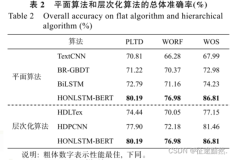
本节书摘来自华章出版社《短文本数据理解(1)》一书中的第2章,第2.1节,作者王仲远,更多章节内容可以访问云栖社区“华章计算机”公众号查看
第2章 基于概率的属性提取与推导
知识库包含概念、实体、属性和关系,它在许多应用中的作用日渐突出。本章强调(概念和实体的)属性知识对推测的重要性,并提出一种为百万级的概念推导出属性的方法。该方法将属性和概念的关系量化为典型性(typicality),使用多个数据源来聚合计算这些典型度得分,这些数据源包括网页文本、搜索记录和现有的知识库。该方法创新性地将基于概念和实体的模式融合计算典型度得分,大量的实验证明了该方法的可行性。
2.1 引言
创建概念、实体和属性的知识库的目的在于赋予机器像人类一样的推测能力。在推理这个任务中,输入数据往往稀疏、噪点大且包含歧义。人类能很好地理解这样的文本是因为人类具备抽象的先验知识。类似的,知识库旨在为机器提供这样的先验知识,从而使其能够调用知识来完成思考判断。可见,知识库是实现人工智能必不可少的元素。
一个知识库包含一系列的概念、实体和属性的关系。在这些关系中,如下三类尤为重要:
isA:子概念和概念的关系(如IT company isA company)。
isInstanceOf:实体和概念的关系(如Microsoft isInstanceOf company)。
isPropertyOf:属性和概念的关系(如color isPropertyOf wine)。
本章强调属性和概念的关系(isPropertyOf)对基于知识的推测尤其重要。然而,为了完成推断,机器不仅仅需要了解概念的属性,还需要知道每个属性的典型性。本章将重点介绍一种自动获取属性并为其打分的方法。该方法的产出为一个大型的数据库,如表21所示,整个数据库包含百万级的概念、属性以及属性的得分。这些分数对推测尤为重要,它们被定义为如下的典型度得分。
P(c|a)表示概念c在属性a上的典型度。
P(a|c)表示属性a在概念c上的典型度。

如表21所示,company不是name的典型概念,因为很多别的概念都有name这个属性。相比之下,company更像是operating profit的典型概念。这些典型性被量化为表中的得分:

从另一个角度而言,当人们谈论一个company时,更倾向于被提到的是它的name,而不是operating profit,因此:
如表21所示,式(22)中两项的典型度得分差异为006,远小于式(21)中两项的典型度得分差异09,这与人类的认知一致。
至此,本章阐述了概念、属性和典型度得分对基于知识推测的重要性。直观地,给出短文本
“capital city,population”,人们会联想到country。给出“color,body,smell”,人们则会联想到wine。然而在大多数情况下,属性和概念的关联并不那么直观。以图21为例,假设在网页上看到该图,人们能否很容易地推测出这张表格的标题?
根据单一属性,如website,人类无法准确推测图表含义。然而,如图21所示,当系统看到更多属性时,它所推测到的候选概念将减少。当图表呈现出6个或7个属性时,系统能够以较高的置信度获取正确的概念。而典型度得分P(c|a)和P(a|c)在这一过程中扮演着十分重要的角色。

下面是另外一个例子。
The Coolpix P7100is announced The powerful lens with 71x zoom offers high resolution(10MP)images
假设读者不知道Coolpix P7100为一款相机,他是否能够根据语境推测到其讲述的是相机呢?也许可以。那么具有知识库的机器能否完成相同的推测呢?假设通过自然语言处理技术,lens、zoom、resolution都被标注为知识库中的属性词,且只有camera和smart phone包含这些属性。那么,机器只需了解概率P(camera|lens;zoom;resolution)大于P(smart phone|lens;zoom;resolution),便可成功完成推
测。换言之,机器需要知道camera是上述属性更加典型的概念。
通过典型度得分,机器很容易便可完成上述推测。典型度得分的目的在于为属性寻找最可能的概念。更具体地说,需要找到概念c(,使其满足

其中A=(lens,zoom,resolution),为一系列属性。P(c|A)可以用朴素贝叶斯模型得到:

至此,该问题被转化为寻找一系列的典型度得分P(c|a)。
为支持上述的机器推测问题,本章将专注于如下两个任务:获取属性和为属性打分。这些任务在概率知识库Probase[166,153]上完成。该知识库包含了大量的概念、实体和isA关系。本章的方法有如下贡献:
该方法创新性地为属性获取典型度得分。本章将论证带有典型度得分的概念和属性对很多实际应用意义重大。在这项工作中,典型度得分被诠释为两个方面:频率(frequency)和家族相似度(family resemblance),它们将被表示为概率得分。
该方法在获取属性的时候能够处理歧义。消歧是一项很大的挑战,且在过往的属性提取方法中很少被强调。例如,当机器试图获取wine的属性时,它会错误地将短文“the mayor of Bordeaux”中的“mayor”标注为wine的属性。事实上,Bordeaux一词包含歧义,它不仅是酒的名字,还指法国西南的一个小城市。本章的工作针对基于实体的属性提取中的歧义,改进基于概念的属性提取方法,使其不受歧义的影响。
该方法从多个来源获取数据,并使用一种新的排序方法合并这些不同来源的数据。每个数据源和方法都有其独特特征。例如,name这个属性可能会被基于概念的属性提取方法识别,但不能通过基于实体的方法获取。biography这个属性则恰恰相反。因而,通过使用不同的方法和数据源有助于得到更加全面的属性信息,并帮助解决歧义、噪声、偏见和覆盖率的局限性。本章将对通过不同数据源提取到的属性进行比较,并提出一种新的排序算法来合并这些属性提取的结果。在这一问题上,现有的方法使用了回归[47]来聚合结果,但需要人为评估确定某些数值。而新提出的排序算法没有这一需求。
本章结构如下:22节介绍为百万级概念获取属性的方法;23节阐述为属性标记权重、聚合权重的方法;本章相关工作的讨论和结论将分别在24节和25节给出。