1 概述
随着深度学习技术的发展,尤其是卷积神经网络(Convolutional Neural Networks,CNN)和循环神经网络(Recurrent Neural Networks,RNN)的发展,文字识别(Optical Character Recognition,OCR)和场景文字识别(Scene Text Recognition,STR)在近年来有了飞速的发展。文字识别主要分为两步:文字检测和文字识别。其中,文字检测主要有基于笔划特征的方法(Stroke Width Transform,SWT)、基于稳定区域(Maximally Stable Extremal Region,MSER)的方法和基于全卷积网络(Fully Convolutional Networks,FCN)的方法。而文字识别则主要分为基于字符/单词分类的方法和基于序列的识别方法。
与传统的OCR服务不同,YunOS更关注用户照片中的内容,即自然场景中的文字识别技术。因此,我们的技术方案更关注训练样本的多样性和基础分类模型的性能,较少地考虑文档的先验结构。
下面先简要介绍已有方法,然后介绍我们的方法和接入方式。
2 现有方法
2.1 文字检测
如上所述,文字检测方法主要分为三类:基于笔划特征、基于稳定区域和基于卷积网络。代表性方法如下。
1)Stroke Width Transform,SWT [1]
SWT假设每个字符的笔划宽度是大致相同的,因此从一个Canny边缘点沿梯度方向出发,如果能够找到梯度方向相反的边缘点,则认为该笔划宽度有效。检测完所有边缘点后,基于笔划宽度过滤,即可得到文字置信度。其过程如下图1和图2所示。该方法简单有效,但在自然场景中会导致很多虚警。这些虚警通常出现在类似文字的区域,如:条环、窗户、砖块和网格等。

图1 - 文字的局部梯度方向
2)Maximally Stable Extremal Region,MSER [2-3]
MSER首先提取图像中最大稳定极值区域的作为候选,然后通过分类器滤除不合法的候选区域,最后将过滤后的候选区域,通过一系列的后处理和连接规则组合为文本行。该算法利用的先验知识较少,对语种、文字的角度就较为鲁棒。但与SWT类似,其在复杂背景下容易产生虚警,影响后续步骤。

图3 - 基于最大稳定极值区域MSER的文字检测
3)基于文字分类CNN和连通域分析的方法[4-5]
该方案是将图像输入“文字分类CNN”,得到对应的文字置信度图,然后使用连通域分析计算文字行。该方案中的CNN基于文字正负样本训练而成,须要切图、负样本采样等步骤,效率较低,其性能易受正负样本的多样性影响。

图4 - 基于文字分类CNN和连通域分析的方法
4)基于FCN的方法 [6-9]
该方案将检测问题看作一种广义的“分割问题”,避免了3)中的正负样本准备步骤,以end-to-end的方式预测文字区域mask(如图6和图7所示)。在mask的基础上进行坐标回归、字符切分、行分析等操作,从而得到最终的文字行坐标。该方案对尺度、方向、复杂背景的鲁棒性均较强,目前已成为文字检测的主流方法。

图5 - 近似横排文字的检测效果
图6 - 任意角度文字的检测效果
5)基于FCN和RNN的联合方法
在FCN的基础上,[10]将RNN引入到文字检测任务中,以获取更大的横向感受野(Receptive Field)。结果表明,该方法对于水平文字效果非常好,但其较难推广到任意角度。
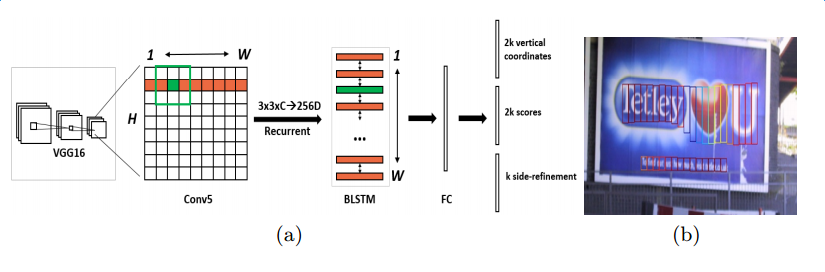
图7 - 基于CNN和RNN的联合方法
2.2 文字识别
文字识别方法主要分为三类:基于浅层模型的字符识别、基于深度网络的字符/单词识别、序列识别。代表性方法如下。
1)基于浅层模型的字符识别方法
将文字行按字符切割后,文字识别即可看作字符分类问题。通常的做法是,提取字符的描述特征,然后使用分类器进行分类。常采用的文字特征有局部矩、HOG、SIFT等[11-12]。在[13]中Shi等人提出一种基于DPM(Deformable Part Model)的文字表达方法。DPM可适应字体变化,对噪声、模糊等因素较为鲁棒。
图8 - 数字和英文字母的DPM样例
2)基于深度网络的字符/单词识别方法
用深度网络代替传统的人工特征,即可大幅提升识别率。第一种做法与传统方法类似,采用CNN对字符进行分类(如图9),另一种则对单词进行分类(如图10)。字符分类网络的训练相对容易,但由于完全不考虑语义信息,其准确率相对较低。
CNN强大的表达能力使得“单词级”的分类成为可能,其类别数普遍较大,如:英文9万。[14]使用此暴力方法在英文识别任务上取得了当时最好的结果。此类方法主要存在两处不足:a)其依赖预先定义的词典,不能识别字典外单词(Out-of-Vocabulary Problem);b)对于过长的单词,输入图像的形变往往较大,会影响识别率。
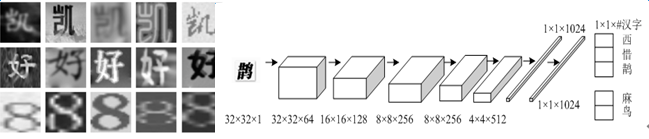
图9 - 中、英、数混合字符识别网络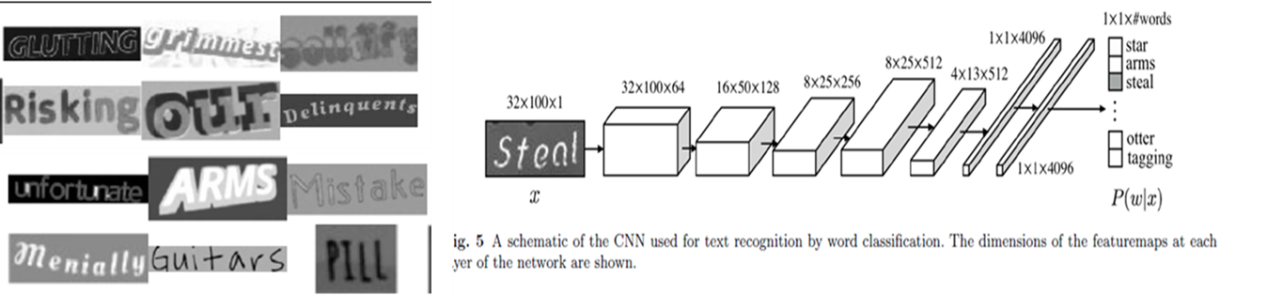
图10 - 英文单词识别网络
3)基于序列的文字识别方法
此外,字符和单词识别方法的性能严重依赖于文本切分的精度。针对此问题,基于序列的文字识别方法应运而生。此类方法与语音识别方法非常相似,其将文字行看作一个整体,不做切分,直接批量或增量识别出其中的字符序列。这种方法能够更充分地利用文字序列上下文关联进行消歧,避免字符误分割造成的不可逆错误。在此框架下,训练集的准备也更加简单,只需标注整行对应的文字内容,无需标注每个字符的具体位置。
文字行识别主要有两种结构,其一是CNN+LSTM+CTC结构[15-16](见图11),其二是CNN+LSTM+Seq2Seq [17](见图12)。这两种方法的主体是一致的,首先采用CNN学习图像相邻像素之间的关系,然后采用双向长短期记忆神经网络(Bidirectional Long Short-Term Memory,BLSTM)学习较长跨度的上下文关系(感受野为整行)。最后分别采用CTC(Connectionist Temporal Classification)和Seq2Seq作为目标函数优化整个网络的参数。
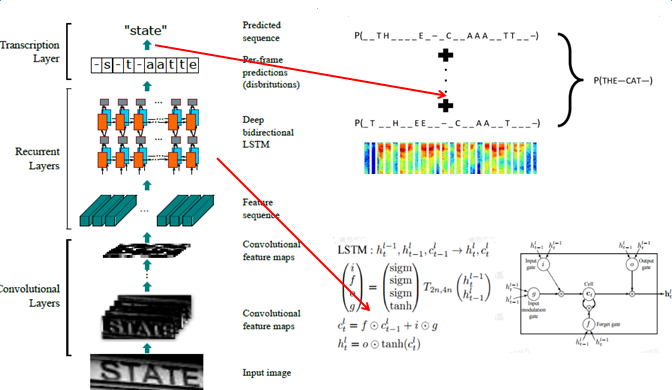
图11 - 基于CNN+LSTM+CTC的英文单词识别
图12 – 基于CNN +LSTM+Seq2Seq的英文单词识别
3 技术方案
我们的方案沿用了当前的主流方法,分为三步:训练数据合成、文字行检测和文字行识别,其流程如图13所示。下面将展开介绍检测和识别步骤的细节和特点,训练数据的合成将在其中穿插介绍。

图13 - 技术方案流程
3.1 检测步骤
3.1.1 训练数据生成
深度网络的性能强依赖于大规模和多样化的数据,而文字数据的人工标注成本往往较高(约为0.1元/文本框),此外也存在标注速度问题(125个/每小时)。为节约成本和提升效率,我们采取了“以合成数据为主,人工标注数据为辅”的策略。
合成流程与[18]基本一致,步骤如下:
- 准备大量不含文字的背景图像
- 准备丰富多样的各类字体
- 准备的丰富的文本语料,按行组织
- 对背景图片做区域分割和深度估计
- 随机选取背景图、字体、区域等参数,将随机选取的文本行渲染到背景图上
- 在渲染过程中,记录每个文本框的坐标
整个过程自动进行,在数天内我们合成了超过50W的训练样本。样例如图14所示,可看出合成样本较为接近真实场景,为网络训练打下了较好的基础。

图14 - 合成的文字检测训练数据
3.1.2 网络训练
如前所述,FCN是目前主流的文字检测方法。而另一种非常流行的物体检测方法Faster-RCNN在文字检测中的效果却不尽如人意,其主要原因是:文字的形状往往为长条状,不太适合采用感受野(Receptive Field)比例接近1:1的网络结构。
若网络的感受野太小,则难以检测较长的文字(图15绿色框),若扩大感受野,则在短边方向存在较大浪费,较难区分多行文字(图15红色框)。由于无法预知文字方向,构造长方形感受野的方案也不太可行。对于英文单词,其长宽比一般在可接受范围内(如:从1:5到5:1),此矛盾不会凸显。而对于中文或中英混排文字行,如何有效地检测带状物体是提升性能的关键。

图15 - 感受野与分辨率之间的矛盾
为解决此问题,我们于2016年10月提出了采用“FCN局部文字块检测”和“几何约束下的行生成”来检测任意长度文字行的方案(如图16所示)。该方案主要思想是:将文字行切分为局部方形框,使用FCN检测其擅长的方形文字块,同时预测每个文字块与近邻间的连接关系。

图16 - 文字行检测过程
FCN前部是普通的卷积、Pooling等层,后部分为三支,分别输出:文字置信度、局部文字框坐标、局部角度。置信度采用二分类交叉熵作为目标函数,坐标采用L2或L1距离作为目标函数,角度采用相关性(或Cosine相似度)作为目标函数。整体目标函数由上述三项加权得到。
在测试阶段,首先根据置信度筛选出少量候选文字块(数百个);然后根据候选块之间的相互几何关系构建图(Graph),几何关系可包括:距离、相对大小、角度一致性等;最后对图进行分割,可采用最简单的连通子图方法,也可采用GraphCut等复杂方法。
图17和图18详细展示了经过该方案中的中间结果和最终检测结果。

图17 - 检测的中间和最终结果

图18 - 检测的中间和最终结果
该方案的不足在于,其将检测过程拆分为独立的两步:局部检测和合并,而两步之间鸿沟会导致误差累积。虽然网络输出的方向信息为合并操作提供了重要的线索,若我们能将两步有机地串连起来,相信会带来较大的性能提升。此外,从上图中可以看出FCN输出的文字置信度有棋盘格效应,这种效应一般由反卷积(或称为Transposed Convolution)操作导致[19],通过某些平滑技巧即可避免,可能对性能有一定帮助。
值得注意的是,近期学术界也开始采用类似的方法[8, 20]来检测场景文字,并取得了较好的结果。这类从局部到整体的检测方法在人体姿态估计问题中也有成功的应用[21]。
3.2 识别步骤
3.2.1 训练数据生成
与文字检测类似,在识别步骤中我们仍采用“以合成数据为主,人工标注数据为辅”的策略。对于识别任务,各类样本的均衡性非常重要,但各字符在真实语料或图象中的分布却非常不均匀,往往为长尾分布(如图19所示)。采用自然数据训练的模型,常用字准确率一般较高,而长尾字准确率偏低。为提升长尾字的准确率,合成几乎是唯一可行的方案。
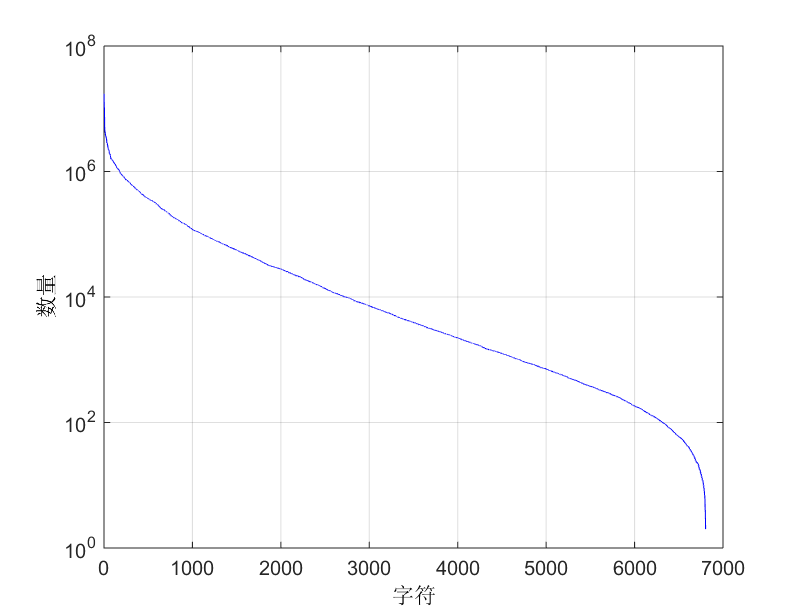
图19 - 中、英等字符呈典型的长尾分布
我们采用与3.1.1类似的步骤合成文字行,其中包含汉字、字母、标点、数字等6803类字符,加入了模糊、倾斜、透视、拉伸、阴影、描边、加框、随机噪声等变化,最终合成约500W张文字行图片。在合成过程中,通过对语料进行采样,可以获得几乎呈均匀分布的训练样本。样例如图20所示。

图20 - 合成的文字行识别训练数据
3.2.2 网络训练
如前所述,基于序列的文字行识别方法是当前主流,在自然场景下具有最好的性能。目标函数一般分为CTC和Seq2Seq两种,CTC的优点是收敛速度快,Seq2Seq收敛速度慢但其精度一般高于CTC。我们参考了近期MERL在语音识别中采用的方式[22],将CTC和Seq2Seq结合起来,并引入Attention机制。
整体网络结构如图21所示,其中Encoder部分由CNN和BLSTM组成负责将图像转换为抽象的特征表达,Decoder部分负责从特征中解码字符。Decoder分为两支,CTC分支一边配准一边计算特征与Label之间的损失,Seq2Seq分支利用Attention机制关注特征的某些局部,并按时序解码字符。实验证明,联合训练方案的精度确实更优,且收敛速度与CTC相当。

图21 - Joint CTC+Seq2Seq (with Attention)
3.3 ICDAR RRC 2015
为验证方案的有效性,我们于2016年11月在ICDAR RRC 2015 [23]的三个场景下测试并提交了英文模块的性能,在当时取得了一项排名第一,二项排名第二。结果如图22所示。
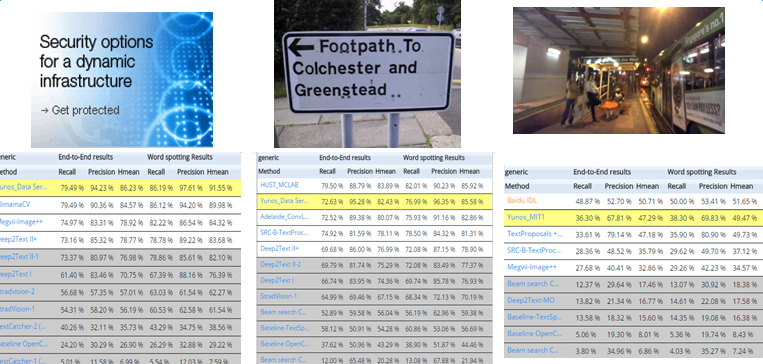
图22 - 在ICDAR RRC 2015 Generic协议下的结果(时间:2016年11月)
当然,现有服务还存在诸多不足,我们正在持续改进。
- 竖行文字检测精度不够理想
- 竖行文字识别模块缺失
- 暂不支持“空格”,会导致英文单词粘连
另外,相应离线版本也在开发中,预计2017年7月底会有初步成果,相关内容会单独介绍
参考文献
[1] Epshtein, Boris, Eyal Ofek, and Yonatan Wexler. "Detecting text in natural scenes with stroke width transform." Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
[2] Neumann, Lukas, and Jiri Matas. "A method for text localization and recognition in real-world images." Computer Vision–ACCV 2010 (2011): 770-783.
[3] Neumann, Lukáš, and Jiří Matas. "Real-time scene text localization and recognition." Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012.
[4] Jaderberg, Max, et al. "Reading text in the wild with convolutional neural networks." International Journal of Computer Vision 116.1 (2016): 1-20.
[5] Jaderberg, Max, Andrea Vedaldi, and Andrew Zisserman. "Deep features for text spotting." European conference on computer vision. Springer International Publishing, 2014.
[6] Zhang, Zheng, et al. "Multi-oriented text detection with fully convolutional networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[7] Yao, Cong, et al. "Scene Text Detection via Holistic, Multi-Channel Prediction." arXiv preprint arXiv:1606.09002 (2016).
[8] Zhou, Xinyu, et al. "EAST: An Efficient and Accurate Scene Text Detector." arXiv preprint arXiv:1704.03155 (2017).
[9] Moysset, Bastien, Christopher Kermorvant, and Christian Wolf. "Full-Page Text Recognition: Learning Where to Start and When to Stop." arXiv preprint arXiv:1704.08628 (2017).
[10] Tian, Zhi, et al. "Detecting text in natural image with connectionist text proposal network." European Conference on Computer Vision. Springer International Publishing, 2016.
[11] Wang, Kai, Boris Babenko, and Serge Belongie. "End-to-end scene text recognition." Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
[12] Yao, Cong, et al. "Strokelets: A learned multi-scale representation for scene text recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014.
[13] Shi, Cunzhao, et al. "Scene text recognition using part-based tree-structured character detection." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2013.
[14] Jaderberg, Max, et al. "Reading text in the wild with convolutional neural networks." International Journal of Computer Vision 116.1 (2016): 1-20.
[15] He, Pan, et al. "Reading scene text in deep convolutional sequences." Thirtieth AAAI Conference on Artificial Intelligence. 2016.
[16] Shi, Baoguang, Xiang Bai, and Cong Yao. "An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition." IEEE Transactions on Pattern Analysis and Machine Intelligence (2016).
[17] Lee, Chen-Yu, and Simon Osindero. "Recursive Recurrent Nets with Attention Modeling for OCR in the Wild." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[18] Gupta, Ankush, Andrea Vedaldi, and Andrew Zisserman. "Synthetic data for text localisation in natural images." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
[19] http://distill.pub/2016/deconv-checkerboard/
[20] Shi, Baoguang, Xiang Bai, and Serge Belongie. "Detecting Oriented Text in Natural Images by Linking Segments." arXiv preprint arXiv:1703.06520 (2017).
[21] Cao, Zhe, et al. "Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields." arXiv preprint arXiv:1611.08050 (2016).
[22] Kim, Suyoun, Takaaki Hori, and Shinji Watanabe. "Joint ctc-attention based end-to-end speech recognition using multi-task learning." arXiv preprint arXiv:1609.06773 (2016).
[23] http://rrc.cvc.uab.es/