本节书摘来自华章社区《Spark核心技术与高级应用》一书中的第3章,第3.2节构建Spark的开发环境,作者于俊 向海 代其锋 马海平,更多章节内容可以访问云栖社区“华章社区”公众号查看
3.2 构建Spark的开发环境
无论Windows或Linux操作系统,构建Spark开发环境的思路一致,基于Eclipse或Idea,通过Java、Scala或Python语言进行开发。安装之前需要提前准备好JDK、Scala或Python环境,然后在Eclipse中下载安装Scala或Python插件。
3.2.1 准备环境
准备环境包括JDK、Scala和Python的安装。
1.安装JDK
(1)下载JDK(1.7以上版本)
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html。
(2)配置环境变量(以Windows为例)
新增JAVA_HOME变量,值:C:Program FilesJavajdk1.7.0_71。
新增CLASSPATH变量,值:.;%JAVA_HOME%lib。
增加PATH变量,补充;%JAVA_HOME%bin。
进入cmd界面测试JDK是否安装成功。
C:\Users\admin>java -version
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b14)2.安装Scala
下载Scala(2.10以上版本),下载地址:http://www.scala-lang.org/download/。
安装完毕配置环境变量,增加PATH变量,补充C:Program Files (x86)scalabin;。
进入cmd界面测试Scala是否安装成功。
C:\Users\admin>scala
Welcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_7
Type :help for more information.3.安装Python
下载Python,下载地址:https://www.python.org/downloads/。
安装完毕配置环境变量,增加PATH变量,补充C:Python33;。
进入cmd界面测试Python是否安装成功。
C:\Users\admin>python
Python 3.3.5 (v3.3.5:62cf4e77f785, Mar 9 2014, 10:37:12) [MSC v.1600 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.3.2.2 构建Spark的Eclipse开发环境
使用Eclipse进行Spark开发,需要安装Scala和Python插件,安装步骤如下:
1)安装Eclipse,在官网下载Eclipse,解压缩到本地后直接使用即可。
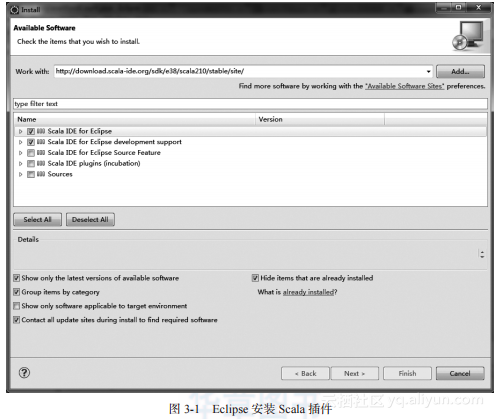
2)安装Scala插件,打开Eclipse,依次选择“Help”→“Install New Software…”,在选项里填入http://download.scala-ide.org/sdk/e38/scala210/stable/site/,并按回车键,如图3-1所示,选择Scala IDE for Eclipse和Scala IDE for Eclipse development support,完成Scala插件在Eclipse上的安装。
3)安装Python插件,与安装Scala插件一样,打开Eclipse,利用Eclipse Update Manager安装PyDev。在Eclipse菜单栏中找到Help栏,选择“Help”→“Install New Software”命令,在弹出的Install界面中点击“Add”按钮,会弹出“Add Repository”界面,在名称项输入PyDev;在链接里输入地址,如https://dl.bintray.com/fabioz/pydev/all/,然后点击“OK”按钮。接下来,Eclipse的Update Manager将会在刚才输入的站点中搜索安装包,选中搜索出的结果PyDev,并点击“Next”按钮,等待一段时间,PyDev会安装成功。
安装完毕PyDev之后,配置Python/Jython解释器,在Eclipse菜单栏中,选择“Window”→
“Preferences”→“Pydev”→“Interpreter - (Python/Jython)”命令。重启Eclipse使安装生效。
3.2.3 构建Spark的IntelliJ IDEA开发环境
除了使用Eclipse进行Spark程序开发之外,Spark支持的另外一种开发工具是IntelliJ IDEA;下载地址:http://www.jetbrains.com/idea/。
官方提供了Ultimate版和Community版可供选择,主要区别如下:
1)Ultimate版功能齐全的IDE,支持Web和Enterprise,免费试用30天,由官方提供一个专有的开发工具集和架构支持。
2)Community版支持Java、Groovy、Scala、Android的开发,免费并且开源,由社区进行支持。
作者使用的版本是ideaIC-14.1.4,请选择适合的操作系统进行安装。
如何安装IntelliJ IDEA?
Windows :直接运行.exe文件,按照向导步骤操作即可。
Mac OS X:打开.dmg包,并复制IntelliJ IDEA到应用文件夹。
Linux:解压.tar.gz压缩包,并运行bin/idea.sh(需要在环境变量PATH中加入IDEA目录,并执行source命令使配置文件生效)。
根据实际需求,我们选择Windows系统的Community版本进行Scala程序的开发。步骤包括:安装Scala插件和创建项目并在IDEA中编写Scala代码。
1.?安装Scala插件
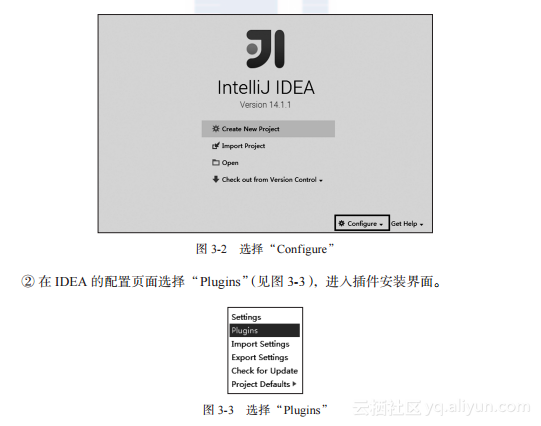
①?运行IDEA并安装和配置IDEA的Scala开发插件,启动程序界面如图3-2所示,此时需要选择“Conf?igure”,然后进入IDEA的配置页面。
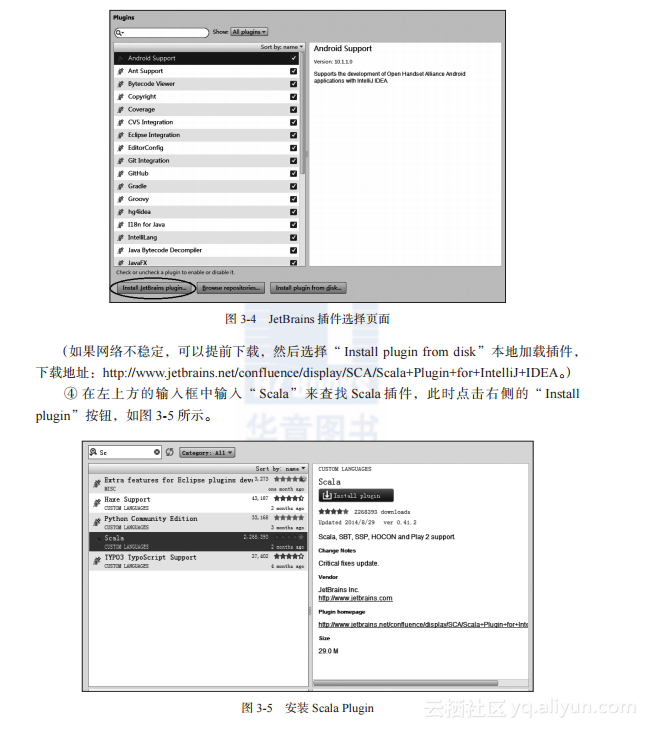
③?点击安装界面左下角的“Install JetBrains plugin”选项,进入JetBrains插件选择页面,如图3-4所示。
插件安装完毕,重启IDEA。
2.?创建项目并在IDEA中编写Scala代码
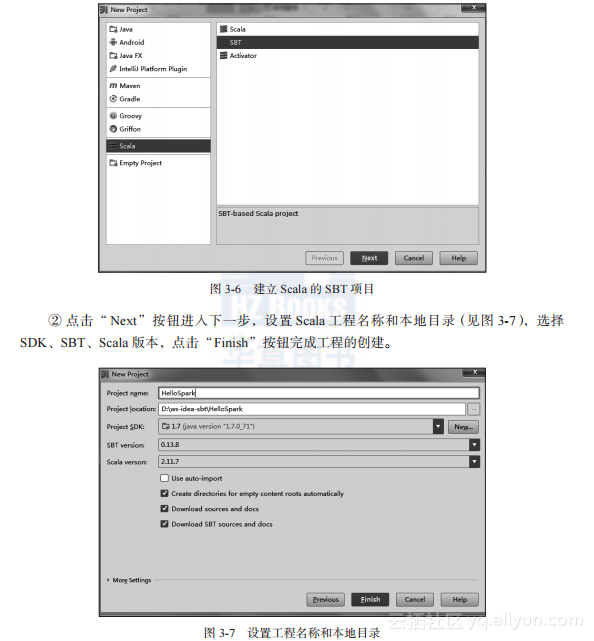
①?进入首页(见图3-2),选择“Create New Project”命令,此时选择左侧列表中的“Scala”选项,为了方便以后的开发工作,选择右侧的“SBT”选项,如图3-6所示。
③?由于在前面选择了“SBT”选项,所以此时IDEA智能地构建SBT工具:点击工程名称“HelloSpark”,可以看到SBT自动创建的一些目录,如图3-8所示。
④?此时右击src目录下main中的scala,在弹出的“New”菜单下选择“Scala Class”,在弹出的“Create New Scala Class”对话框中输入文件名“HelloSpark”,把Kind选择为“Object”,点击“OK”按钮完成,如图3-9所示。
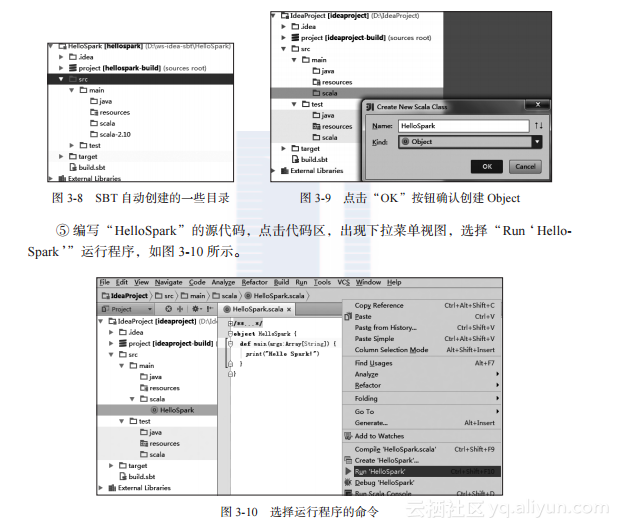
3.?加入Spark开发包
使用IDEA导入外部Jar包,具体步骤:“File”→“Project Structure”→“Modules”→“Dependencies”→+...→“Library...”→“Library Type(Java)”→“Select Library Files”→“Conf?igure Library”,以添加spark-assembly-1.5.0-hadoop2.3.0.jar为例,添加步骤如下:
①?点击“File”,选择“Project Structure”,如图3-11所示。
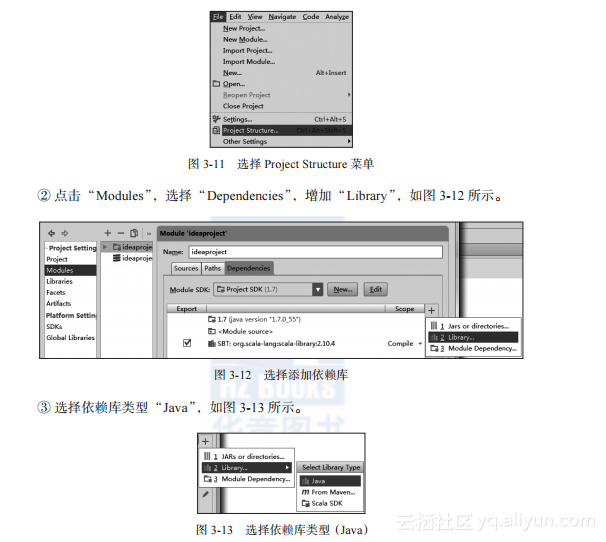
④?通过“Select Library Files”,选择“spark-assembly--.jar”,如图3-14所示。
选择完毕进行Spark开发包加载。
4.?JDK路径错误处理
如果SBT出现如图3-15提示,这是由于没有设置Java的JDK路径。
请点击最右侧的“Project Structure”,如图3-16所示,进入视图,并配置项目JDK。
选择最左侧的“Project”选项,并选择“No SDK”的“New”如图3-17所示,选择项目JDK为1.7。
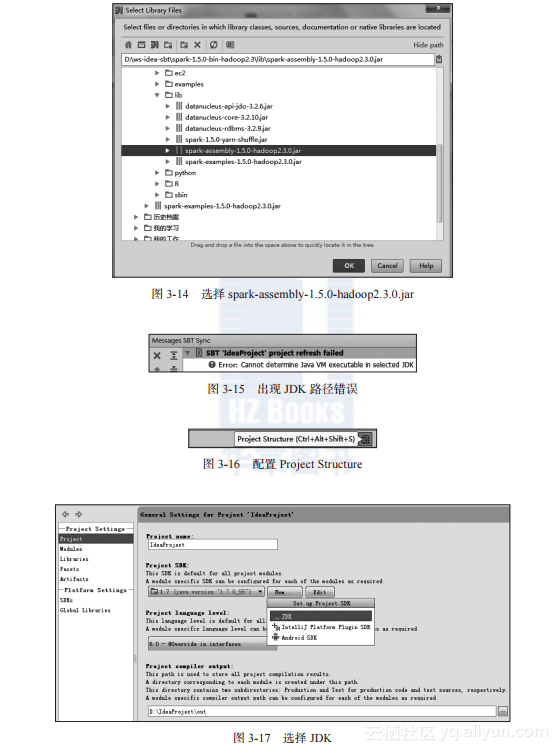
重启IDEA,问题解决。
5.?SBT下载不完整问题处理
如果不能出现完整的SBT目录,选择“View”目录的下拉菜单“Tool Windows”目录,选择“SBT”,如图3-18所示。
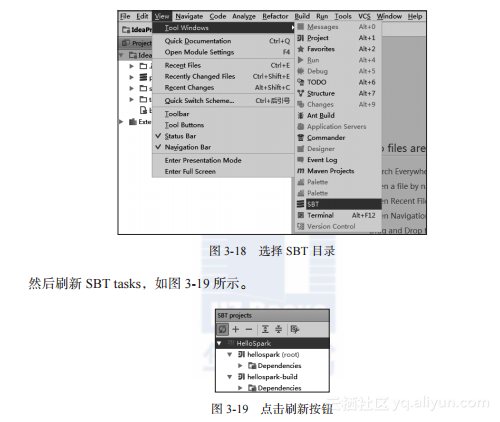
如果完整目录还是不可见,可以查看具体日志,然后将需要下载的sbt包下载下来,放到相应的目录,一般是当前用户的.ivy2目录,然后删除HelloSpark项目,重新建项目。
最终可以见到完整的SBT路径。
6.?IDEA生成Jar包
使用IDEA编译class文件,同时可以将class打包成Jar文件,方法如下:
①?选择菜单“File”→“Project Structure”,弹出“Project Structure”的设置对话框;
②?选择左边的“Artifacts”,点击上方的“+”按钮;
③?在弹出的对话框中选择“Jar”→“from moduls with dependencies”;
④?选择要启动的类,然后确定;
⑤?应用之后选择菜单“Build”→“Build Artifacts”,选择“Build”或者“Rebuild”后即可生成,生成的Jar文件位于工程项目目录的out/artifacts下。
