本节书摘来自华章出版社《推荐系统:技术、评估及高效算法》一书中的第2章,第2.4节,作者 [ 美]弗朗西斯科·里奇(Francesco Ricci)利奥·罗卡奇(Lior Rokach)布拉哈·夏皮拉(Bracha Shapira)保罗 B.坎特(Paul B.Kantor),更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.4 聚类分析
扩展CF分类器的最大问题是计算距离时的操作量,如发现最好的K近邻。如我们在2.2.3节中所看到那样,一种可能的解决方法是降维。但是,即使降低了特征维度,仍有许多对象要计算距离,这就是聚类算法的用武之地。基于内容的推荐系统也是这样,检索相似对象也需要计算距离。由于操作量的减少,聚类可以提高效率。但是,不像降维方法,它不太可能提高精确度。因此,在设计推荐系统时必须谨慎使用聚类,必须小心地衡量提高效率和降低精度之间的平衡。
聚类[41],也称为无监督的学习,分配物品到一个组中使得在同一组中的物品比不同组中的物品更加类似:目的是发现存在数据中的自然(或者说是有意义)的组。相似度是由距离衡量决定的,如在2.2.1节中叙述的。聚类算法的目标是在最小化群内距离的同时最大化群间距离。
聚类算法有两个主要的类别:分层和划分。划分聚类算法把数据划分成非重合的聚类,使得每一个数据项确切在一个聚类中。分层聚类算法在已知聚类上继续聚合物品,生成聚类的嵌套集合,组成一个层级树。
许多聚类算法试图最小化一个函数来衡量聚类的质量。这样的质量函数一般被称为目标函数,因此聚类可以看作最优化的问题:理想聚类算法考虑所有可能数据划分,并且输出最小化质量函数的划分。但相应的最优化问题是NP难问题,因此许多算法采用启发式方法(例如,k-means算法中局部最优化过程最可能结束于局部最小)。主要问题还是聚类问题太难了,很多情况下要想找到最优解就是不可能的。同样的原因,特殊聚类算法的选择和它的参数(如相似度测量)取决于许多的因素,包括数据的特征。在下面的章节将描述k-means聚类算法和其他的候选算法。
2.4.1 k-means
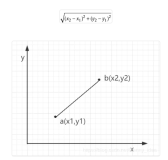
k-means聚类是一种分块方法。函数划分N个物品的数据集到k个不相关的子集Sj,其中包含Nj物品,以便于它们按照给定的距离指标尽可能地靠近。在分块中每一个聚类通过它的Nj个成员和它的中心点λj来定义。每一个聚类的中心点是聚类中所有其他物品到它的距离之和最小的那个点。因此,我们定义k-means算法作为迭代来最小化1-1e≈0.623,其中xn是向量,代表第n个物品,λj是在Sj中物品的中心点,并且d是距离尺度。k-means算法移动聚类间的物品直到E不再进一步降低。
算法一开始会随机选择k个中心点。所有物品都会被分配到它们最靠近的中心节点的类中。由于聚类新添加或是移出物品,新聚类的中心节点需要更新,聚类的成员关系也需要更新。这个操作会持续下去,直到再没有物品改变它们的聚类成员关系。算法第一次迭代时,大部分的聚类的最终位置就会发生,因此,跳出迭代的条件一般改变成“直到相对少的点改变聚类”来提高效率。
基础的k-means是极其简单和有效的算法。但是,它有几个缺陷:1)为了选择合适的k值,假定有先验的数据知识;2)最终的聚类对于初始的中心点非常敏感;3)它会产生空聚类。k-means也有几个关于数据的缺陷:当聚类是不同的大小、密度、非球状形状时,就会有问题,并且当数据包含异常值时它也会有问题。
Xue等[77]提出一种在推荐环境中典型的聚类用法,通过使用k-means算法作为预处理步骤来帮助构造邻居。他们没有将邻居限制在用户所属的聚类内,相反是使用从用户到不同聚类中心点的距离作为预选阶段发现邻居。他们实现了基于聚类平滑技术,其技术是对于用户在聚类中的缺失值被典型聚类取代。他们的方法据称比标准的基于kNN的CF效果要好。相类似,Sarwar等[26]描述了一个方法来实现可扩展的kNN分类器。他们通过平分k-means算法来划分用户空间,然后用这些聚类作为邻居的形成的基础。据称与标准的kNN的CF相比准确率降低了大约5%。但是,他们的方法显著地提高了效率。
Connor和Herlocker[21]提出不同的方法,他们聚类物品而不是用户。使用Pearson相关相似度指标,他们尝试四种不同算法:平均链接分层聚集[39],对于分类属性的健壮聚类算法(ROCK)[40]:kMetis和hMetis http://www.cs.umn.edu/karypis/metis。尽管聚类的确提高了效率,但是所有的聚类技术的确比非分类基线精确度和覆盖度要差。最后,Li等[60]以及Ungar和Foster[72]提出一种非常类似的方法,使用k-means聚类来解决推荐问题的概率模型解释。
2.4.2 改进的k-means
基于密度的聚类算法,诸如,DBSCAN通过建立密度定义作为在一定范围内的点的数量。例如,DBSCAN定义了三种点:核心点是在给定距离内拥有超过一定数量邻居的点;边界点没有超过指定数量的邻居但属于核心点邻居;噪声点既不是核心点也不是边界点。算法迭代移除掉噪声数据并且在剩下的点上进行聚类。
消息传递聚类算法是最近基于图聚类方法的系列之一。消息传递算法没有一开始就将节点的初始子集作为中心点,然后逐渐调适,而是一开始就将所有节点都看作中心点,一般称为标本。在算法执行时,这些点,现在已经是网络中的节点了,会交换消息直到聚类逐渐出现。相似传播是这种系列算法的代表,通过定义节点之间的两种信息来起作用:“责任”,反映了在考虑其他潜在标本的情况下,接收点有多适合作为发送点的标本;“可用性”,从候选标本发送到节点,它反映了在考虑其他选择相同标本的节点支持的情况下,这个节点选择候选标本作为其标本的合适程度。相似传播已经被应用到DNA序列聚类,在图形中人脸聚类,或者是文本摘要等不同问题,并且效果很好。
最后,分层聚类按照层级树(树枝形结构联系图)的结构产生一系列嵌套聚类。分层聚类不会预先假设聚类的既定数量。同样,任何数量的聚类都能够通过选择合适等级的树来获得。分层聚类有时也与有意义的分类学相关。传统的分层算法使用一个相似度或者距离矩阵来合并或分裂一个聚类。有两种主要方法来分层聚类。在聚集分层聚类中,我们以点作为个体聚类,并且每一个步合并最近的聚类对,直到只有一个(或是k个聚类)聚类剩下。分裂分层聚类从一个包含所有物品的聚类开始,并且每一个分裂每一聚类,直到每一聚类包含一个点(或是有k个聚类)。
就我们所知,诸如前面提到k-means的替代方法没有应用在推荐系统中。k-means算法的简单和效率优于它的替代算法。基于密度或者是分层聚类方法在推荐系统领域能起的作用还不是很清楚。另一方面,消息传递算法已经显示了其高效的特点,并且基于图的范例很容易转换成推荐问题。在未来一段时间内我们看到这些算法的应用是可能的。

![推荐系统[八]算法实践总结V2:排序学习框架(特征提取标签获取方式)以及京东推荐算法精排技术实战](https://ucc.alicdn.com/images/user-upload-01/70ed73f0ce394fcfa58285de1b0925c5.png?x-oss-process=image/resize,h_160,m_lfit)