丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
未来已至!可穿戴设备将如何改变我们的生活?
数据清洗那些坑,程序员如何“踩雷避坑”?
钉钉 + AI 网关给 DeepSeek 办入职
【04】优雅草星云物联网AI智控系统从0开发鸿蒙端适配-deveco studio-自定义一个设置输入小部件组件-完成所有设置setting相关的页面-优雅草卓伊凡
「通义灵码+X」公开课开讲啦!和赛博同桌一起完成开发任务 有奖励
云原生 Kafka 问卷调研启动,你的声音很重要!参与赢精美礼品!
【03】优雅草星云物联网AI智控系统从0开发鸿蒙端适配-deveco studio-在lib目录新建自定义库UtilsLibrary,ComponentLibrary,CommonConstLibrary完成设置SettingsView.ets初始公共类书写-优雅草卓伊凡
使用 Ollama 本地模型与 Spring AI Alibaba 的强强结合,打造下一代 RAG 应用
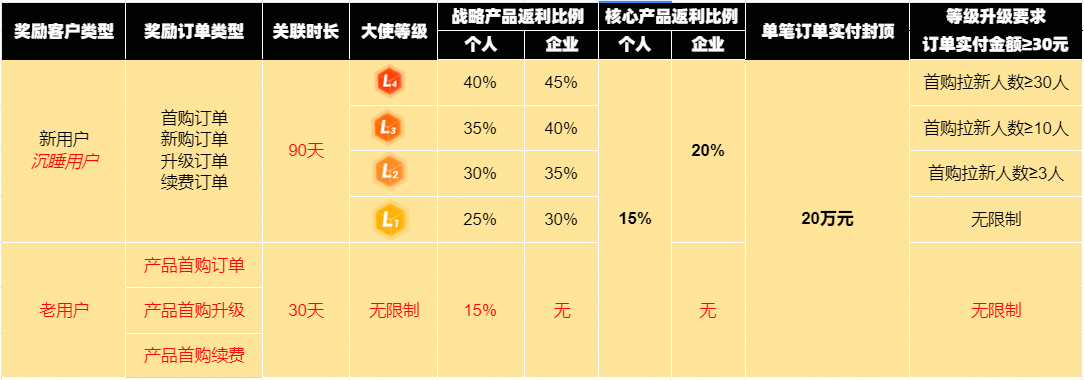
2025年 | 4月云大使推广奖励规则
【02】优雅草星云物联网AI智控系统从0开发鸿蒙端适配-deveco studio-登录页面LoginView.ets完成-并且详细解释关于arkui关于 CommonConst, commonColor, InputDataModel-优雅草卓伊凡
智能运维,由你定义:SAE自定义日志与监控解决方案
【01】优雅草星云物联网AI智控系统从0开发鸿蒙端适配完成流程-初始化鸿蒙编译器deveco studio项目结构-UI设计图切片下载-优雅草卓伊凡
Flutter敏感词过滤实战:基于AC自动机的高效解决方案
ArkTs的@Watch状态监听
智能数据建设与治理 Dataphin深度评测
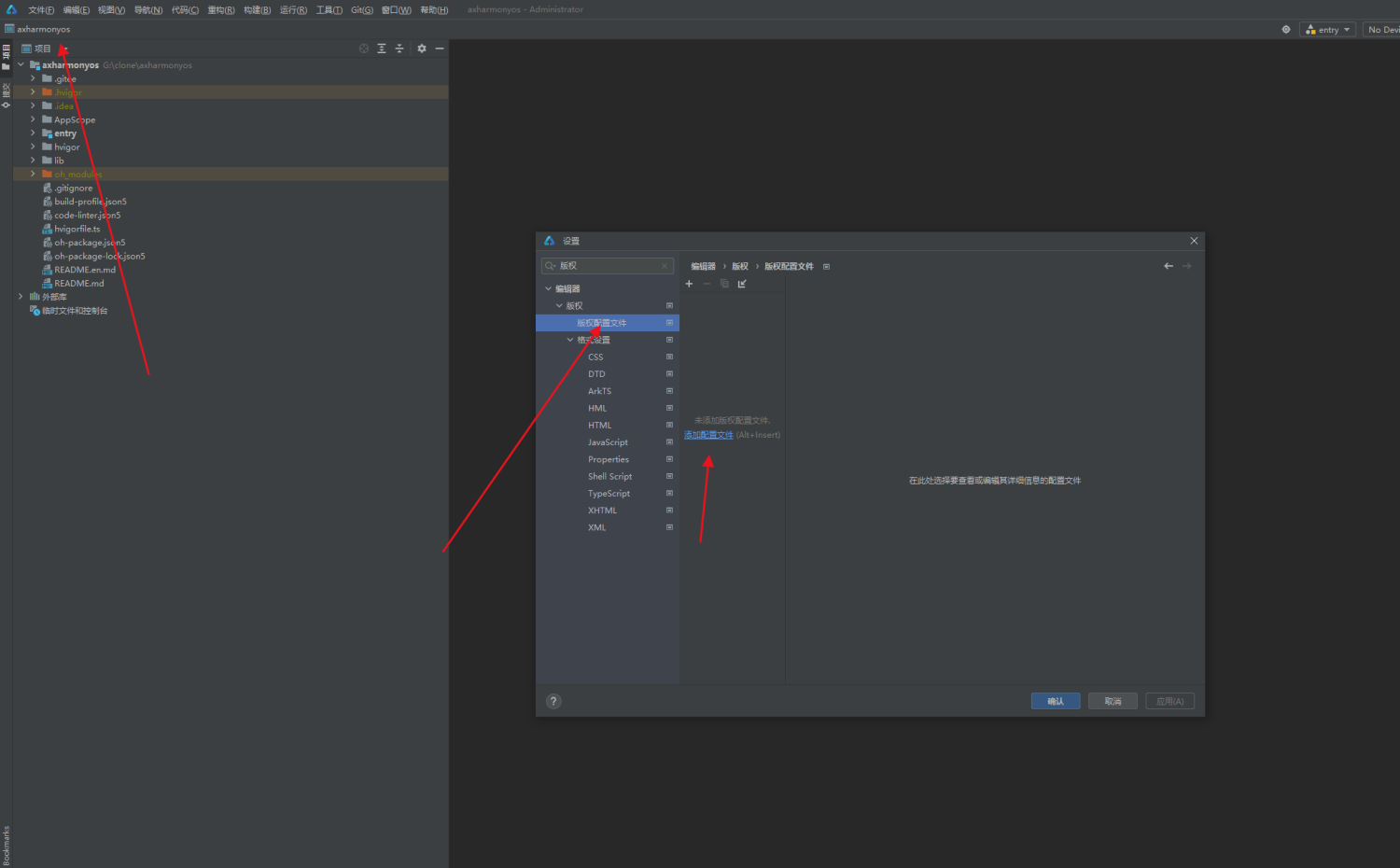
华为鸿蒙编译器deveco studio 开发项目如何插入自己的版权代码-单文件添加和设置全局模板-优雅草卓伊凡
harmonyOS基础- 快速弄懂HarmonyOS ArkTs基础组件、布局容器(前端视角篇)
深度评测——大模型时代的智能BI—Quick BI
【LeetCode 热题100】208:实现 Trie (前缀树)(详细解析)(Go语言版)
什么是请求资源(Request Resource)?
云产品评测|安全体检
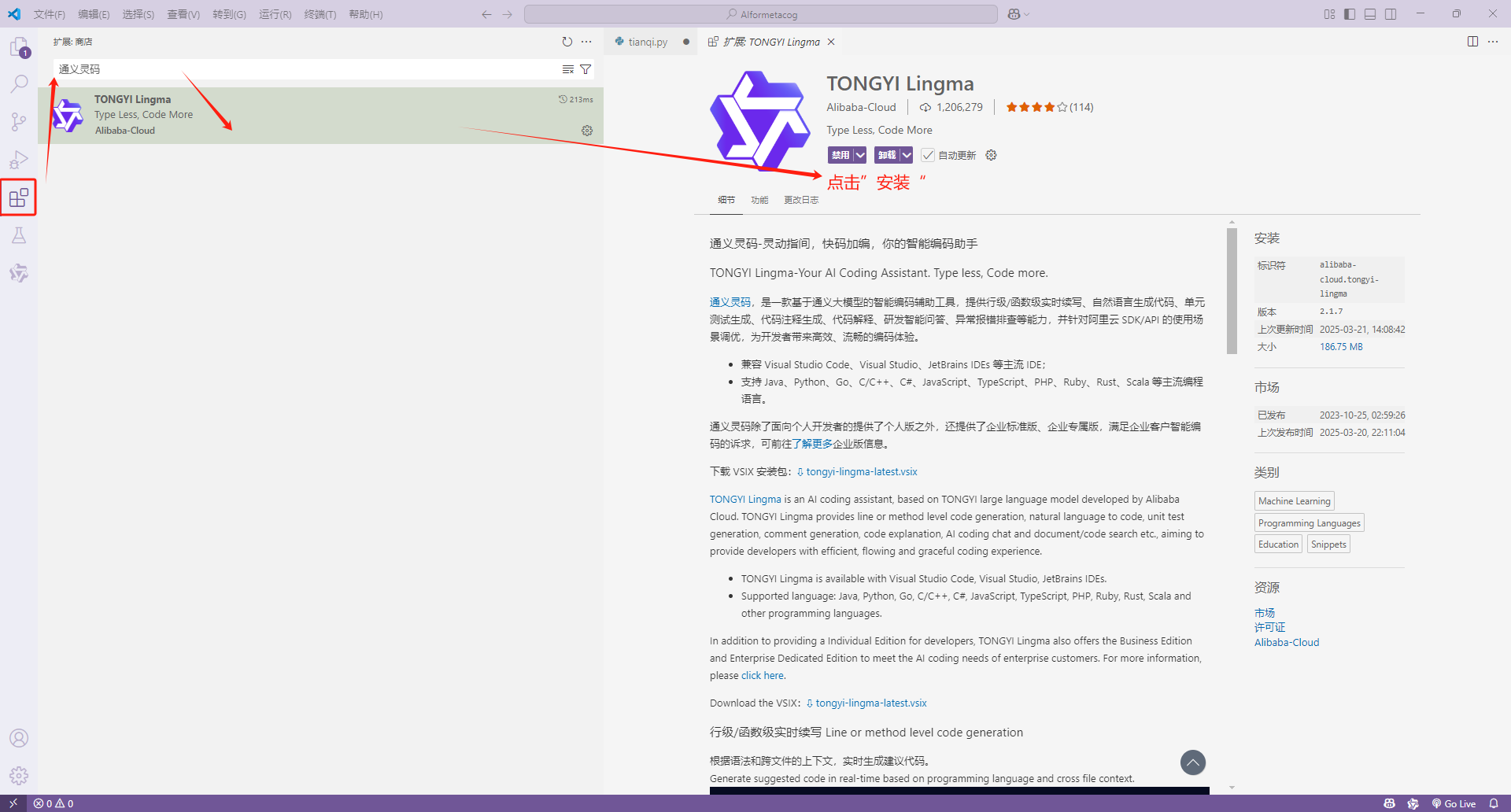
用户说:10分钟用通义灵码搞定“今天穿什么”!打开爽文世界……
VB6网络通信软件上位机开发,TCP网络通信,读写数据并处理,完整源码下载
harmonyOS基础-认识UIAbility
HarmonyOS NEXT - RelationalStore关系型数据库
如何在 10 分钟内将 DeepSeek API 集成到您的应用程序
HarmonyOS NEXT - Preferences用户首选项
HarmonyOS NEXT - @Provide和@Consume
WebSocket调试神器对决:Apipost凭何碾压Apifox?
HarmonyOS NEXT - @Prop和@Link
RoboBrain:智源开源具身大脑模型,32B参数实现跨机器人协作
Math24o:SuperCLUE开源的高中奥数推理测评基准,85.71分屠榜
EmotiVoice:网易开源AI语音合成黑科技,2000+音色情感可控
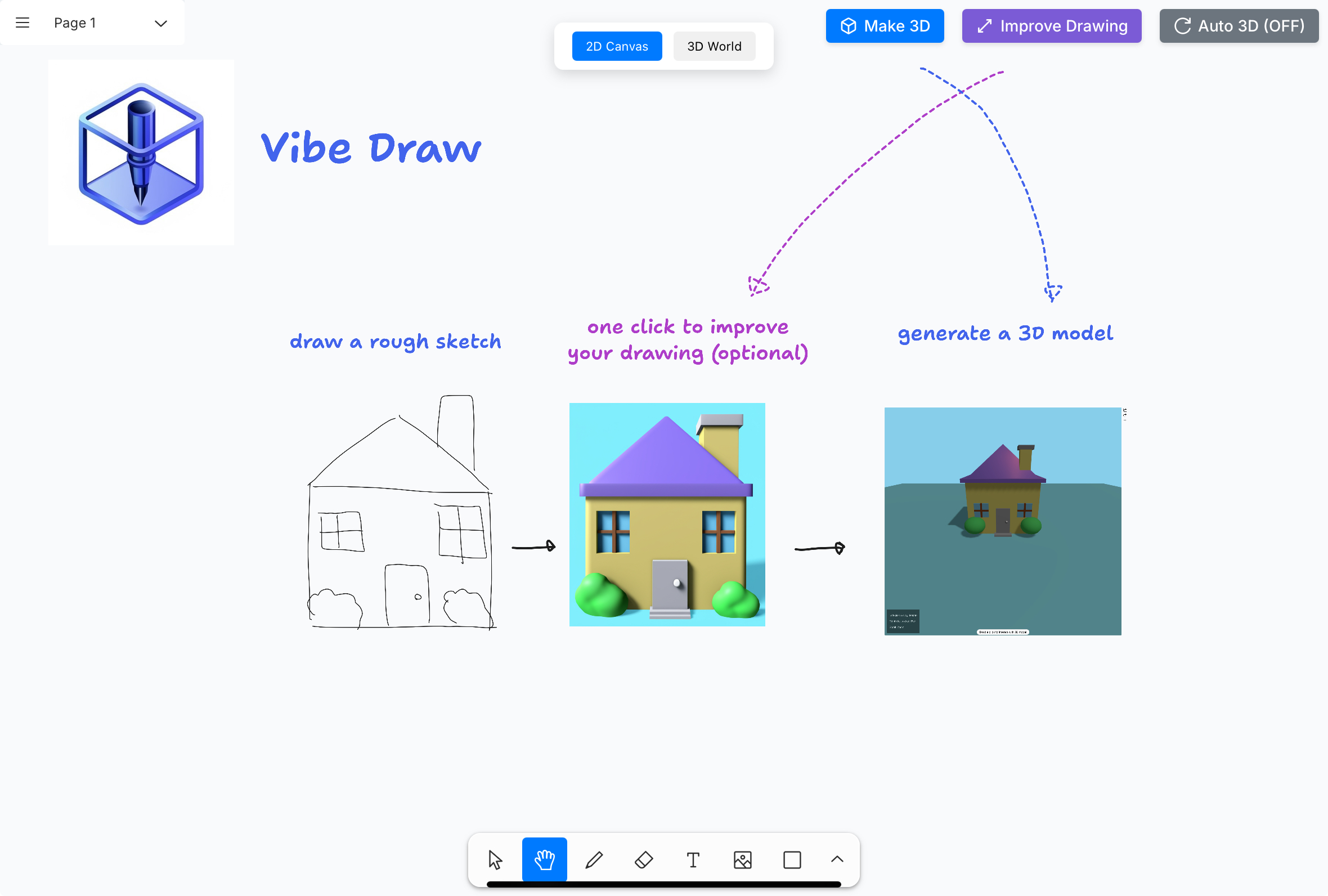
Vibe Draw:涂鸦秒变3D模型!开源AI建模神器解放创意生产力
ObjectMover:港大联合Adobe打造图像编辑黑科技,移动物体光影自动匹配
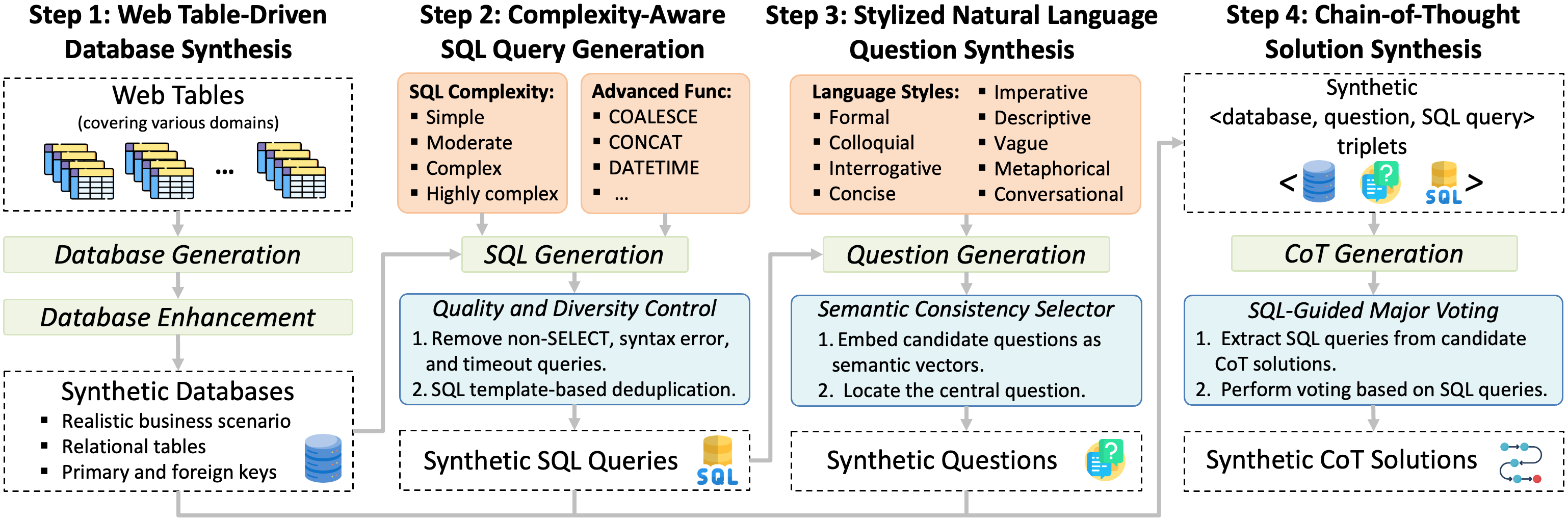
OmniSQL:开源文本到SQL神器!自然语言秒转查询到复杂多表连接等SQL需求
HarmonyOS NEXT - @State状态变量
PhysGen3D:清华等高校联合推出,单图秒变交互式3D场景
ChatAnyone:阿里通义黑科技!实时风格化肖像视频生成框架震撼发布
PaddleSpeech:百度飞桨开源语音处理神器,识别合成翻译全搞定
HarmonyOS NEXT - @CustomDialog自定义弹窗
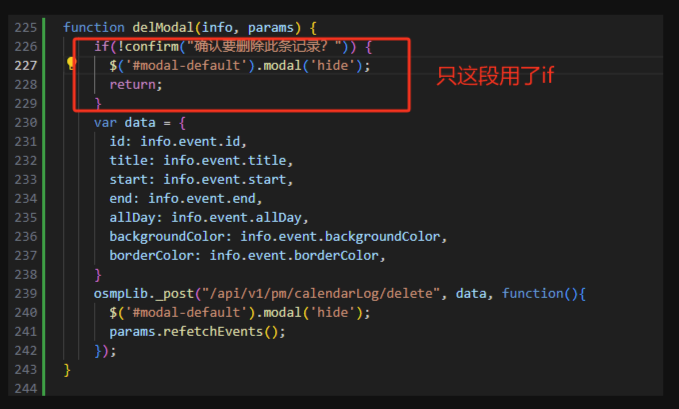
【Javascript系列】Terser除了压缩代码之外,还有优化代码的功能
HarmonyOS NEXT - AlertDialog警告弹窗
HarmonyOS NEXT - @Component自定义组件
HarmonyOS NEXT - @Builder自定义构建函数
HarmonyOS NEXT - 样式装饰器:@Styles和@Extend
YashanDB环境变量
YashanDB实例启停
YashanDB客户端安装
YashanDB服务端安装
社区积分兑好礼