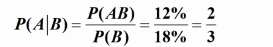本节书摘来自华章出版社《短文本数据理解(1)》一书中的第2章,第2.3节,作者王仲远,更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.3 属性得分推导
本节首先直观地讨论属性的打分原则,进而介绍如何处理CB和IB列表以完成对属性的打分,最后讨论如何聚合不同数据源的属性得分。
2.3.1 典型度得分
这项工作的目的在于计算属性概念对的P(a|c)数值。这个概率分数对机器推测有很大作用。
这个概率分数被定义为典型度(typicality)。在认知学和心理学上[104],典型度被用来研究为什么某些实体因为某个概念而被人类特别提起。例如,dog为pet的典型实体,因为它被频繁地当成pet提及,而且它与其他的pet实体具有很高的外形相似度[164]。同理,上述直觉可被用来研究属性的典型度。
如果属性a为概念c的典型属性,它应满足两个原则:
a与c常常共同出现(频率)。
a在c的实体的属性中很常见(家族相似度)。
根据上述直觉,population是country的一个典型属性,因为二者在CB和IB列表中被频繁观测。更进一步,这是由于大多数country的实体,比如China和Germany,都有population这个属性。
上述论证证实了使用CB和IB量化P(a|c)的意义。二者都考虑了频率原则并且IB还考虑了家族相似度原则。相比之下,大多现有工作没有考虑这两项原则或只考虑了其中一项,如,参考文献[126,82,124,160]只考虑了频率;参考文献[125]只考虑了家族相似度;参考文献[122,138]没有考虑任何原则,而是使用属性的语境相似度。
下面将讲述如何从CB列表中将频率实体化,以及如何从IB列表中将频率和家族相似度实体化。
2.3.2 根据CB列表计算典型度
回顾一下,CB列表的格式为(c,a,n(c,a))。按概念c为列表分组,可得到概念c的一系列属性a,以及它们的频率分布。给出这些信息,典型度得分P(a|c)可被计算为:
2.3.3 根据IB列表计算典型度
下面阐述根据IB列表(i,a,n(i,a))计算典型度的方法。如前文所述,三组IB列表分别从网页文本、搜索日志和知识库中获取。这三组列表的质量在不同的概念c上有差异。因而,本章方法分别计算三组列表的典型度得分,然后将三组得分同CB列表的得分聚合。
为将IB模式联系到概念上,P(a|c)被展开为:

基于这项展开式,任务被转化为计算P(a|i,c)和P(i|c)。举例而言,考虑IB模式“the age of George Washington”,如果机器知道“George Washington”是概念president的实体,那么这句话可以被用来计算属性age和概念president之间的典型度得分。在上式中,P(a|i,c)可将age和president间的典型度量化,而P(i|c)表示实体“George Washington”对概念president的代表性。
通过Probase计算P(a|i,c)和P(i|c):P(a|i,c)和P(i|c)可以基于Probase计算。Probase记录着“George Washington”对概念president的代表性。为方便表达,下面假设一个实体只属于一个概念,后文将讨论去除该假设的情况。
首先计算P(a|i,c)。在P(a|i,c)=P(a|i)的假设下,P(a|i,c)可被计算为:

因此,这一任务被转化为从Probase获取P(c|i)。在先前的简化假设下,P(c|i)表示概念c对某一实体i的代表性。在Probase中如果这对概念和实体被观测到,则P(c|i)=1,否则P(c|i)=0。
在实际情况中,一个实体可能属于多个概念,从而衍生出如下两种情况:
[C1]有歧义的实体与不同的概念相关:“Washington”可能表示president或state,而这两个概念的典型属性很不相同。简单的计算方式会导致将population错误地鉴别为概念president的典型属性。
[C2]无歧义的实体与相同的概念相关:即使某一实体没有歧义,它也有可能出现在不同的语境中。例如,“George Washington”可能代表一个总统(president)、爱国者(patriot)或历史人物(historical figure)。属于不同概念的有歧义实体计算出的P(i|c)理论上应比属于相似概念的无歧义实体计算出的值低。简单的计算不能考虑概念间的相似性。
基于上述分析,我们的任务是无偏见地估算P(a|i,c)和P(c|i)的值。
P(a|i,c)和P(c|i)无偏见化:下面介绍如何无偏见化P(a|i,c)和P(c|i),以解决C1和C2两种情况。
首先计算P(a|i,c),如果实体i有歧义,一个从别的概念中获取的更高n(i,a)值不应被考虑。例如,虽然population与Washington常常共现,在state name语境下,population不应被考虑成president的属性。因此,相交率(Join Ratio,JR)这个概念被使用来表示属性a与概念c相关的可能性。

其中JC(a,c)被定义为概念c中的实体含有属性a的次数,这将a的家族相似度量化。通过观察,population之于president的JR得分接近0。这是由于概念president中的大多实体,如“George Bush”,都没有population这个属性。
基于这个观念,式(29)可被去偏见化:

其中n(i,a,c)=n(i,a)JR(a,c)。
接下来计算P(c|i)。考虑一个实体属于多个概念的情况,如C2,P(c|i)可通过Probase中的频率统计np(c,i)计算:

然而,使用上述公式不能很好地区分C1和C2。因而,我们通过计算两个概念c和c*之间的相似性来降低那些从不相似概念中获取的频率的权重。这一相似性可通过Probase,使用两个实体集的Jaccard相似分数来计算。通过这一取值为0~1的相似分数sim(c,c′),P(c|i)可被计算为:

其中nu(c,i)=∑c′np(c′,i)sim(c,c′)。这样一来,不仅歧义问题得以处理,频率和家族相似度两项典型度原则也得以反映。
表24对比了式(213)和式(214)得出的P(i|c)。去偏见化前,有歧义实体的P(i|c)被过高估计,比如“Washington”。去偏见化后,其数值明显降低。相比之下,实体“Bush”虽与两个总统相关,但都对应president这个概念,因而应在president这个概念上得到较高得分。通过观察,去偏见化的结果符合这一原则,比如说“George Washington”和“Bush”的P(i|c)分数都比“Washington”的要高。

表25描述了去偏见化是如何改进president这个概念的属性典型度排名的。表中所列的不属于president的属性在排名上都有不同程度的降低。这是由于在去偏见化前,“Washington”的P(i|c)被高估,但其还可能属于state这个概念,这会导致与state相关的属性在president上也获得较高得分。

2.3.4 典型度聚合
本节前面部分讨论了如何从CB网页文本列表中计算P(a|c),以及如何从IB的三个列表(网页文本、搜索日志和知识库)中计算该值。我们将这四个得分分别标记为PCB(a|c)、PIB(a|c)、PQB(a|c)和PKB(a|c)。
要聚合这些得分并不是一项简单的工作,不同的分数来源对不同的概念有着互补的优势。对于包含很多有歧义的实体的概念,IB获取的得分置信度较低。比如,概念wine中的很多实体具有歧义,像“Bordeaux”和“Champagne”可以表示city的名字,从而具有city相关的属性,如mayor。在此例中,IB获取的得分置信度较低。然而在其他情况下,当概念可被扩展为大量无歧义的实体时,IB给出的得分则十分可靠。
这些观察表明单数据源不可能为所有概念给出可靠的得分,因而应将不同来源的得分聚合。我们希望算法能够基于概念特征自动为得分调整权重,从而为所有的概念给出可靠的得分。同现有的方法不同,这一新的算法框架可被应用于大量概念之上。
更为正式地,P(a|c)的计算可被转化为:

目标被转化为学习某一概念的相关权重。
这项任务采用线性核函数的Ranking SVM方法。该方法为一种常见的Pairwise排序算法,同回归算法相比,其优势在于训练数据不需要具备准确的典型度得分标签。这符合问题的需求:虽然不能得到某一属性(比如population)的绝对得分,但可以陈述population比picture更典型这一事实。通过收集这样的成对比较数据作为训练数据,式(215)中的权重可被训练得到。
更为正式地阐述,来源M的权重wM为fiM的线性组合,其中特征为实体i的歧义度或模式的统计显著性。
f1M(avg Mod Bridging Score:Bridging Score[121]通过实体是否属于不同概念来度量它的歧义度。

直观上说,这一分数在包含歧义的实体上较低,如“Washington”。实验表明,Bridging Score的一种变换Mod Bridging Score更为有效。
f2M(avgP(c|i)):当实体属于很多不同的概念时,P(c|i)的值较低,因而它也可以作为实体歧义度的度量。
f3M(∑(frequencyM(a))/#AttributeM):当平均每属性的属性频率较低时,统计显著性较低。
f4M(∑(frequencyM(a))/#InstanceP):当平均每实体的属性频率较低时,统计显著性较低。
f5M(#AttributeM/#InstanceP):当概念中实体的平均属性数较低时,对该概念的特征提取有效性较低。
更为正式地,wM可被表示为五个特征的线性合并wM=w0M+∑kwkMfkM。式(215)可被扩展为下式。

可见,这是一系列元素的线性变换。线性核函数的Ranking SVM算法可被用来学习参数。同已有的方法不同,上面提出的方法不需要覆盖所有概念的训练数据。
2.3.5 同义属性集合
将概念和属性的关系量化后,我们得到一系列概念的属性。由于这些属性从网站获取,人们可能会使用不同的词来表示相同的含义,比如mission和goal都表示目的。
因而,另一项重要工作为将同义属性分组。若不进行这项工作,相同意义的属性会被分散稀释。
本章方法借助Wikipedia[100]找寻同义属性,具体采用如下方式:
Wikipedia重定向:一些Wikipedia链接没有自己的页面,访问这些链接会被重定向到相同主题的其他文章。下文使用xi→yi表示重定向。
Wikipedia内部链接:Wikepedia的内部链接被表示为[[Title|Surface Name]]。其中Surface Name为当前文本,Title为链接到的网页。下文同样用xi→yi表示链接关系。
使用这些关系对可以链接同义属性。所有相连的属性可被视作一个属性聚类。在一个聚类内,频率最高的属性被当作该属性聚类的代表属性。