Preface 前 言
Hadoop是个非常优秀的开源工具,可以将海量的非结构化数据转换为易于管理的内容,从而更好地洞察客户需求。它很便宜(几乎是免费的),只要数据中心有空间和电源,它就能够水平扩展,并且可以处理传统数据仓库难以解决的问题。需要注意的是,你得将数据填入Hadoop集群中,否则你所得到的只不过是昂贵的热量产生器而已。你很快就会发现,一旦对Hadoop的使用经过 “试验性”阶段后,你就需要工具来自动化地将数据填充到集群中。过去,你需要自己找到该问题的解决方案,但现在则不必如此!Flume一开始是Cloudera的项目,当时它们的集成工程师需要一次又一次地为客户编写工具来实现数据的自动化导入。时至今日,Flume已经成为Apache软件基金会的项目,并且处于活跃开发状态中,很多用户已经将其用于产品环境多年。
本书将会通过Flume的架构概览与快速起步指南帮助你迅速掌握Flume。接下来将会深入介绍Flume众多更加有用的组件的细节信息,包括用于即时数据记录持久化的重要的文件通道、用于缓存并将数据写到HDFS中的HDFS接收器,以及Hadoop分布式文件系统。由于Flume内置很多模块,因此上手Flume时你所需要的唯一工具就是一个用于编写配置文件的文本编辑器而已。
通过阅读上篇,你将掌握构建高可用、容错、流式数据管道(用于填充Hadoop集群)所需的一切知识。
虽然网上关于Hadoop的资料已经汗牛充栋,但大多数都止步于表面或是仅针对某个具体问题给出解决方案。下篇则对Hadoop以及MapReduce编程进行了简明介绍,旨在让你快速起步并对Hadoop编程有个总体印象,打好基础才能深入探索每一类MapReduce问题。
目 录 Contents
第1章 概览与架构
1.1 Flume 0.9
1.2 Flume 1.X(Flume-NG)
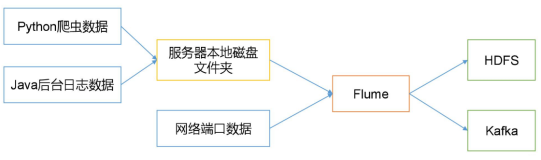
1.3 HDFS与流式数据/日志的问题
1.4 源、通道与接收器
1.5 Flume事件
1.6 小结
第2章 Flume快速起步
2.1 下载Flume
2.2 Flume配置文件概览
2.3 从“Hello World”开始
2.4 小结
第3章 通道
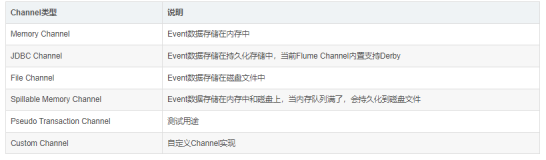
3.1 内存通道
3.2 文件通道
3.3 小结
第4章 接收器与接收处理器
4.1 HDFS接收器
4.1.1 路径与文件名
4.1.2 文件转储
4.2 压缩编解码器
4.3 事件序列化器
4.3.1 文本输出
4.3.2 带有头信息的文本
4.3.3 Apache Avro
4.3.4 文件类型
4.3.5 超时设置与线程池
4.4 接收器组
4.4.1 负载均衡
4.4.2 故障恢复
4.5 小结
第5章 源与通道选择器
5.1 使用tail的问题
5.2 exec源
5.3 假脱机目录源
5.4 syslog源
5.4.1 syslog UDP源
5.4.2 syslog TCP源
5.4.3 多端口syslog TCP源
5.5 通道选择器
5.5.1 复制
5.5.2 多路复用
5.6 小结
第6章 拦截器、ETL与路由
6.1 拦截器
6.1.1 Timestamp
6.1.2 Host
6.1.3 Static
6.1.4 正则表达式过滤
6.1.5 正则表达式抽取
6.1.6 自定义拦截器
6.2 数据流分层
6.2.1 Avro源/接收器
6.2.2 命令行Avro
6.2.3 Log4J追加器
6.2.4 负载均衡Log4J追加器
6.3 路由
6.4 小结
第7章 监控Flume
7.1 监控代理进程
7.1.1 Monit
7.1.2 Nagios
7.2 监控性能度量情况
7.2.1 Ganglia
7.2.2 内部HTTP服务器
7.2.3 自定义监控钩子
7.3 小结
第8章 万法皆空——实时分布式数据收集的现状
8.1 传输时间与日志事件
8.2 万恶的时区
8.3 容量规划
8.4 多数据中心的注意事项
8.5 合规性与数据失效
8.6 小结
下篇 MapReduce模式
第9章 使用Java编写一个单词统计应用(初级)
9.1 准备工作
9.2 操作步骤
9.3 示例说明
第10章 使用MapReduce编写一个单词统计应用并运行(初级)
10.1 准备工作
10.2 操作步骤
10.3 示例说明
10.4 补充说明
第11章 在分布式环境中安装Hadoop并运行单词统计应用(初级)
11.1 准备工作
11.2 操作步骤
11.3 示例说明
第12章 编写格式化器(中级)
12.1 准备工作
12.2 操作步骤
12.3 示例说明
12.4 补充说明
第13章 分析——使用MapReduce绘制频度分布(中级)
13.1 准备工作
13.2 操作步骤
13.3 示例说明
13.4 补充说明
第14章 关系操作——使用MapReduce连接两个数据集(高级)
14.1 准备工作
14.2 操作步骤
14.3 示例说明
14.4 补充说明
第15章 使用MapReduce实现集合操作(中级)
15.1 准备工作
15.2 操作步骤
15.3 示例说明
15.4 补充说明
第16章 使用MapReduce实现交叉相关(中级)
16.1 准备工作
16.2 操作步骤
16.3 示例说明
16.4 补充说明
第17章 使用MapReduce实现简单搜索(中级)
17.1 准备工作
17.2 操作步骤
17.3 示例说明
17.4 补充说明
第18章 使用MapReduce实现简单的图操作(高级)
18.1 准备工作
18.2 操作步骤
18.3 示例说明
18.4 补充说明
第19章 使用MapReduce实现Kmeans(高级)
19.1 准备工作
19.2 操作步骤
19.3 示例说明
19.4 补充说明