本节书摘来自华章社区《Python数据挖掘:概念、方法与实践》一书中的第1章,第1.1节什么是数据挖掘,作者[美] 梅甘·斯夸尔(Megan Squire),更多章节内容可以访问云栖社区“华章社区”公众号查看
1.1 什么是数据挖掘
前文解释了数据挖掘的目标是找出数据中的模式,但是细看之下,这一过分简单的解释就站不住脚。毕竟,寻找模式难道不也是经典统计学、商业分析、机器学习甚至更新的数据科学或者大数据的目标吗?数据挖掘和其他这些领域有什么差别呢?当我们实际上是忙于挖掘模式时,为什么将其称作“数据挖掘”?我们不是已经有数据了吗?
从一开始,“数据挖掘”这一术语就明显有许多问题。这个术语最初是统计学家们对盲目调查的轻蔑叫法,在这种调查中,数据分析人员在没有首先形成合适假设的情况下,就着手寻找模式。但是,这一术语在20世纪90年代成为主流,当时的流行媒体风传一种激动人心的研究,将成熟的数据库管理系统领域与来自机器学习和人工智能的最佳算法结合起来。“挖掘”这一单词的加入预示着这是现代的“淘金热”,执著、无畏的“矿工”们将发现(且可能从中得益)之前隐藏的珍宝。“数据本身可能是珍稀商品”这一思路很快吸引了商业上和技术刊物的注意,使他们无视先驱们努力宣传的、更为全面的术语—数据库中的知识发现(KDD)。
但是,“数据挖掘”这一术语沿用了下来,最终,该领域的一些定义试图改变其解释,认为它指的只是更漫长、更全面的知识发现过程中的一步。今天“数据挖掘”和KDD被视为非常相似、紧密相关的术语。
那么,其他相关术语如机器学习、预测性分析、大数据和数据科学又是怎么回事?这些术语和数据挖掘或者KDD是不是一回事?下面我们比较这些术语:
机器学习是计算机科学中的一个非常特殊的子领域,其焦点是开发能从数据中学习以作出预测的算法。许多数据挖掘解决方案使用了来自机器学习的技术,但是并不是所有数据挖掘都试图从数据中作出预测或者学习。有时候,我们只是想要找到数据中的一个模式。实际上,在本书中,我们所研究的数据挖掘解决方案中只有少数使用了机器学习技术,而更多的方案中并没有使用。
预测性分析有时简称为分析,是各个领域中试图从数据中作出预测的计算解决方案的统称。我们可以思考商业分析、媒体分析等不同术语。有些(但并不是全部)预测性分析解决方案会使用机器学习技术进行预测,但是同样,在数据挖掘中,我们并不总是对预测感兴趣。
大数据这一术语指的是处理非常大量数据的问题和解决方案,与我们是要搜索数据中的模式还是简单地存储这些数据无关。对比大数据和数据挖掘这两个术语,许多数据挖掘问题在数据集很大时更为有趣,所以为处理大数据所开发的解决方案迟早可用于解决数据挖掘问题。但是这两个术语只是互为补充,不能互换使用。
数据科学是最接近于KDD过程的术语,数据挖掘是它们的一个步骤。因为数据科学目前是极受欢迎的流行语,它的含义将随着这一领域的成熟而继续发展和变化。
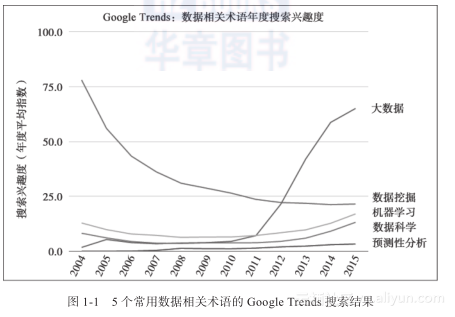
我们可以查看Google Trends,了解上述术语在一段时期内的搜索热度。Google Trends工具展示了一段时期内人们搜索各种关键词的频度。在图1-1中,新出现的术语“大数据”目前是炙手可热的流行语,“数据挖掘”居于第二位,然后是“机器学习”、“数据科学”和“预测性分析”。(我试图加入搜索词“数据库中的知识发现”,但是结果太接近于0,无法看到趋势线。)y轴以0~100的指数显示了特定搜索词的流行度。此外,我们还将Google Trends给出的2014~2015年每周指数组合为月平均值。