本节书摘来自华章计算机《深入理解ElasticSearch》一书中的第3章,第3.5节,作者:[美] 拉斐尔·酷奇(Rafa Ku) 马雷克·罗戈任斯基(Marek Rogoziński)更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.5 深入理解数据处理
刚开始使用ElasticSearch的时候,各种搜索方式和查询类型往往会令人感到头疼。查询类型之间行为各异,尽管有些差别非常细微,例如范围查询和前缀查询。了解这些差别对理解查询的工作原理至关重要,尤其是要在ElasticSearch提供的默认查询类型之外做些额外事情的时候,例如,处理多语言信息。
3.5.1 输入并不总是进行文本分析
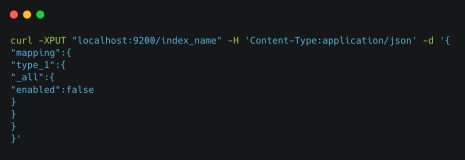
在讨论查询分析之前,我们先使用以下命令创建一个索引:

如你所见,这个索引非常简单。文档只包含一个字段,该字段使用snowball分析器进行处理。现在,我们通过执行下面这个命令来索引一个简单的文档:

此时索引中已经有文档了,我们不妨用一些查询来做一下测试,请仔细查看下面的两个命令:
第一个查询返回了目标文档,而第二个查询没有返回任何结果,两种情况对比悬殊!也许你已经知道(或猜测到)产生这种差异的原因,即该现象与文本分析有关。我们来比较一下,索引中存储了什么,又想搜索到什么。为实现该目的,可以通过执行下面的命令来使用文本分析(Analyze)API:

端点_analyze允许我们查看ElasticSearch是如何处理text参数中的输入的,同时也能指定要使用哪个分析器(通过analyzer参数)。
前面的命令经ElasticSearch处理后会返回类似下面的结果:
从中可以看到ElasticSearch是如何将输入转化为词条流的。请回顾1.1节,并注意这个事实:每个词条都携带了它在原始文本中的位置信息、类型信息(尽管用户对该信息不感兴趣,但是可能会被过滤器使用到)、词项信息(即一个词,它存储在索引中,在检索期用于与查询中的词项匹配)。为什么原始文本the quick brown fox jumps over the lazy dog被转化成了这些词项:quick、brown、fox、jump、over、lazi(这里发生了有趣的变化),dog,我们可以总结一下snowball分词器都做了哪些事情:
- 过滤非重要词(如the)。
- 将单词转换为词干形式(如jump)。
- 有时会进行糟糕的转换(如lazi)。
第三种情况看起来并没有那么糟,只要同一个词的不同形式得到了统一转化。如果这种事情发生了,词干还原的目的就达到了,即ElasticSearch会对查询和索引中的词项进行匹配,而不管它最初的单词形态如何。现在,回过头来看看我们的查询。该查询旨在搜索一个简单的词项(如这个例子中的jumps),然而索引中并没有该词项(索引中只有jump)。因此,query在搜索前应该先用分析器进行处理,此时会将jumps转换为jump,然后再进行搜索操作。
现在,请看第二个范例:

范例中的两个查询看起来很相似,但查询结果却大相径庭。第一个查询什么也没返回(因为查询中的lazy文本与索引中的lazi并不相同),而第二个查询经过分词器处理,返回了我们预期的文档。
3.5.2 范例的使用
所有这些范例都比较有趣,且能从中发现,有些查询经过了文本分析处理,而有些没有。对我们来说最重要的事情是,如何自觉利用这些知识改进具体的搜索应用。
假如要搜索本书的内容,可能某些用户会搜索书中的章节名、地名或某个片段。因为我们没有自然语言分析工具,所以不能理解用户输入的这些短语。然而,从概率的角度来看,与查询短语在文本上精确匹配的文档应该是用户最感兴趣的。而从另外一个重要指标来看,与用户输入短语中词语精确匹配的文档才是用户感兴趣的。这里的词语精确匹配既可以是语义上相同也可以是同一个词的不同形态。
为了演示,我们先用下面的命令创建一个只包含单字段文档的索引:
尽管只有一个字段,但却使用了两个分析器进行文本分析处理,这是因为title字段是multi_field类型的缘故,其中对title.org子字段使用了standard分析器,而对title.i18n子字段使用了english分析器(该分词器会将用户输入转换为词干形式)。
如果我们使用如下命令向索引中添加一个文档:

此时,索引中的title.org字段已有jumps词项,而title.i18n字段中也有了jump词项。然后我们执行下面的查询:

我们的文档由于跟查询完美匹配而获得了较高的得分,这归功于对field.org字段的命中做了加权处理。field.i18n字段的命中也贡献了部分得分,只是它对总得分的影响要小很多,因为我们并没有对该字段的命中做加权处理,它还是默认权值1。
3.5.3 索引期更换分词器
另外一件值得一提的事情是,在处理多语言数据的时候,可能要在索引期中动态更换分词器。比如说,我们修改前面的映射,添加_analyzer相关配置:

我们仅做了少许修改,首先是允许ElasticSearch在处理文本时根据文本内容决定采用何种分析器。其中,path参数为文档中的字段名,该字段中保存了分析器的名称。其次是移除了field.i18n字段所用分析器的定义。现在,我们可以用下面这条命令来创建索引:
上面的例子中,ElasticSearch从索引中提取lang字段的值,并将该值代表的分析器置于当前文档的文本分析器处理。总之,当你想对不同文档采用不同分析器时,该设置非常有用(例如,在文档中移除或保留非重要词)。
3.5.4 搜索时更换分析器
也可以在搜索时更换分词器,并通过配置analyzer属性来实现。例如,下面这个查询:
如代码所示,ElasticSearch会采用我们显式提到过的分析器。
3.5.5 陷阱与默认分析
索引期与检索期能针对文档更换分词器的机制是一个非常有用的特性,但它也会引入很多非常隐蔽的错误。其中之一就是没有定义分析器。针对这种情况,虽然ElasticSearch会选用一个所谓的默认分析器,但这往往并不是我们想要的。这是因为默认分析器有时候会被文本分析插件模块重定义。此时,有必要指定ElasticSearch的默认分析器。为了实现该目的,我们还是像平常那样定义分析器,只是将自定义分析器的名称替换为default。
作为一种备选方案,你可以定义default_index分析器和default_search分析器,并将它们作为索引期和检索期的默认分析器。