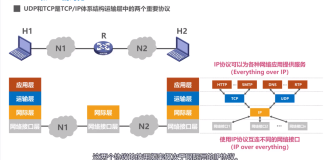
客户问题场景

如上图所示,用户业务服务器(ApplicationServer)上面发起HTTP GET/PUT请求,经过SLB到达后端服务器(HBase-Rest-Server), 一般请求链路耗时大概100ms左右,但是会有一定的概率出现耗时很长(超过3s)。
问题排查
1. 抓包分析
通过在HBase-REST-Server上面抓包,发现有SYN重传,引起SYN重传的原因是上图所示的Queue满了,导致新请求的SYN包丢弃。
Linux的SYN重传通过net.ipv4.tcp_syn_retries参数控制重传次数,每次重传的时间间隔为(第一次3s,第二次6s,第三次12s,每增加一次时间间隔翻倍),所以当SYN包被丢弃后,第一次会经过3s后进行重传,这个3s也跟上述的超时3s比较吻合。
2. 参数调整
从上面可以看出Queue满导致重传,所以适当增加Queue的大小可以解决重传,Queue的大小受一些参数来控制:
- http server启动设置的backlog大小
- net.core.somaxconn
- tcp_max_syn_backlog
最终通过增加上述参数,问题解决。