本节书摘来自华章社区《Hadoop大数据分析与挖掘实战》一书中的第2章,第2.3节Hadoop原理,作者张良均 樊哲 赵云龙 李成华 ,更多章节内容可以访问云栖社区“华章社区”公众号查看
2.3 Hadoop原理
2.3.1 Hadoop HDFS原理
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点,同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的,HDFS是Apache Hadoop Core项目的一部分。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现以流的形式访问(streaming access)文件系统中的数据。
HDFS采用master/slave架构。一个HDFS集群是由一个NameNode和一定数目的DataNodes组成。NameNode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的DataNode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组DataNode上。NameNode执行文件系统的名字空间操作,例如打开、关闭、重命名文件或目录。它也负责确定数据块到具体DataNode节点的映射。DataNode负责处理文件系统客户端的读写请求。在NameNode的统一调度下进行数据块的创建、删除和复制。图2-5所示为HDFS的架构图。
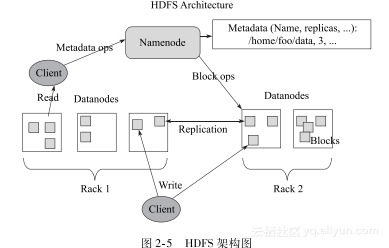
HDFS架构图HDFS数据上传原理可以参考图2-5对照理解,数据上传过程如下所示:
1)Client端发送一个添加文件到HDFS的请求给NameNode;
2)NameNode告诉Client端如何来分发数据块以及分发的位置;
3)Client端把数据分为块(block),然后把这些块分发到DataNode中;
4)DataNode在NameNode的指导下复制这些块,保持冗余。
2.3.2 Hadoop MapReduce原理
Hadoop MapReduce是一个快速、高效、简单用于编写并行处理大数据程序并应用在大集群上的编程框架。其前身是Google公司的MapReduce。MapReduce是Google公司的核心计算模型,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。适合用MapReduce来处理的数据集(或任务),需要满足一个基本要求:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。概念“Map”(映射)和“Reduce”(归约),以及它们的主要思想,都是从函数式编程语言里借来的,同时包含了从矢量编程语言里借来的特性。Hadoop MapReduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
一个MapReduce作业(job)通常会把输入的数据集切分为若干独立的数据块,由map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序,然后把结果输入给reduce任务。通常,作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,MapReduce框架的计算节点和存储节点是运行在一组相同的节点上的,也就是说,运行MapReduce框架和运行HDFS文件系统的节点通常是在一起的。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
MapReduce框架包括一个主节点(ResourceManager)、多个子节点(运行NodeManager)和MRAppMaster(每个任务一个)共同组成。应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数,再加上其他作业的参数,就构成了作业配置(job configuration)。Hadoop的job client提交作业(jar包/可执行程序等)和配置信息给ResourceManager,后者负责分发这些软件和配置信息给slave、调度任务且监控它们的执行,同时提供状态和诊断信息给job-client。
虽然Hadoop框架是用Java实现的,但MapReduce应用程序则不一定要用Java来写,也可以使用Ruby、Python、C++等来编写。
MapReduce框架的流程如图2-6所示。
针对上面的流程可以分为两个阶段来描述。
(1)Map阶段
1)InputFormat根据输入文件产生键值对,并传送到Mapper类的map函数中;
2)map输出键值对到一个没有排序的缓冲内存中;
3)当缓冲内存达到给定值或者map任务完成,在缓冲内存中的键值对就会被排序,然后输出到磁盘中的溢出文件;
4)如果有多个溢出文件,那么就会整合这些文件到一个文件中,且是排序的;
5)这些排序过的、在溢出文件中的键值对会等待Reducer的获取。
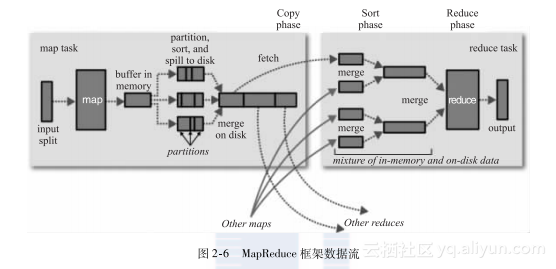
(2)Reduce阶段
1)Reducer获取Mapper的记录,然后产生另外的键值对,最后输出到HDFS中;
2)shuffle:相同的key被传送到同一个的Reducer中;
3)当有一个Mapper完成后,Reducer就开始获取相关数据,所有的溢出文件会被排序到一个内存缓冲区中;
4)当内存缓冲区满了后,就会产生溢出文件到本地磁盘;
5)当Reducer所有相关的数据都传输完成后,所有溢出文件就会被整合和排序;
6)Reducer中的reduce方法针对每个key调用一次;
7)Reducer的输出到HDFS。
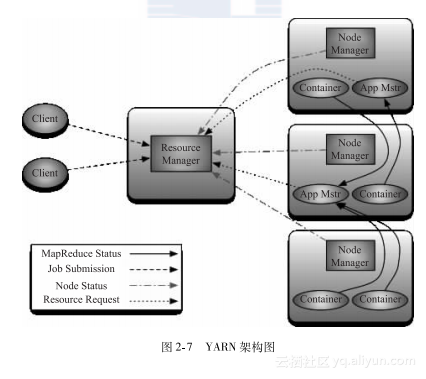
2.3.3 Hadoop YARN原理
经典MapReduce的最严重的限制主要关系到可伸缩性、资源利用和对与MapReduce不同的工作负载的支持。在MapReduce框架中,作业执行受两种类型的进程控制:一个称为JobTracker的主要进程,它协调在集群上运行的所有作业,分配要在TaskTracker上运行的map和reduce任务。另一个就是许多称为TaskTracker的下级进程,它们运行分配的任务并定期向JobTracker报告进度。
这时,经过工程师们的努力,诞生了一种全新的Hadoop架构——YARN(也称为MRv2)。YARN称为下一代Hadoop计算平台,主要包括ResourceManager、ApplicationMaster、NodeManager,其中ResourceManager用来代替集群管理器,ApplicationMaster代替一个专用且短暂的JobTracker,NodeManager代替TaskTracker。
MRv2最核心的思想就是将JobTracker两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度/监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的ApplicationMaster负责相应的调度和协调。一个应用程序要么是一个单独的传统的MapReduce任务或者是一个DAG(有向无环图)任务。ResourceManager和每一台机器的节点管理服务(NodeManger)能够管理用户在那台机器上的进程并能对计算进行组织。事实上,每一个应用的ApplicationMaster是一个特定的框架库,它和ResourceManager来协调资源,和NodeManager协同工作以运行和监控任务。
ResourceManager有两个重要的组件:Scheduler和ApplicationsManager。Scheduler负责分配资源给每个正在运行的应用,同时需要注意Scheduler是一个单一的分配资源的组件,不负责监控或者跟踪任务状态的任务,而且它不保证重启失败的任务。ApplicationsManager注意负责接受任务的提交和执行应用的第一个容器ApplicationMaster协调,同时提供当任务失败时重启的服务。如图2-7所示,客户端提交任务到ResourceManager的ApplicationsManager,然后Scheduler在获得了集群各个节点的资源后,为每个应用启动一个App Mastr(ApplicationMaster),用于执行任务。每个App Mastr启动一个或多个Container用于实际执行任务。