本节书摘来自华章出版社《算法基础:打开算法之门》一书中的第1章,第1.2节,作者 [美]托马斯 H 科尔曼(Thomas H Cormen),更多章节内容可以访问云栖社区“华章计算机”公众号查看
1.2 资源利用
什么样的算法才能称为高效使用计算资源的算法呢?我们在讨论近似算法时提及了一个衡量效率的标准:时间。一个能给出正确输出但是会花费很长时间才能得出结果的算法可能是没有价值的。如果你的GPS需要一个小时才能计算出推荐的驾驶路线,你还会愿意打开GPS吗?诚然,一旦我们知道某算法能给出一个正确输出,时间便是我们用来衡量算法效率的主要方式。但是时间不是唯一的衡量标准。由于一个计算机算法必须能够在可用的内存空间上运行,因此我们可能还需要考虑该算法需要占用多大的计算机内存空间(它的“内存占用量”)。算法可能需要占用的其他资源还包括:网络通信、随机比特(由于随机算法需要产生随机数的资源)和磁盘操作(针对需要处理存储在磁盘上的数据的算法)。
类似大多数算法书,本书中我们将着重研究一个资源——时间。我们如何判定算法所需的时间呢?与正确性不同,正确性与运行该算法的特定计算机无关,而算法的实际运行时间还与算法本身之外的几个因素有关:计算机的速度、实现算法的编程语言、将源程序转换成计算机能执行的目标代码的编译器或者解释器、程序员的程序编写技术,以及与正运行的程序并行执行的其他进程。现假定算法运行在一个数据均存储在内存中的计算机上。
为了衡量一个算法的速度,如果我们通过在特定计算机上编写一个具体的程序,并用一个给定的输入来测试算法所需要的时间,则我们不会了解对于不同大小的输入,甚至对同样大小的不同输入,算法的运行速度会有多快。如果我们还要比较针对同一问题的两个不同算法的相对运行速度,4则我们必须实现这两种算法,并在各种不同规模的输入下对它们进行对比测试。因此,我们应该如何来评估一个算法的速度呢?
上述问题的答案需要综合以下两点。首先,我们要确定算法的输入规模。例如在路径寻找的例子中,输入可能是路线图中的某种表示,输入的规模依赖于交叉点的数目和连接交叉点的道路数目。(由于我们将所有的距离均以数字表示,数字对于计算机输入占用同样大小的空间,因此道路的实际尺寸和实际长度对输入规模均没有影响。)举一个更简单的例子,搜索某一个特定项是否出现在一个给定列表中,此问题的输入规模是列表中项的数目。
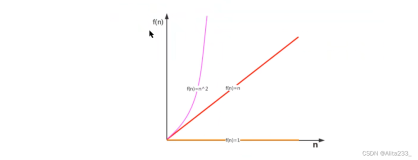
其次,我们考虑随着输入规模的增加,表示算法运行时间的函数会如何增长——运行时间的增长速率。在第2章中,我们将看到用来描述算法运行时间的符号,但最有趣的是,我们仅仅关注影响算法运行时间的主项,而不关心系数。也就是说,我们关注运行时间的增长量级。例如,假设我们能确定搜索一个具有n项的表的算法需要花费50n+125个机器周期。其中,当n≥3时,50n相对于125对算法有更大的影响。且随着n变得更大,50n相对于125对算法的影响就更加明显。因此,当我们描述这个算法的运行时间时,我们不用考虑低阶项125。可能令你更惊讶的还有我们舍弃了系数50,因此我们将运行时间表示为相对于输入规模n的线性函数。再举一例,如果一个算法需要20n3+100n2+300n+200个机器周期,我们将称该算法的运行时间随着n3数量级增长。同理,低阶项——100n2、300n和200——随着输入规模n的增加,变得越来越不显著。
实际上,我们忽视的系数的确会有影响。但算法本身如此依赖外在因素以至于完全可能出现这样的情况:如果我们要比较算法A和算法B的运行时间,且它们有相同的增长量级,并且具有相同的输入,那么在机器、编程语言、编译器/解释器和程序员的某一特定组合下,A的运行速度可能快于B,而在另一个组合下时,B的运行速度可能快于A。当然,如果算法A和B都能产生正确的输出,且A的运行速度始终是B的两倍,那么在相同的条件下,5我们总会更倾向于选择算法A而不是算法B。然而,从抽象角度比较算法时,我们只关注算法的增长顺序,而会忽视主项的系数或者低阶项。本章中我们要问的最后一个问题是:“为什么我要关注计算机算法?”该问题的答案取决于你是什么样的人。