构中,对于瘦客户端到可用vFabric SQLFire成员间的连接,定位器会执行连接负载均衡以及动态负载调节的功能。
最佳实践2:客户端/服务器拓扑结构
对于企业级应用来讲,客户端/服务器拓扑结构是最为常用的。当成千上万的企业级客户端应用需要使用vFabric SQLFire数据管理系统中的数据时,客户端/服务器拓扑结构是最合适的。在客户端/服务器拓扑结构中,客户端可以对数据进行完整地访问和控制,而不必成为vFabric SQLFire内存数据管理系统的一部分。
在这种拓扑结构中,尤其是在生产环境的部署中,要添加-mcast-port=0设置以关闭组播发现(multicast discovery)功能,采用定位器的方式来定位vFabric SQLFire节点。
在vFabric SQLFire系统中,需要保证vFabric SQLFire定位器进程的高可用性,这可以通过将不同的实例运行在不同的物理机上来实现。定位器的配置通过在命令行中提供-locators参数来实现,以逗号分隔所有可用的定位器。
当企业级应用有如下的需求时,考虑使用客户端/服务器拓扑结构:
动态服务器发现(dynamic server discovery):vFabric SQLFire的服务器定位器工具动态跟踪服务器进程并将客户端连接到新的服务器上,使得客户端不必直接了解集群成员信息。客户端只需知道如何连接到定位器服务即可,它们不必了解在给定的某个时间点数据服务器在哪里运行以及有多少可用的数据服务器。
服务器负载平衡:vFabric SQLFire服务器的定位器会跟踪当前所有服务器的负载信息,并将新的客户端连接到负载最低的服务器上。vFabric SQLFire提供了一个默认的服务器负载探测器(probe)。如果要自定义某个服务器负载的计算方式,你可以实现自定义的插件。
服务器连接调节(server connection conditioning):客户端连接可以配置为线路透明并且能够转移到不同的服务器上,这样当新的服务器启动后,服务器的整体使用率就能进行重新平衡。当添加新的服务器或服务器从崩溃以及其他故障中恢复时,这有助于快速进行负载调节。
2.1.2 端到端拓扑结构
在端到端(peer-to-peer)拓扑结构中,如图2-5所示,两个或更多交互的vFabric SQLFire服务器组成了一个分布式系统。数据会根据数据表所配置的冗余规则确定如何分布。
端到端是第二类的工作负载,会有十几个SQLFire JVM互相交互。
最佳实践3:端到端多宿主主机
一组互相访问的vFabric SQLFire 服务器,没有客户端或者只有很少的客户端(如会话状态数据、Web内容、后勤维护部门或者提供对数据进行single-hop访问模式的后端处理类型)访问它们。
应用需要几个端点客户端(不同于客户端/服务器拓扑结构中上百的客户端)的情况适合于端到端拓扑结构。部署众多的端点会增加每个成员的缓冲和socket消耗。
从管理角度来讲会更为便利。在嵌入式集群中,没有必要管理任何外部的进程来部署vFabric SQLFire端点。例如,如果你将vFabric SQLFire嵌入到Java应用服务器集群之中,每个应用服务器与相关的vFabric SQLFire端共享相同的进程堆。
如果运行在多宿主主机(multihomed machine)中,你可以指定一个非默认的网络适配器来进行通信。在非组播的端对端场景中,通信会使用bind-address属性。这个地址必须映射到分布式系统中所有vFabric SQLFire服务器一致的子网中。
2.1.3 冗余区
在vFabric SQLFire中,你可以搭建各种冗余区(redundancy zone),这样要复制的内容(或冗余副本)就不会放到相同的物理硬件上。你可以在每个vFabric SQLFire成员上设置redundancy-zone启动属性,将其设置为特定的冗余区的名字。通用的实践是这些冗余区的名字与底层物理硬件的名字类似,这样就没有冗余vFabric SQLFire成员放置到与初始分区相同的物理硬件/服务器上。
2.1.4 全球的多点拓扑结构
在vFabric SQLFire中,你可以搭建多点(multisite)拓扑结构,它可以跨多个数据中心,来实现active-active架构、灾难恢复以及WAN分布类型的部署。你可以构建单个的数据fabric,用于数据中心距离小于60英里的情况,对于距离大于60英里的情况,要使用vFabric SQLFire WAN网关。
一种特殊的多点拓扑结构就是全球多点,如图2-6所示。
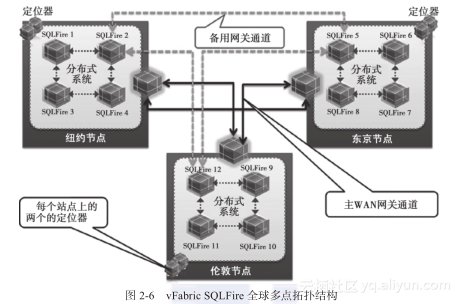
这里有三个全球性的分布式(纽约、东京与伦敦)节点,每个节点都有一个本地的分布式系统。在每个节点内,都配置了一个网关,当出现故障事件或要在全世界范围内提供一致的数据视图时,该网关会提供数据分布式管理的功能。网关会按照可容错的方式成对工作。每一对中的主成员负责处理到其他节点的数据复制。主成员会有一个冗余的网关进程作为备用,如果初始的主网关进程出现故障,那么这个备用的网关进程就会成为主网关进程。同常规的客户端/服务器拓扑结构一样,每个节点都有两个或更多的定位器进程,它们提供了本地节点内成员的发现服务。
最佳实践4:多点
在多点配置中,每个分布式系统的操作都独立于其他相连接的系统。要在节点间进行复制的表在创建时必须要使用相同的表名和列定义。除此之外,网关发送者和接收者必须在每个系统中将逻辑网关连接指定到物理网络连接。对于配置为使用网关发送者的表,数据操纵语言(data manipulation language,DML)事件会自动转发到网关发送者,以便分发到其他的节点。事件会放到网关队列中,并且异步分发到远程节点上。插入/更新以及删除操作会发送到其他的站点上,除非删除是过期(expiration)或回收(eviction)的一部分。但是,查询、数据定义语言(data definition language,DDL)、事务以及过期并不会分发到其他远程节点上。
参与WAN复制的每个vFabric SQLFire分布式系统都必须使用一个或更多的定位器,以用于成员发现。WAN复制不支持组播发现机制。
WAN部署会在vFabric SQLFire系统上增加消息处理的需求。为了避免与WAN消息相关的连接饿死现象,要为参与WAN部署的vFabric SQLFire成员设置conserve-sockets=false属性。
启用WAN的表必须要存在于每个你想连接的分布式系统之中。
你可以配置分区表和复制表(replicated table)使用网关发送者。但是,你创建的复制表所在的服务器组必须与网关发送者一致,这是在CREATE TABLE语句中指定的。
在往表里填充数据之前,必须要启用整个WAN系统(也就是,全球多点系统),或者你必须在启用WAN监听器接收WAN流量之前,往一个新增加的节点中填充表。这种要求能够保证WAN站点从一开始就保持同步。如果做不到这一点的话会导致数据更新操作时出现异常。
正常情况下,当使用网关hub时,你应该使用合并(conflation)功能,这样只有最近的更新会传递到远程站点上。当使用合并特性时,在队列中之前存在的更新记录会被丢弃掉,以便于接受队列中更近的更新。启用合并能够达到最佳的性能。你可以在监听器的定义中将ENABLEBATCHCONFLATION属性设置为true。只有应用程序依赖于查看每次更新的情况下(例如,如果某一个远程网关有表触发器或者需要知道每一个状态变化的AsyncEventListener),你才应该关闭合并功能。
在使用网关的多点场景中,如果站点间的连接没有优化到最佳的吞吐量,那么消息可以备份在网关队列中。如果接收队列因为缓存空间不足导致溢出的话,那么它可能会与发送者产生不同步,接收者并不能了解到这种情况。网关的socket-buffer-size属性值应该与全球多点拓扑结构中交互的网关相匹配。
通过调节MAXQUEUEMEMORY属性来适应所需的内存,从而避免可能出现队列溢出到磁盘上。这是队列在溢出到磁盘之前,可以使用的最大内存量,是以MB作为单位的,默认值是100MB。如果你更关注可靠性而不是高速度,推荐使用溢出到磁盘功能。进一步对MAXQUEUEMEMORY属性的调优包括同时调节BATCHSIZE和BATCHINTERVAL,直到满足合适的服务水平协议(service level agreement,SLA),在这里BATCHSIZE是一个批次可以包含的最大消息数(默认是100条消息),而BATCHINTERVAL是两次发送批次消息之间可以等待的最大毫秒数(默认是1000毫秒)。
