create procedure Sniff1(@i int) as
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@i;
go
DBCC FREEPROCCACHE
exec Sniff1 50000;
exec Sniff1 75124;
go
create procedure Nosniff1(@i int) as
declare @cmd varchar(1000);
set @cmd = 'SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =';
exec(@cmd+@i);
go 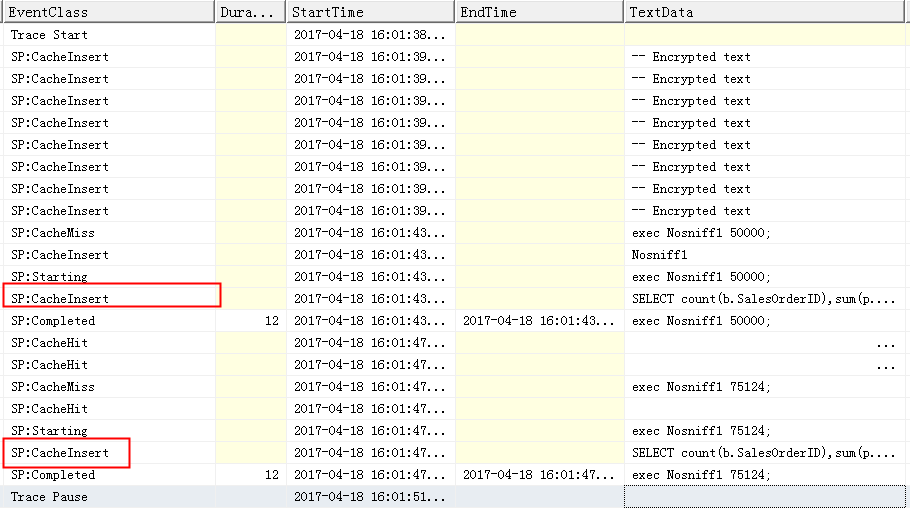
exec Nosniff1 50000;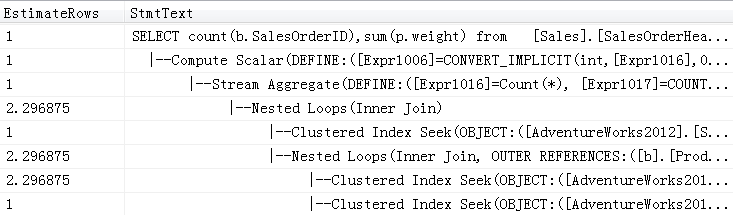
exec Nosniff1 75124;
从上述trace中可以看到,在执行查询语句之前,都有SP: CacheInsert事件,SQL Server做了动态编译,根据变量的值,都正确的预估了结果集,给出了不同的执行计划。
2. 使用本地变量
create procedure Nosniff2(@i int) as
declare @iin int;
set @iin=@i
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@iin;
go
exec Nosniff2 50000;
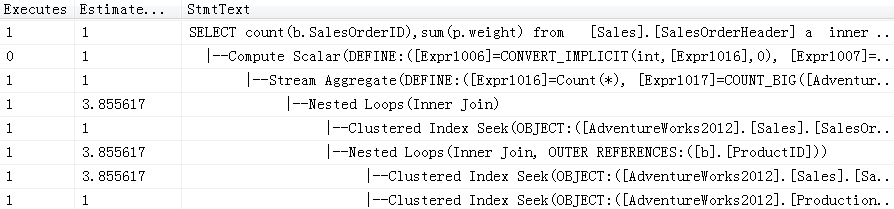
exec Nosniff2 75124; 

如上一篇文章所述,使用本地变量,参数值在存储过程语句执行过程中得到,SQL Server在运行时不知道变量的值,会根据一个预估值进行编译,给出一个折中的执行计划。
3. 使用Query Hint,指定执行计划
在 SELECT、DELETE、UPDATE 和 MERGE 语句最后加上OPTION ( <query_hint> [ ,...n ] ),对执行计划进行指导。当数据库管理员知道问题所在时,可以通过hint引导SQL Server生成一个对所有变量都不太差的执行计划。
SQL Server 的Query Hint有十几种,具体信息参考https://docs.microsoft.com/en-us/sql/t-sql/queries/hints-transact-sql-query 。
针对parameter sniffing的问题,有几种hint可以使用。
- Recompile
Recompile有两种方式,一种是存储过程级别的,一种是语句级别的。具体实现方式如下。
存储过程级别:
create procedure Nosniff_Recompile(@i int)
with recompile as
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@i;
go
exec Nosniff_Recompile 75124;
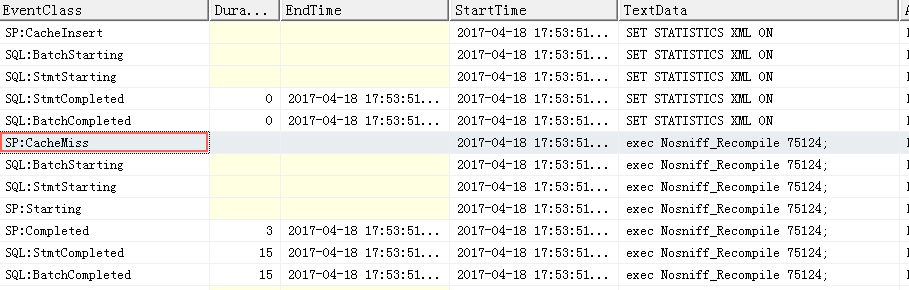
语句级别:
create procedure Nosniff_Recompile2(@i int) as
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@i option(recompile)
go
exec Nosniff_Recompile2 75124;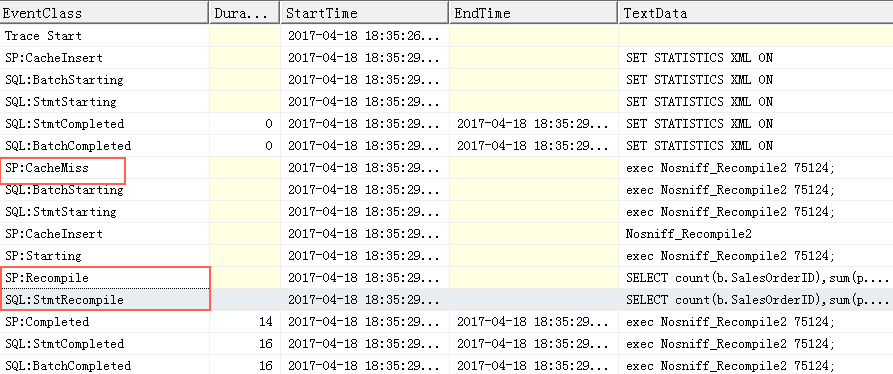
这两种recompile方式都可以获得准确的执行计划,区别在于,如果是语句级别的recompile,那么存储过程级别的执行计划重用还是会有的,只有运行到指定语句的时候才会重新编译这个语句。如果存储过程很复杂,存在多个语句,可以指定某个语句中进行重编译,这是一种精细化的调优方式。
- Optimize for ( @variable_name { UNKNOWN | = literal_constant } [ , ...n ] )
当确认parameter sniffing后,确定了某个参数值重用执行计划会特别慢,那么可以使用optimize for 某个参数,来倾向性的生成执行计划。
create procedure Nosniff_OptimizeFor(@i int) as
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@i option(optimize for(@i=75124))
go
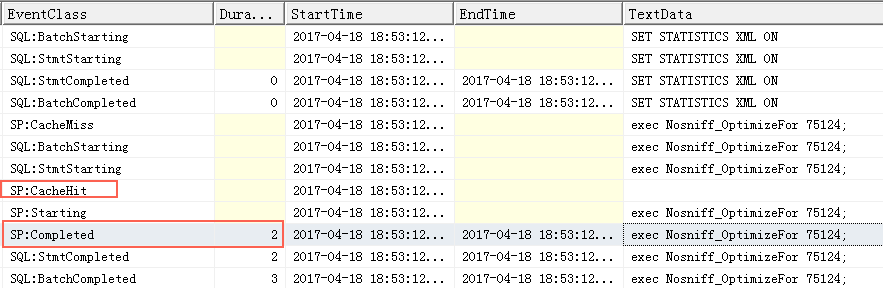
exec Nosniff_OptimizeFor 50000;
exec Nosniff_OptimizeFor 75124;执行50000时,会生成一个执行计划,不过执行计划是根据75124来预估的,所以执行75124时,重用了执行计划,但是执行效率也不差。
- Plan guid
Exec sp_create_plan_guide
@name='Guide1',
@stmt='
SELECT count(b.SalesOrderID),sum(p.weight) from
[Sales].[SalesOrderHeader] a
inner join [Sales].[SalesOrderDetail] b
on a.SalesOrderID = b.SalesOrderID
inner join Production.Product p
on b.ProductID = p.ProductID
where a.SalesOrderID =@i',
@type=N'object',
@module_or_batch=N'Sniff1',
@params=NULL,
@hints=N'option(optimize for(@i=75124))';
go当下次调用存储过程Sniff1时,不管输入的参数是什么,都会根据75124去进行预估,生成执行计划。
