本节书摘来自华章出版社《Flume日志收集与MapReduce模式》一书中的第3章,第3.3节,作者 [美] 史蒂夫·霍夫曼(Steve Hoffman)斯里纳特·佩雷拉(Srinath Perera),更多章节内容可以访问云栖社区“华章计算机”公众号查看
3.3 小结
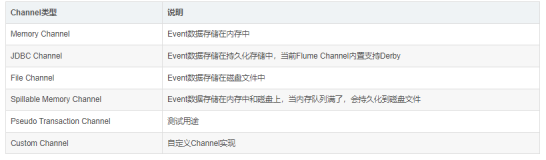
本章介绍了在数据处理管道中常用的两类通道。
内存通道提供了更快的速度,这是以故障事件出现时数据丢失为代价的。
此外,文件通道提供了更可靠的传输,因为它能容忍代理故障与重启,这是以牺牲性能为代价的。
你需要确定哪种通道更适合于你的使用场景。在确定内存通道是否适合时,请问问自己丢失一些数据的经济上的代价如何。在考虑是否使用持久化通道时请衡量它与添加更多的硬件以弥补性能上的差异时的代价相比如何。另一个考虑就是数据问题了。写入到Hadoop中的数据不一定都来自于流式应用日志。如果接收的是每天的数据下载,那么就可以使用内存通道了,因为一旦遇到了问题还可以重新导入。
下一章将会介绍接收器。特别是将事件写到HDFS中的HDFS接收器;此外,还会介绍事件序列化器,它指定了如何将Flume事件转换为更加适合于接收器处理的输出。最后,下一章将会介绍接收处理器以及如何在分层配置中创建负载均衡与故障路径,从而实现更为健壮的数据传输。