本节书摘来自华章计算机《程序设计解题策略》一书中的第1章,第1.4节,作者:吴永辉 王建德 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.4 利用改进型的二叉查找树优化动态集合的操作
我们知道,二叉查找树(binary search tree)能够支持多种动态集合操作,因此在程序设计竞赛中,二叉查找树起着非常重要的作用,它可以用来表示有序集合、建立索引或优先队列等。作用于二叉查找树上的基本操作时间是与树的高度成正比的:对于一棵含n个节点的二叉查找树,如果呈完全二叉树结构,则这些操作的最坏情况运行时间为O(log2n);但如果呈线性链结构,则这些操作的最坏情况运行时间退化为O(n)。针对二叉查找树这种不平衡、不稳定的弊病,人们做了大量改进优化的尝试,使其基本操作在最坏情况下的性能尽量保持良好。本节将介绍两种改进型的二叉查找树:
1) 伸展树(splay tree)。
2) 红黑树(redblack tree)。
与普通的二叉查找树一样,这两种“改进版”同样具备有序性,即树中每一个节点x都满足:该节点左子树中的每一个元素都不大于x,而其右子树中的每一个元素都大于x。但不同的是,树的高度保持近似平衡,使得每一步操作在最坏情况下亦有良好的运行时间,并且在运行过程中保持稳定和高效,可在O(log2n)时间内完成查找、插入和删除(n为树中元素数)。
1.4.1 改进型1:伸展树
这里要介绍的伸展树是一种改进型的二叉查找树。虽然它并不能完全保证树结构始终平衡,但对于伸展树的一系列操作,我们可以证明其每一步操作的平摊复杂度都是O(log2n)。所以从某种意义上说,这种改进后的二叉查找树能够基本达到一种平衡状态。至于伸展树的空间要求与编程复杂度,在各种树状数据结构中都是很优秀的。
伸展树的基本操作包括:
1) 伸展操作,即伸展树作自我调整。
2) 判断元素x是否在伸展树中。
3) 将元素x插入伸展树。
4) 将元素x从伸展树中删除。
5) 将两棵伸展树S1与S2合并成为一棵伸展树(其中S1的所有元素都小于S2的元素)。
6) 以x为界,将伸展树S分离为两棵伸展树S1和S2,其中S1中所有元素都小于x,S2中的所有元素都大于x。
其中基本操作2)~6)都是在伸展操作的基础上进行的。
(1) 伸展操作——Splay(x,S)
伸展操作是在保持伸展树有序性的前提下,通过一系列旋转将伸展树S中的元素x调整至树的根部。在调整的过程中,要分以下三种情况分别处理。
情况1:节点x的父节点y是根节点。
这时,如果x是y的左孩子,我们进行一次Zig(右旋)操作;如果x是y的右孩子,则进行一次Zag(左旋)操作。经过旋转,x成为二叉查找树S的根节点,调整结束。我们称这种旋转为单旋转,如图1.4-1所示。
情况2:节点x的父节点y不是根节点,y的父节点为z且x与y同时是各自父节点的左孩子或者同时是各自父节点的右孩子。
这时,进行一次Zig-Zig操作或者Zag-Zag操作,即假设当前节点为x,x的父节点为y,u的父节点为z,如果y和x同为其父亲的左孩子或右孩子,那么先旋转y,再旋转x。我们称这种旋转为一字形旋转,如图1.4-2所示。
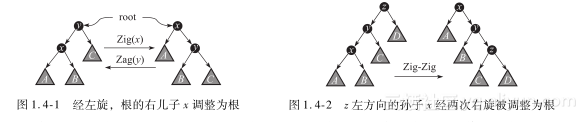
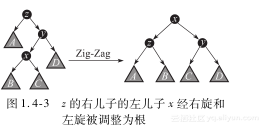
情况3:节点x的父节点y不是根节点,y的父节点为z,x与y中一个是其父节点的左孩子而另一个是其父节点的右孩子。
这时,进行一次Zig-Zag操作或者Zag-Zig操作,即连续旋转两次X。我们称这种旋转为之字形旋转,如图1.4-3所示。
如图1.4-4所示,执行Splay(1,S),我们将元素1调整到了伸展树S的根部,再执行Splay(2,S),如图1.4-5所示。
我们从直观上可以看出经调整后,伸展树比原来“平衡”了许多。伸展操作的过程并不复杂,只需要根据情况进行旋转就可以了,而三种旋转都是由基本的左旋和右旋组成,实现较为简单。
利用Splay操作,我们可以在伸展树S上进行如下运算。
(2) 判断元素x是否在伸展树S表示的有序集中——Find(x,S)
首先,与在二叉查找树中的查找操作一样,在伸展树中查找元素x。如果x在树中,则将x调整至伸展树S的根部(执行Splay(x,S))。
(3) 将元素x插入伸展树S表示的有序集中——Insert(x,S)
与处理普通的二叉查找树一样,将x插入到伸展树S中的相应位置上,再将x调整至伸展树S的根部(执行Splay(x,S))。
(4) 将元素x从伸展树S所表示的有序集中删除——Delete(x,S)
首先,用在二叉查找树中查找元素的方法找到x的位置。如果x没有孩子或只有一个孩子,那么直接将x删去,并通过Splay操作,将x节点的父节点调整到伸展树的根节点处。否则,向下查找x的后继y,用y替代x的位置,最后执行Splay(y,S),将y调整为伸展树的根。
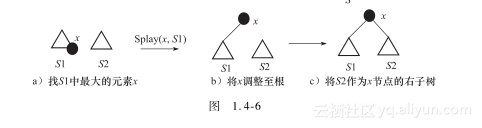
(5) 将两棵伸展树S1与S2合并成为一棵伸展树——Join(S1,S2)(其中S1的所有元素值都小于S2的所有元素值)
首先,找到伸展树S1中最大的一个元素x,再通过Splay(x,S1)将x调整到伸展树S1的根。然后再将S2作为x节点的右子树。这样,就得到了新的伸展树S,如图1.4-6所示。
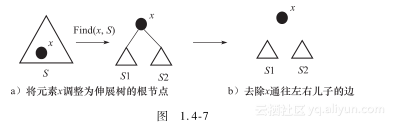
(6) 以x为界,将伸展树S分离为两棵伸展树S1和S2——Split(x,S)(其中S1中所有元素都小于x,S2中的所有元素都大于x)
首先执行Find(x,S),将元素x调整为伸展树的根节点,则x的左子树就是S1,而右子树为S2。然后去除x通往左右儿子的边,如图1.4-7所示。
在伸展操作的基础上,除了上面介绍的五种基本操作,伸展树还支持求最大值、最小值、前驱、后继等多种操作,这些基本操作也都是建立在伸展操作的基础上的。
由上述操作的实现过程可以看出,伸展树基本操作的时间效率完全取决于Splay操作的时间复杂度。下面,我们用会计方法来分析Splay操作的平摊复杂度。
首先,我们定义一些符号:S(x)表示以节点x为根的子树。S表示伸展树S的节点个数。令μ(S)=log2s」,μ(x)=μ(S(x)),如图1.4-8所示。
我们用1元钱表示单位代价(这里我们将对于某个点访问和旋转看作一个单位时间的代价)。定义伸展树不变量:在任意时刻,伸展树中的任意节点x都至少有μ(x)元的存款。
在Splay调整过程中,费用将会用在以下两个方面:
1) 为使用的时间付费。也就是每一次单位时间的操作,我们要支付1元钱。
2) 当伸展树的形状调整时,我们需要加入一些钱或者重新分配原来树中每个节点的存款,以保持不变量继续成立。
下面给出关于Splay操作花费的定理:
【定理1.4-1】 在每一次Splay(x,S)操作中,调整树的结构与保持伸展树不变量的总花费不超过3μ(S)+1。
证明:用μ(x)和μ′(x)分别表示在进行一次Zig、Zig-Zig或Zig-Zag操作前后节点x处的存款。下面,我们分三种情况分析旋转操作的花费。
情况1:Zig或Zag(如图1.4-9)。
我们进行Zig或者Zag操作时,为了保持伸展树不变量继续成立,我们需要花费:
μ′(x)+μ′(y)-μ(x)-μ(y)=μ′(y)-μ(x)
≤μ′(x)-μ(x)
≤3(μ′(x)-μ(x))
=3(μ(S)-μ(x))
此外我们花费另外1元钱用来支付访问、旋转的基本操作。因此,一次Zig或Zag操作的花费至多为3(μ(S)-μ(x))。
情况2:Zig-Zig或Zag-Zag(如图1.4-10)。
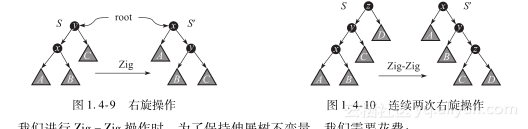
我们进行Zig-Zig操作时,为了保持伸展树不变量,我们需要花费:
μ′(x)+μ′(y)+μ′(z)-μ(x)-μ(y)-μ(z)=μ′(y)+μ′(z)-μ(x)-μ(y)
=(μ′(y)-μ(x))+(μ′(z)-μ(y))
≤(μ′(x)-μ(x))+(μ′(x)-μ(x))
=2(μ′(x)-μ(x))
与第一种情况一样,我们也需要花费另外的1元钱来支付单位时间的操作。
当μ′(x)<μ(x)时,显然2(μ′(x)-μ(x))+1≤3(μ′(x)-μ(x))。也就是进行Zig-Zig操作的花费不超过3(μ′(x)-μ(x))。
当μ′(x)=μ(x)时,我们可以证明μ′(x)+μ′(y)+μ′(z)<μ(x)+μ(y)+μ(z),也就是说我们不需要任何花费保持伸展树不变量,并且可以得到退回来的钱,用其中的1元支付访问、旋转等操作的费用。为了证明这一点,我们假设μ′(x)+μ′(y)+μ′(z)>μ(x)+μ(y)+μ(z)。
联系第一种情况,我们有μ(x)=μ′(x)=μ(z)。那么,显然μ(x)=μ(y)=μ(z)。于是,可以得出μ(x)=μ′(z)=μ(z)。令a=1+A+B,b=1+C+D,那么就有:
[log2a]=[log2b]=[log2(a+b+1)]①
我们不妨设b≥a,则有:
[log2(a+b+1)]≥[log2(2a)]=1+[log2a]>[log2a]②
①与②矛盾,所以我们可以得到μ′(x)=μ(x)时,Zig-Zig操作不需要任何花费,显然也不超过3(μ′(x)-μ(x))。
情况3:Zig-Zag或Zag-Zig(如图1.4-11)。
与情况2类似,我们可以证明,每次Zig-Zag操作的花费也不超过3(μ′(x)-μ(x))。
以上三种情况说明,Zig操作花费最多为3(μ(S)-μ(x))+1,ZigZig或ZigZag操作最多花费3(μ′(x)-μ(x))。那么将旋转操作的花费依次累加,则一次Splay(x,S)操作的费用就不会超过3μ(S)+1,如图1.4-12所示。
也就是说,对于伸展树的各种以Splay操作为基础的基本操作的平摊复杂度,都是O(log2n)。可见,伸展树是一种时间效率非常优秀的数据结构。
1.4.2 改进型2:红黑树
红黑树也是一种自平衡的二叉查找树。虽然同伸展树、平衡二叉树一样,它可以在O(log2N)时间内完成查找、插入和删除等操作,但其统计性能要更好一些,因此红黑树在很多地方都有应用,例如C++STL中的很多部分(目前包括set、multiset、map、multimap)应用了红黑树的变体;Java提供的集合类TreeMap本身就是一个红黑树的实现。红黑树的操作有着良好的最坏情况运行时间,任何不平衡都会在三次旋转之内解决,为我们提供了一个比较“便宜”的解决方案。
红黑树,顾名思义,就是通过红黑两种颜色域保证树的高度近似平衡。它的每个节点是一个五元组:color(颜色),key(数据),left(左孩子),right(右孩子)和p(父节点)。红黑树具有如下性质。
【性质1.4-1】 节点是红色或黑色。
【性质1.4-2】 根是黑色。
【性质1.4-3】 所有叶子都是黑色(叶子是NIL节点)。
【性质1.4-4】 如果一个节点是红的,则它的两个儿子都是黑的。
【性质1.4-5】 从任一节点到其叶子的所有简单路径都包含相同数目的黑色节点(如图1.4-13)。
这五条性质凸显了红黑树的一个关键特征:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。为什么呢?性质1.4-4暗示着任何一个简单路径上不能有两个毗连的红色节点,这样,最短的可能路径全是黑色节点,最长的可能路径有交替的红色和黑色节点。同时根据性质1.4-5知道:所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
由于红黑树也是二叉查找树,因此红黑树上的查找操作与普通二叉查找树上的查找操作相同。然而,红黑树上的插入操作和删除操作可能会导致红黑树性质的丧失。恢复红黑树的性质需要少量节点的颜色变更(变更颜色的节点数不超过O(log2N),非常快速)和不超过三次的树旋转(插入操作仅两次)。虽然插入和删除操作较复杂,但实际时间仍可以保持为O(log2N)次。
1.插入操作
插入操作可以概括为以下3个步骤。
步骤1:查找要插入的位置,时间复杂度为O(log2N)。
步骤2:将插入节点的color赋为红色。
步骤3:自下而上重新调整该树为红黑树。
其中,步骤1的查找方法跟普通二叉查找树一样;步骤2之所以将插入节点的颜色赋为红色,是因为若设为黑色,就会因多出一个黑色节点而破坏性质1.4-5,这个是很难调整的。但设为红色节点后,可能会导致出现两个连续红色节点的冲突,那么可以通过简单的颜色调换(color flips)和树旋转来调整。至于进行什么操作取决于其临近节点的颜色。同人类的家族树一样,我们将使用术语叔父节点来指一个节点的父节点的兄弟节点。注意:性质1.4-1和性质1.4-3总是保持着;性质1.4-4只在增加红色节点、重绘黑色节点为红色或做旋转时受到威胁;性质1.4-5只在增加黑色节点、重绘红色节点为黑色或做旋转时受到威胁。
下面讨论步骤3的一些细节。
设要插入的红色节点为N,其父节点为P,P的兄弟节点为U、父亲节点为G(即P和U是G的两个子节点,U是N的叔父节点)。父节点P有两种可能颜色:
如果P是黑色的,则整棵树保持红黑树性质,不必调整。
如果P是红色的(可知,其父节点G一定是黑色的),则插入N后,违背了性质1.4-4,需要进行调整。调整分以下3种情况:
情况1:N的叔叔U是红色的。
如图1.4-14所示,我们将P和U重绘为黑色并重绘节点G为红色(用来保持性质1.4-4)。现在新节点N有了一个黑色的父节点P,因为通过父节点P或叔父节点U的任何路径都必定通过祖父节点G,在这些路径上的黑节点数没有改变。但是,红色的祖父节点G的父节点也有可能是红色的,这就违反了性质1.4-4。为了解决这个问题,我们把G当成是新加入的节点进行各种情况的检查。
情况2:N的叔叔U是黑色的,且N是右孩子。
如图1.4-15所示,我们对P进行一次左旋转调换新节点和其父节点的角色;接着,按情形3处理以前的父节点P,以解决仍然失效的性质1.4-4。
情况3:N的叔叔U是黑色的,且N是左孩子。
如图1.4-16所示,对祖父节点G的一次右旋转;在旋转产生的树中,以前的父节点P现在是新节点N和以前的祖父节点G的父节点,然后交换以前的父节点P和祖父节点G的颜色,使其满足性质1.4-4,同时性质1.4-5也依然满足。
2.删除操作
删除操作也可以概括为以下3个步骤。
步骤1:查找删除位置,时间复杂度为O(log2N)。
步骤2:用被删节点的后继替换该节点(只进行数据替换即可,不必调整指针,后继节点是中序遍历中紧挨着该节点的节点,即右孩子的最左孩子节点)。
步骤3:如果删除节点的替换节点为黑色,则需重新调整该树为红黑树。
其中步骤1的查找方法跟普通二叉查找树一样,步骤2之所以用后继节点替换删除节点,是因为这样可以保证该后继节点之上仍是一个红黑树,而后继节点可能是一个叶节点或者只有右子树的节点。若后继节点只有右子树,则用右儿子替换后继节点即可达到删除的目的。如果需要删除的节点有两个儿子,那么问题可以被转化成删除另一个只有一个儿子的节点的问题(因为对于二叉查找树,我们要么找其左子树中的最大元素,要么找其右子树中的最小元素,并把它的值转移到要删除的节点中。接着,删除被复制出值的那个节点,它必定有少于两个非叶子的儿子。因为只是复制了一个值而不违反任何性质,这样就把问题简化为如何删除最多有一个儿子的节点的问题)。在步骤3中,如果删除节点为红色节点,则它的父亲和孩子全为黑节点,这样直接删除该节点即可,不必进行任何调整。如果删除节点是黑节点,则分四种情况讨论:
设要删除的节点为N,其父节点为P,其兄弟节点为S。由于N是黑色的,则P和S可能是黑色的,也可能是红色的。
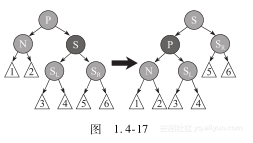
情况1:S是红色的。
此时P肯定是红色的。我们对N的父节点进行左旋转,然后把红色兄弟转换成N的祖父,对调N的父亲和祖父的颜色。完成这两个操作后,尽管所有的路径仍然有相同数目的黑色节点,现在N有了一个黑色兄弟一个红色的父亲(它的新兄弟是黑色的,因为它是红色节点S的一个儿子),所以可以继续按情况2、情况3或情况4处理,使其新兄弟变为黑色,新父亲变为红色(如图1.4-17)。
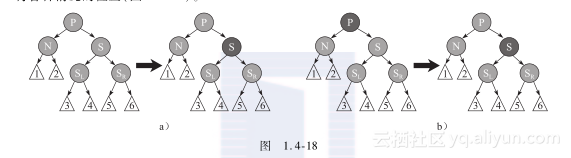
情况2:S和S的孩子全是黑色的。
在这种情况下,P可能是黑色或红色的,我们简单的重绘S为红色。结果是通过S的所有路径为以前不通过N的那些路径,且都少了一个黑色节点。因为删除N的初始的父亲,使通过N的所有路径少了一个黑色节点,这使事情都平衡了起来。但是通过P的所有路径现在比不通过P的路径少了一个黑色节点。所以仍然违反性质1.4-4。要修正这个问题,我们就要将P调整为N,进行各种情况的检查(图1.4-18)。
情况3:S是黑色的,S的左孩子是红色,右孩子是黑色。
这种情况下,我们在S上做右旋转,这样S的左儿子成为S的父亲和N的新兄弟,接着交换S和它新父亲的颜色。所有路径仍有同样数目的黑色节点,但N有了一个右儿子是红色的黑色兄弟,所以进入了情况4。N和它的父亲都不受这个变换的影响(如图1.4-19)。
情况4:S是黑色的,S的右孩子是红色。
在这种情况下,我们在N的父亲上做左旋转,使得S成为P和S的右儿子SR的父亲。接着,交换P和S的颜色,并使SR为黑色(如图1.4-20b))。子树在它的根上仍是相同颜色,所以性质1.4-3没有被违反。但是,N增加了一个黑色祖先:要么N的父亲P变成黑色,要么它是黑色而S被增加一个黑色祖父。所以,通过N的路径都增加了一个黑色节点。此时,如果一条路径不通过N,则有两种可能:
1) 它通过N的新兄弟(如图1.4-20b)中的节点S)。那么它以前和现在都必定通过S和P,而它们只是交换了颜色。所以路径保持了同样数目的黑色节点。
2) 它通过N的新叔父、S的右儿子(如图1.4-20b)中的节点SR),那么它以前通过S、P和SR,但现在仅通过S,它被假定为它以前父亲的颜色,而SR由红色变为黑色。合成效果是这条路径通过了同样数目的黑色节点。
在任何情况下,在这些路径上的黑色节点数目都没有改变,所以恢复了性质1.4-4。在图1.4-20中的白色节点可以是红色或黑色,但是在变换前后的颜色相同。
红黑树之所以能够在O(log2N)时间内做查找、插入和删除,是因为树的高度能保持O(log2N)的渐进边界。下面,我们就来给予证明这个结论:
【定理1.4-2】 包含n个内部节点的红黑树的高度是O(log2N)。
证明:
设以节点v为根的子树的高度为h(v);从v到子树中任何叶子的黑色节点数(亦称黑色高度。若v是黑色,则不计数)为bh(v);
【引理1.4-1】 以节点v为根的子树有至少2bh(v)-1个内部节点。
证明(归纳法):
如果v的高度是零(h(v)=0),则它必定是nil,因此bh(v)=0。所以2bh(v)-1=20-1=0。
归纳假设:h(v)=k的v有2bh(v)-1-1个内部节点暗示了h(v′)=k+1的v′有2bh(v′)-1个内部节点。
因为v′有h(v′)>0,所以它是个内部节点。同样,它有黑色高度要么是bh(v′),要么是bh(v′)-1(依据v′是红色还是黑色)的两个儿子。通过归纳假设每个儿子都有至少2bh(v′)-1-1个内部接点,所以v′有2bh(v′)-1-1+2bh(v′)-1-1+1=2bh(v′)-1个内部节点。
使用引理1.4-1就可以展示出树的高度是对数性的。因为在从根到叶子的任何路径上至少有一半的节点是黑色(根据红黑树性质1.4-4),根的黑色高度至少是h(root)2,即
n≥2h(root)2-1log2(n+1)≥h(root)2h(root)≤2log2(n+1)
由此得证,红黑树根的高度是O(log2N)。
1.4.3 应用改进型的二叉查找树解题
改进型的二叉查找树作为一种时间效率很高、空间要求不大的数据结构,在解题中大有用武之地。下面就通过三个范例说明其应用价值。
【1.4.1 turnover】
【问题描述】
Tiger最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况。
Tiger拿出了公司的账本,账本上记录了公司成立以来每天的营业额。分析营业情况是一项相当复杂的工作。由于节假日、大减价或者是其他情况的时候,营业额会出现一定的波动,当然一定的波动是能够接受的,但是在某些时候营业额突变得很高或是很低,这就证明公司此时的经营状况出现了问题。经济管理学上定义了一种最小波动值来衡量这种情况:
该天的最小波动值=min{该天以前某一天的营业额-该天营业额}
当最小波动值越大时,就说明营业情况越不稳定。
而分析整个公司从成立到现在营业情况是否稳定,只需要把每一天的最小波动值加起来就可以了。你的任务就是编写一个程序帮助Tiger来计算这个值。
第一天的最小波动值为第一天的营业额。
输入:
输入由文件“turnover.in”读入。
第一行为正整数n(n≤32767),表示该公司从成立一直到现在的天数,接下来的n行每行有一个正整数ai(ai≤1000000),表示第i天公司的营业额。
输出:
输出到文件“turnover.out”。
输出文件仅有一个正整数,即∑每一天的最小波动值。结果小于231。
输入输出样例:
结果说明:5+1-5+2-1+5-5+4-5+6-5=5+4+1+0+1+1=12
试题来源:湖南省队2002年选拔赛
在线测试地址:BZOJ 1588 http://www.lydsy.com/JudgeOnline/problem.php?id=1588
试题解析
简述题意:给出一个含n个元素的数列a,对于第i个元素ai定义
fi=min1≤j<i{ai-aj} 其中f1=a1
即每次读入一个数ai,就要在前面输入的数中找到一个与该数相差最小的一个,计算两数间差的绝对值fi。要求统计∑ni=1fi。
我们很容易想到一个时间复杂度为O(n2)的朴素算法:每次读入一个数,再将前面输入的数依次查找一遍,求出与当前数的最小差值,记入总结果T。但由于本题中n很大,这样的算法是不可能在时限内出解的。而如果使用线段树记录已经读入的数,就需要记下一个2M的大数组,空间需求很大。而红黑树与平衡二叉树虽然在时间效率、空间复杂度上都比较优秀,但过高的编程复杂度却让人望而却步。于是我们想到了伸展树算法。
进一步分析本题,解题涉及对于有序集的三种操作:插入、求前驱、求后继。而对于这三种操作,伸展树的时间复杂度都非常优秀,于是我们设计了如下算法。
开始时,树S为空,总和T为零。每次读入一个数p,执行Insert(p,S),将p插入伸展树S。这时,p也被调整到伸展树的根节点。这时,求出p点左子树中的最右点和右子树中的最左点,这两个点分别是有序集中p的前驱和后继。然后求得最小差值,加入最后结果T。
由于对于伸展树的基本操作的平摊复杂度都是O(log2N)的,所以整个算法的时间复杂度是O(n*log2n);而空间上,可以用数组模拟指针存储树状结构,这样所用内存不超过400K;编程复杂度方面,伸展树算法非常简单,程序并不复杂。
程序清单
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
const int MAXN = 32768; // 伸展树的规模上限
struct treetype{// 伸展树的节点类型
int data;// 数据
int fa,l,r;// 父指针和左右指针
};
treetype t[MAXN];// 伸展树
int m, root;// 伸展树的根为root,节点数为m
int n, k, ans;// 天数为n,n天最小波动值的总和为ans
void Init()// 初始化
{
cin >> n;// 读天数
m = 0;memset(t, 0, sizeof(t));// 伸展树为空
ans=0;// n天最小波动值的总和初始化
}
void LeftRotate(int x)// 以x节点为基准左旋
{
int y;
y=t[x].fa;t[y].r=t[x].l;// x的左儿子变成其父节点的右儿子
if (t[x].l!=0) t[t[x].l].fa=y;
t[x].fa=t[y].fa;t[x].l=y;// x的祖父成为x的父节点,x的原父节点成为x的左儿子
if (t[y].fa != 0)// 在x存在祖父节点的情况下,若x的原父节点是祖父节点的左
// 儿子,则祖父节点的左儿子改为x;否则祖父节点的右儿子改为x
{
if (y == t[t[y].fa].l)t[t[y].fa].l=x;
else t[t[y].fa].r=x;
}
t[y].fa=x;// x上移至原来的祖父位置
}
void RightRotate(int x)// 以x节点为基准右旋
{
int y;
y=t[x].fa;t[y].l=t[x].r;// x的右儿子变成其父节点的左儿子
if (t[x].r != 0) t[t[x].r].fa=y;
t[x].fa=t[y].fa;t[x].r=y;// x的祖父成为x的父节点,x的原父节点成为x的右儿子
if (t[y].fa != 0)// 在x存在祖父节点的情况下,若x的原父节点是祖父节点的左
// 儿子,则祖父节点的左儿子改为x;否则祖父节点的右儿子改为x
{
if (y==t[t[y].fa].l)t[t[y].fa].l=x;
else t[t[y].fa].r=x;
}
t[y].fa=x;// x上移至原祖父位置
}
void splay(int x)// 伸展操作:通过一系列的旋转操作,将x节点调整至根部
{
int l;
while (t[x].fa != 0)// 反复进行旋转操作,直至将x节点调整至根部为止
{
l=t[x].fa;// 取出x的父节点
if(t[l].fa==0)// 在x的父节点为根的情况下,若x在左儿子位置,则右旋;否则左旋
{
if (x == t[l].l) RightRotate(x); else LeftRotate(x);
break;// 退出循环
}
if (x == t[l].l)// 在x位于左位置的情况下,若x的父节点位于左位置,则分别
// 以x的父节点和x为基准两次右旋;否则以x为基准右旋和左旋
{
if (l == t[t[l].fa].l)
{
RightRotate(l);RightRotate(x);
}
else
{
RightRotate(x);LeftRotate(x);
}
}
else// 在x位于右位置的情况下,若x的父节点位于右位置,则分别
// 以x的父节点和x为基准两次左旋;否则以x为基准左旋和右旋
{
if (l == t[t[l].fa].r)
{
LeftRotate(l);LeftRotate(x);
}
else
{
LeftRotate(x);RightRotate(x);
}
}
}
root=x;// x为伸展树的根
}
void Insert(int x)// 将x插入伸展树
{
int l, f;
t[++m].data=x;t[m].fa=0;t[m].l=0;t[m].r=0;
// 新增一个值为x的节点
if (root == 0){ root=m; return;}// 若原伸展树为空,则返回该节点
l=root;// 从伸展树的树根出发,寻找x的插入位置m
do{
f=l;
if (x <= t[l].data) l=t[l].l; else l=t[l].r;
}while (l != 0);
t[m].fa=f;
if (x <= t[f].data) t[f].l=m; else t[f].r=m;
splay(m);// 以m为基准,进行伸展操作
}
void Cal()// 累计当天的最小波动值
{
int l, min;
min=0x7FFFFFFF;// 当天的最小波动值初始化
l=t[root].l;// 从根的左儿子出发,寻找左子树中的最右点(有序集中当天
// 营业额的前驱)
while (l != 0) { if (t[l].r==0) break;l=t[l].r;}
if (l!=0)min=t[root].data-t[l].data;
// 计算当天的波动值
l=t[root].r;// 从根的右儿子出发,寻找右子树中的最左点,即有序集中当天
// 营业额的后继
while(l!= 0){ if(t[l].l==0)break;l=t[l].l;}
// 调整当天的最小波动值
if ((l!=0)&&(t[l].data-t[root].data<min))
min=t[l].data-t[root].data;
ans += min;// 累计最小波动值的总和
}
void Make()
{
int i, k;
for (i=1; i <= n; ++i)
{
cin >> k;
Insert(k);// 读第i天的营业额并插入伸展树
if (m>=2)Cal(); else ans+=k;// 若伸展树的节点数不少于2,则通过伸展树计算最小波动值的
// 总和;否则第i天的营业额计入最小波动值的总和
}
cout << ans << endl;// 输出n天最小波动值的总和
}
int main()
{
Init();// 初始化
Make();// 输入n天的营业额,计算和输出最小波动值的总和
return 0;
}
【1.4.2 Jewel Magic】
【问题描述】
我是一个魔术师。我有一串绿宝石和珍珠。我可以在串中插入新的珠宝,或删除旧的珠宝。我甚至可以翻转串的一个连续的部分。在任何时候,如果您指点两个珠宝并问我,从这两个珠宝开始,珠宝串的最长公共前缀(the Longest Common Prefix,LCP)的长度是多少,我可以马上回答您的问题。您能比我做得更好吗?
在形式上,本题给出一个由0和1组成的字符串。您要进行四种操作(如下所述,L表示字符串的长度,珠宝的当前位置从左到右由1到L编号),如表1.4-1所示。

输入:
输入包含若干测试用例。每个测试用例的第一行给出整数n和m(1≤n,m≤200000),其中n是初始时珠宝的数目,m是操作的数目。接下来的一行给出长度为n的01字符串。然后的m行每行给出一个操作。输入以EOF结束。输入文件大小不超过5MB。
输出:
对于每个类型的操作,输出答案。
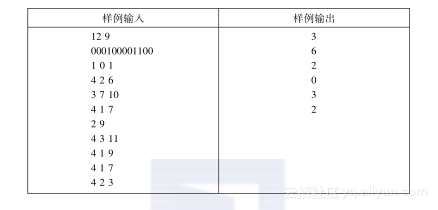
说明:
1) 在操作1 0 1之后的字符串:1000100001100。
2) 在操作3 7 10之后的字符串:1000101000100。
3) 在操作2 9之后的字符串:100010100100。
试题来源:Rujia Lius Present 3:A Data Structure Contest Celebrating the 100th Anniversary of Tsinghua University
在线测试地址:UVA 11996
试题解析
简述题意:给出一个初始长度为n的01串,进行四种操作:
1) 在位置x插入y。
2) 删除位置x的内容。
3) 翻转区间[L,R]的内容。
4) 输出从x开始和从y开始的串的最长公共前缀。
如果以珠宝位置为关键字的话,则一个珠宝串可用一棵伸展树表述,树中的节点序号为珠宝位置i(i=左子树的节点数+1),以其为根的子树代表一个连续的珠宝子串[l,r](l≤i≤r),左子树对应珠宝i左方的连续子串[l,i-1],右子树对应珠宝i右方的连续子串[i+1,r],为了能够准确地找出任意两个珠宝位置开始的最长公共前缀,用一个11进制整数si表征珠宝子串[l,r]的状态。
si=左子树的珠宝状态值*11右子树的节点数+1+i位置的珠宝状态*11右子树的节点数+右子树的珠宝状态值
若珠宝子串[l,r]反转的话,相当于左右子树交换,反转后[l,r]的状态值。
s′i=右子树的珠宝状态值*11左子树的节点数+1+i位置的珠宝状态*11左子树的节点数+左子树的珠宝状态值
显然,插入、删除和反转都需要通过伸展操作(splay)维护伸展树。关键是如何查找首指针分别为x和y的两个子串的最长公共前缀(即LCP长度)。设LCP的长度区间[l,r],初始时为[0,min{串长-x+1,串长-y+1}]。
显然,若x==y,则LCP长度为r-1;若伸展树中节点x的位码≠节点y的位码,则LCP长度为0。
否则采用二分查找的方法计算LCP长度:
while (l+1<r) // 二分搜索LCP长度
{
mid=(l+r)/2;// 计算中间指针
if ([x,x+mid-1]的状态值==[y,y+mid-1]的状态值)l= mid;
// 查找右子区间
else r= mid;// 查找左子区间
}
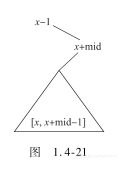
得出LCP长度为l。
对于查询从x开始长度为mid的串的状态值,只要将x-1和x+mid分别调整到根和根的右子树,则根的右子树的左子树就是串[x,x+mid-1],由此得到其状态值(如图1.4-21)。
用类似方法可查询[y,y+mid-1]的状态值。
程序清单
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn = 400010;
typedef unsigned long long uLL;
int base=11;
uLL weight[maxn];
void getweight() // 计算各个数位的权值,其中第i位的权值weight[i]=11i
{
weight[0] = 1;
for (int i=1; i<maxn; i++)weight[i]=weight[i-1]*base;
}
struct treenode// 节点的结构定义
{
treenode *leftc,*rightc,*pre;// 左右子树指针*leftc、*rightc和父指针*pre
int size, val;// size为子树的节点总数,val当前位的值
uLL data, revdata;// data为关键字,revdata为反转后的关键字(关键字为代表
// 子串的十进制数)
bool rev;// rev为翻转标记
treenode(treenode* _pre = NULL, int _val = 0):
// 构造一个空节点
leftc(NULL), rightc(NULL), pre(_pre), size(1), val(_val), data(_val), revdata(_val), rev(false)
int getsize();// 返回子树大小
int getdata();// 取得节点的状态值
int getrevdata();// 取得反转后节点的状态值
int getkey();// 取得节点的序号
void pushdown();// 向下传递懒惰标记
void update();// 更新节点,子树改变后使用
void zig();// 右旋操作
void zag();// 左旋操作
};
inline int treenode::getsize()// 返回子树大小
{ return this? size : 0;}
inline int treenode::getdata()// 返回节点的状态值
{
if (this) return rev ? revdata : data;
else return 0;
}
inline int treenode::getrevdata()// 返回节点反转后的状态值
{
if (this) return rev ? data : revdata;
else return 0;
}
inline int treenode::getkey() {return leftc->getsize()+1;}
// 取得节点序号
void treenode::pushdown()// 向下传递懒惰标记
{
if(rev)// 若反转,则反转前后的关键字交换,左右子树交换,左右
// 子树的反转标志取反
{
swap(data, revdata);
swap(leftc, rightc);
if (leftc) leftc->rev = !leftc->rev;
if (rightc) rightc->rev = !rightc->rev;
rev = false;
}
}
void treenode::update()// 更新节点的域值
{
size=leftc->getsize()+rightc->getsize()+1;
data=leftc->getdata()*weight[rightc->getsize()+1]+val*weight[rightc->getsize()]
+rightc->getdata();
revdata=rightc->getrevdata()*weight[leftc->getsize()+1]+ val*weight[leftc->
getsize()]+leftc->getrevdata();
}
void treenode::zig()// 右旋操作
{
pre->leftc = rightc;
if (rightc) rightc->pre = pre;
rightc = pre;
pre = rightc->pre;
rightc->pre = this;
if (pre)
if (pre->leftc == rightc) pre->leftc = this;
else pre->rightc = this;
rightc->update(); update();
}
void treenode::zag()// 左旋操作
{
pre->rightc = leftc;
if (leftc) leftc->pre = pre;
leftc = pre;
pre = leftc->pre;
leftc->pre = this;
if (pre)
if (pre->leftc == leftc) pre->leftc = this;
else pre->rightc = this;
leftc->update(); update();
}
Treenode *splay(treenode *&root,treenode *x)// 伸展操作:通过一系列旋转,将以root为根的伸展树中的
// x节点调整至树的根部
{
treenode *p, *g;
while (x->pre)
{
p = x->pre; g = p->pre;
if (g == NULL)
if (x == p->leftc) x->zig();
else x->zag();
else
if (p == g->leftc)
if (x == p->leftc) p->zig(), x->zig();
else x->zag(), x->zig();
else
if (x == p->rightc) p->zag(), x->zag();
else x->zig(), x->zag();
}
return root = x;
}
Treenode *searchkey(treenode *&root, int key)// 从伸展树(root为根)表示的有序集中寻找值为key的
// 节点,通过伸展操作将该节点调整至树的根部
{
treenode *p = root;
while (p->pushdown(), p->getkey()!= key)
{
if (key < p->getkey()) p = p->leftc;
else key -= p->getkey(), p = p->rightc;
}
return splay(root, p);
}
Treenode *insertval(treenode *&root,int pos,int val)
// 将位置为pos的珠宝val插入到伸展树(以root为根)的相应位置,并通过伸展操作将该节点调整至树的根部
{
treenode *p = root, *ret;
bool found = false;
while (!found)
{
p->pushdown();
if (pos < p->getkey())
if (p->leftc) p = p->leftc;
else ret = p->leftc = new treenode(p, val), found = true;
else
if (p->rightc) pos -= p->getkey(), p = p->rightc;
else ret = p->rightc = new treenode(p, val), found = true;
}
for (; p; p=p->pre) p->update();
return splay(root, ret);
}
void deletekey(treenode*& root, int key)// 从伸展树(root为根)表示的有序集中删除值为key的节
// 点。如果该节点没有孩子或只有一个孩子,则直接删除该节点,并通过伸展操作将其父调整至树的根部;否则该
// 节点被后继所替代,并通过伸展操作将替代节点调整至至树的根部
{
treenode *p = searchkey(root, key);
treenode *lc = p->leftc, *rc = p->rightc;
lc->pre = rc->pre = NULL;
delete p;
searchkey(rc, 1)->leftc = lc; lc->pre = rc;
rc->update();
root = rc;
}
void reverse(treenode*& root, int left, int right)
// 在以root为根的伸展树中反转子串区间[left, right]
{
searchkey(root, left-1)->rightc->pre = NULL;
searchkey(root->rightc, right-left+2)->pre = root;
root->rightc->leftc->rev = !root->rightc->leftc->rev;
root->rightc->update(); root->update();
}
uLL querysegment(treenode *&root, int left, int right)
// 在root为根的伸展树中计算珠宝子串[left,right]对应的状态值
{
searchkey(root, left-1)->rightc->pre = NULL;
searchkey(root->rightc, right-left+2)->pre = root;
return root->rightc->leftc->getdata();
}
treenode *root;
int m, nowlen;
void insertunit(int pos, int x)// 将珠宝x插入pos位置
{
insertval(root, pos+1, x+1);
nowlen++;
}
void deleteunit(int pos)// 删除pos位置的珠宝
{
deletekey(root, pos+1);
nowlen--;
}
void reversesegment(int left, int right)// 反转珠宝子串[left,right]
{
reverse(root, left+1, right+1);
}
int queryLCP(int x, int y)// 计算从位置x和位置y开始的珠宝串的LCP长度
{
int left=0,right=min(nowlen-x+1,nowlen-y+1),mid;
// LCP的长度区间[left,right]初始化,区间的中间指针为mid
if (x == y) return right-1;// 若两串开始位置相同,则LCP长度为区间长度
else// 两串首数字不同,则LCP长度为0
if (searchkey(root, x+1)->val != searchkey(root, y+1)->val)return 0;
while (left+1 < right)// 二分搜索LCP长度
{
mid = (left + right)/2;// 计算中间指针
if(querysegment(root,x+1,x+mid)==querysegment(root,y+1,y+mid))
left = mid;
else right = mid;
}
return left;
}
bool init()// 输入信息,构造初始时的伸展树
{
static char dat[maxn];
int n;
if (scanf("%d%d", &n, &m)==EOF) return false;
// 输入初始珠宝数和操作次数
scanf("%s", dat);// 输入01串(0表示绿宝石,1表示珍珠)
root = new treenode;// 构造伸展树
for (int i=0; i<n; i++) insertval(root, i+1, dat[i]-47);
insertval(root, n+1, 3);
insertval(root, n+2, 0);
nowlen = n+1;
}
void work()
{
int t, x, y;
for (int i=0; i<m; i++)// 处理m个操作
{
scanf("%d", &t);// 输入第i个操作的命令字
if (t == 1)// 若插入操作
{
scanf("%d%d", &x, &y);// 读插入位置x和珠宝类型y
insertunit(x, y);// 将珠宝y插入x位置并维护伸展树
}
else if (t == 2)// 若删除操作
{
scanf("%d", &x);// 读被删位置
deleteunit(x);// 删除x位置的珠宝并维护伸展树
}
else if (t == 3)// 若反转操作
{
scanf("%d%d", &x, &y);// 读被反转的区间
reversesegment(x, y);// 将反转[x,y]区间内的珠宝并维护伸展树
}
Else// 输出操作
{
scanf("%d%d", &x, &y);// 读两串的开始位置
printf("%d\n",queryLCP(x,y));// 计算和输出从位置x和位置y开始的两串珠宝的LCP长度
}
}
}
int main()
{
getweight();// 计算各个数位的权重
while (init()) work();// 反复处理测试用例
return 0;
}当然,伸展树算法并不是[1.4.1 turnover]和[1.4.2 Jewel Magic]的唯一算法,但它与其他常用的数据结构相比,还是有许多优势的。下面表1.4-2比较了四种算法(顺序查找、线段树、AVL树和伸展树)的时空复杂度和编程复杂度,从中可以看出伸展树的优越性。
由上面的分析介绍,我们可以发现伸展树有以下几个优点。
1) 时间复杂度低。伸展树的各种基本操作的平摊复杂度都是O(log2n)的。在树状的数据结构中,无疑是非常优秀的。
2) 空间要求不高。与红黑树需要记录每个节点的颜色、AVL树需要记录平衡因子不同,伸展树不需要记录任何信息以保持树的平衡。
3) 算法简单。编程容易,调试方便。伸展树的基本操作都是以Splay操作为基础的,而Splay操作中只需根据当前节点的位置进行旋转操作即可。
虽然伸展树算法与AVL树在时间复杂度上相差不多,甚至有时候会比AVL树稍慢一些,但伸展树的编程复杂度大大低于AVL树。竞赛中使用伸展树,在编程和调试等方面都更有优势。
【1.4.3 Black Box】
【问题描述】
我们的黑匣子(black box)表示一个原始的数据库。它可以保存一个整数数组,并有一个特殊的i变量。初始时,黑匣子为空,i等于0。黑匣子处理一个命令序列(事务)。它有两类事务:
ADD(x):将元素x加入到黑匣子中。
GET:i增加1,并在黑匣子中给出所有整数中第i小的整数。在黑匣子中元素按非降序排列后,第i小的整数排在第i个位置上。
下例给出一个11个事务的序列,如表1.4-3所示。
请你完成一个处理一个给出的事务序列的有效算法。ADD和GET事务的最大数目:每种类型30000。
本题用两个整数数组描述事务的序列:
1) A(1),A(2),…,A(M):表示在黑匣子中的元素序列。A的值是绝对值不超过2000000000的整数,M≤30000。上面的例子中,A=(3,1,-4,2,8,-1000,2)。
2) u(1),u(2),…,u(N):在执行第一个,第二个,……,第N个GET事务时,黑匣子中序列元素的个数。上面的例子中,u=(1,2,6,6)。
黑匣子假设自然数序列u(1),u(2),……,u(N)按非降序排列,N≤M,并且对每个p(1≤p≤N)不等式p≤u(p)≤M成立。对于u序列的第p个元素,执行GET事务从A(1),A(2),…,A(u(p))序列中给出第p小的整数。
输入:
输入(以给出的次序)包含:M,N,A(1),A(2),…,A(M),u(1),u(2),…,u(N)。所有的数字以空格和回车符分隔。
输出:
对于给出的事务序列,输出黑匣子的结果,每个数字一行。

试题来源:ACM Northeastern Europe 1996
在线测试地址:POJ 1442,ZOJ 1319,UVA 501
试题解析
简述题意:给出两种操作:ADD(x),将x添加到有序列表中;GET(up[p])返回有序列表的前up[p]个元素中第p小的元素值。其中迭代器p在GET操作后会自动加1。
方法1:使用大根堆H≥和小根堆H≤。
我们使用两个堆使执行ADD和GET操作:如图1.4-22所示。那样根对根地放置。在大根堆H≥中,根节点值H≥[1]最大;在小根堆H≤中,根节点值H≤[1]最小。
在执行黑匣子操作时,我们时刻维护以下条件:
条件(1):H≥[1]≤H≤[1]。
条件(2):大根堆H≥的规模=i。
执行ADD(x)命令时,比较x与H≥[1]:若x≥H≥[1],则将x插入H≤,否则从H≥中取出H≥[1]插入H≤,再将x插入H≥。
执行GET命令时,H≤[1]就是待获取的对象。输出H≤[1],同时从H≤中取出H≤[1]插入H≤,以维护条件(2)。
上述算法的时间复杂度为O(Mlg2M+Nlg2N),算法较简洁。
方法2:使用红黑树。
由于u(1),u(2),…,u(N)是递增排序的,我们将u[]分成N个子区间:
[1,u[1]],[u[1]+1,u[2]],…,[u[N-1]+1,u[N]]
依次处理u[i](1≤i≤N):
将A序列中第i个子区间的元素A[u[i-1]+1]..A[u[i]]插入红黑树,然后计算和输出红黑树中第i小的元素。
显然,算法的时间复杂度为O(Nlg2M),效率提高了不少。
程序清单
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int m,n;// A序列的长度和u序列的长度
int a[60000];// A序列
enum COLOR// 颜色的定义
{
red,black
};
struct RedBlack// 红黑树节点的结构定义
{
COLOR color;// 颜色
int l;int r;int p;// 左右指针和父指针
int key;// 数值
int cnt;// 子树规模
};
RedBlack tree[60000];// 存储红黑树
int lt;// 待插入节点的序号
int root;// 红黑树的根
void RB_Init()// 红黑树初始化
{
tree[0].color=black;// 虚拟根的父节点0
tree[0].key=-1;
root=1;// 确定根节点的域值
tree[1].l=0;tree[1].r=0;tree[1].p=0;tree[1].cnt=0;tree[1].key=-1;
}
void RB_KeyC_Fixup(int x)// 计算以x为根的子树规模
{
tree[x].cnt=tree[tree[x].l].cnt+tree[tree[x].r].cnt+1;
}
void RB_Left_Rotate(int x)// 以x节点为基准左旋
{
int y;
y=tree[x].r; tree[x].r=tree[y].l;// 取x的右儿子y,y的左儿子作为x的右儿子
if(tree[y].l!= 0){tree[tree[y].l].p=x; }// 若y存在左儿子,则x作为y左儿子的父亲,x的父亲作为
// y的父亲
tree[y].p=tree[x].p;
if (tree[x].p==0){ root=y;}// 若x为根,则根调整为y;在x非根情况下,若x为其父的左
// 儿子,则其父的左儿子调整为y;否则其父的右儿子调整为y
else if(tree[x].p!=0 && x== tree[tree[x].p].l){tree[tree[x].p].l=y; }
else if(tree[x].p!=0&&x!= tree[tree[x].p].l){tree[tree[x].p].r=y ;}
tree[y].l=x;tree[x].p=y;// y的左儿子调整为x,x的父亲调整为y
RB_KeyC_Fixup(x);RB_KeyC_Fixup(y);// 分别计算以x和y为根的两棵子树规模
}
void RB_Right_Rotate(int y)// 以x节点为基准右旋
{
int x;
x=tree[y].l;tree[y].l=tree[x].r;// y的左儿子记为x,x的右儿子记为y的左儿子
if(tree[x].r!=0){ tree[tree[x].r].p=y;}// 若x存在右儿子,则其父记为y
tree[x].p=tree[y].p;// y的父亲记为x的父亲
// 若x右旋至根位置,则设定x为根;否则若y是其父的左儿子,则y的父亲的左儿子调整为x;若y非其父的左儿
// 子,则y的父亲的右儿子调整为x
if (tree[y].p == 0){root=x; }
else if(tree[y].p!=0 &&y==tree[tree[y].p].l){tree[tree[y].p].l=x;}
else if(tree[y].p!=0&& y!=tree[tree[y].p].l){tree[tree[y].p].r=x;}
tree[x].r=y;tree[y].p=x;// x的右儿子调整为x,y的父亲调整为x
RB_KeyC_Fixup(y);RB_KeyC_Fixup(x);// 分别计算以x和y为根的两棵子树规模
}
void RB_Insert_Fixup(int z)// 在红黑树中插入节点z后的维护
{
int y;
while (tree[tree[z].p].color==red)// 若z的父节点为红色
{
if(tree[z].p==tree[tree[tree[z].p].p].l)
// 若z的父节点为祖父的左儿子
{
y=tree[tree[tree[z].p].p].r;// 取z的祖父的右儿子y
if (tree[y].color == red)// 若y为红色节点,则z的父节点和y节点的颜色调整为黑,
// z的祖父的颜色调整为红,z指针指向其祖父
{
tree[tree[z].p].color=black; tree[y].color=black;
tree[tree[tree[z].p].p].color=red;
z=tree[tree[z].p].p;
}
else// 在y非红色节点情况下,若z为其父的右儿子,则z指向其
// 父,左旋z;若z为其父的左儿子,则z的父亲颜色调整为黑,祖父颜色调整为红,右旋其祖父
if (tree[y].color != red && z == tree[tree[z].p].r)
{z=tree[z].p; RB_Left_Rotate(z); }
else if (tree[y].color != red && z == tree[tree[z].p].l)
{
tree[tree[z].p].color=black;
tree[tree[tree[z].p].p].color=red;
RB_Right_Rotate(tree[tree[z].p].p);
}
}
else// 在z的父节点为祖父右儿子的情况下,取祖父的左儿子y
{
y=tree[tree[tree[z].p].p].l;
if (tree[y].color == red)// 若y为红色节点,则z的父亲颜色和y的颜色调整为黑,
// z的祖父颜色调整为红,z指向其祖父
{
tree[tree[z].p].color=black;
tree[y].color=black;
tree[tree[tree[z].p].p].color=red;
z=tree[tree[z].p].p;
}
else// 在y非红色节点情况下,若z是其父的左儿子,则z指向其
// 父亲,右旋z;若z是其父的右儿子,则其父颜色调整为黑,祖父颜色调整为红,左旋其祖父
if (tree[y].color != red && z == tree[tree[z].p].l)
{ z=tree[z].p; RB_Right_Rotate(z); }
else if(tree[y].color != red && z == tree[tree[z].p].r)
{
tree[tree[z].p].color=black;
tree[tree[tree[z].p].p].color=red;
RB_Left_Rotate(tree[tree[z].p].p);
}
}
}
tree[root].color=black;// 根节点颜色调整为黑
}
void RB_Insert(int n)// 在红黑树中插入数值为n的节点
{
int x,y;
y=0;
x=root;// 从根开始寻找插入的叶节点位置x(父节点为y)
while (tree[x].key != -1)
{
y=x;
tree[x].cnt++;
if(n<tree[x].key){ x=tree[x].l; }
else{ x=tree[x].r; }
}
tree[lt].p=y;// y为节点lt的父指针
if (y== 0){root=lt;}
else if(y!=0&&n<tree[y].key){tree[y].l=lt;}
// 确定lt在y的子树方向
else if (y != 0 && n >= tree[y].key){ tree[y].r=lt;}
tree[lt].l=0;tree[lt].r=0;// 设定节点lt的域值
tree[lt].color=red;tree[lt].key=n; tree[lt].cnt=1;
RB_Insert_Fixup(lt);// 节点it插入红黑树后的维护
lt++;// 计算待插入节点的序号
}
int RB_Query(int k)// 返回红黑树中第k大的数
{
int x,y;
x=root;// 从树根开始自上而下寻找
while (k != 1 || tree[x].cnt != 1)
{
if (k <= tree[tree[x].l].cnt && tree[x].l != 0)
{// 若左子树的节点数不小于k,则沿左子树方向寻找
x=tree[x].l;
}
else if(k==tree[tree[x].l].cnt+1)// 若x正好为第k大的数,则返回
{
return tree[x].key;
}
else if(k>tree[tree[x].l].cnt+1)// 若第k大的数在右子树方向,则在右子树中寻找第(k-
// 左子树规模-1)大的数
{
k-=tree[tree[x].l].cnt+1; x=tree[x].r;
}
}
return tree[x].key;// 返回红黑树中第k大的数
}
int main()
{
int i,j,pr,t,p;
scanf("%d%d",&m,&n);// 输入黑匣子中的元素数
for (i=1; i<=m; i++)// 输入黑匣子中的元素序列
{
scanf("%d",a+i);
}
pr=1;// 插入区间的左指针初始化
p=1;// GET事务序号初始化
lt=1;// 待插入节点序号初始化
RB_Init();// 红黑树初始化
while (n--)// 依次进行n个GET事务
{
scanf("%d",&t);// 输入u[p]的值t
for (i=pr; i<=t; i++)// 将a[pr]..a[t]插入红黑树
{
RB_Insert(a[i]);
}
pr=t+1;// 调整区间首指针
printf("%d\n",RB_Query(p));// 输出a[1],…,a[t]第p小的整数
p++;// 迭代器p自动+1
}
}由上可见,红黑树与伸展树、AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉树查找树的平衡,从而获得较高的检索性能。区别在于:伸展树、AVL树所追求的是全局均衡,插入、删除操作需调整整棵树,颇为费时;而红黑树使用颜色来标识节点高度,所追求的是局部平衡而不是非常严格的平衡。插入、删除数据时最多旋转3次,尤其是对随机无序数据,由于平衡要求没那么严格,旋转次数较少,因而提升了增删操作的效率。
但不足的是,由于红黑树须存储颜色类型,因此存储空间要比伸展树略大一些,且编程复杂度和思维复杂度要高出许多。因此对这几种改进型二叉查找树的选择权衡,需要遵循“边分析,边选择,兼顾四个标准(时间复杂度、空间复杂度、编程复杂度和思维复杂度)”的原则。