本节书摘来自华章出版社《Flume日志收集与MapReduce模式》一书中的第2章,第2.4节,作者 [美] 史蒂夫·霍夫曼(Steve Hoffman)斯里纳特·佩雷拉(Srinath Perera),更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.4 小结
本章介绍了如何下载Flume二进制分发包。我们创建了一个简单的配置文件,里面包含了一个源,它会将内容写到一个通道中,后者又会将其写到一个接收器中。源监听着一个Socket,等待网络客户端的连接,并向其发送事件数据。这些事件被写到一个内存通道中,然后被写到一个log4j接收器中,从而成为输出。接下来,我们使用Linux netcat工具连接到监听代理上,向Flume代理的源发送一些字符串事件。最后,我们验证基于log4j的接收器成功将事件写出。
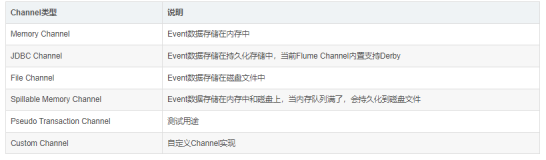
下一章将会详细介绍在数据处理工作流中会用到的两个主要通道类型:
- 内存通道
- 文件通道
对于每一种类型的通道,我们都会介绍所有相关的配置,何时以及为何要覆盖默认值,更为重要的是,我们会介绍在何种场景下该使用哪一种通道。