本节书摘来自异步社区《IS-IS网络设计解决方案》一书中的第6章,第6.1节,作者【美】Abe Martey,更多章节内容可以访问云栖社区“异步社区”公众号查看
第6章 最短路径优先算法
IS-IS网络设计解决方案
路由选择协议的本质是收集网络环境中的路由选择信息,并选择到所有已知目的的最优路径。如第2章中提到的,在IS-IS协议的体系结构中,这些功能是由两个进程实现的:更新进程与决策进程。更新进程主要负责建立IS-IS数据库并维护其稳定性;决策进程使用最短路径优先(Shortest Path First,SPF)算法基于链路状态数据库中的信息计算到所有已知目的的最优路径。SPF算法通过计算区域内一个特定的节点到其他所有节点的最短路径树从而得出从这个特定源到每个已知目的的最优路由。
SPF算法也称为Dijkstra算法,是由荷兰数学家Edsger Wybe Dijkstra命名的。E. W. Dijkstra于1930年出生于荷兰鹿特丹,在这里他学习了物理和数学,并最终成为了一名著名的计算机科学家。在研究一种在两点之间寻找最佳路径的算法的过程中,Dijkstra于1956年发明了SPF算法。Dijkstra最初称之为“最短次生成树(Shortest Subspanning Tree Algorithm)”算法,并将其用于解决早期计算机设计中将电流分配到所有必要电路中的问题,从而优化了昂贵的铜线的利用率。本章重点讨论IS-IS路由的计算过程以及SPF算法的操作机制。本章主要包括以下小节:
- SPF算法概述;
- 利用SPF算法计算IS-IS路由;
- Cisco路由器上的IS-IS SPF操作。
注:
最短路径优先(Open Shortest Path First,OSPF)协议是另一种使用SPF算法计算路由的路由选择协议。虽然在协议设计和体系结构上有本质的区别,但OSPF和IS-IS在很多方面仍是相似的。
6.1 SPF算法概述
IS-IS网络设计解决方案
SPF是路由选择协议用于确定最优路径的两种常用算法之一。另一种是Bellman-Ford算法,这种算法经常用于距离矢量路由选择协议。Bellman-Ford算法与SPF算法的基本区别在于Bellman-Ford算法的每一个节点基于直连邻居的开销加上邻居通告的路由的开销进行路径计算的。与之相对,SPF算法要求每个节点具有关于整个拓扑的完整信息。因此,一个区域内的所有节点会获得关于此区域的一致的链路状态数据库。链路状态数据库中包含区域内所有节点的链路状态信息(即来自区域内每个节点的链路状态数据包)。
与基于Bellman-Ford算法的路由选择协议相比,基于SPF算法不容易产生路由环路。由于Bellman-Ford算法依赖邻居发来的信息,而这些邻居可能已经在发生错误后不可用了,所以基于Bellman-Ford算法的路由选择协议更容易产生环路。因此,此类协议会使用复杂的抑制机制和例如水平分割、毒性逆转和跳数无限大等其他手段来防止环路。另外基于Bellman-Ford算法的协议的抑制机制会导致较长的收敛时间,这也是距离矢量路由选择协议典型的缺点。链路状态路由选择协议的收敛时间更快是因为每个节点基于收到的链路状态数据包(LSP)重新计算路由选择信息,当网络发生变化时,LSP会立即产生并泛洪出去。不过,基于SPF算法的协议对网络资源更为敏感,每台路由器需要更高的内存和CPU资源以保存链路状态数据库及运行SPF算法。
6.1.1 基本原理图
Dijkstra的算法提供了一个通用的解决方案,该方案适用于任何可以被模拟成有向图(Digraph)的问题。有向图是由一组通过直线或弧线(链路)相互连接的顶点(节点)构成的。图6-1显示了一个图例,数字表明的圆圈代表节点,其可以表示为{1,2,3,4,5}的集合。弧线是一条规划好的箭线。例如,顶点1和2之间的弧线是从顶点1指向顶点2的一个箭头,可以表示为(1,2)。顶点2和3之间的弧线是对向互指的,并表示为(2,3)和(3,2),与顶点2和3之间的链路方向一致。
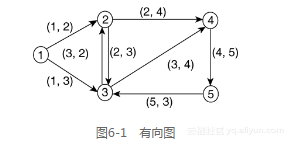
图6-1中弧线的集合可以被表示为{(1, 2), (1, 3), (2, 3), (2, 4), (3, 2), (3, 4), (4, 5), (5, 3)}。顶点的集合与弧线的集合可以被分配一个字母名称,如下:
N={1,2,3,4,5},代表顶点的集合。
L={(1, 2), (1, 3), (2, 3), (2, 4), (3, 2), (3, 4), (4, 5), (5, 3)} ,代表弧线的集合。
同时,该图可以被命名为G,表示为G=(N,L),其中N为顶点的集合,L为弧线的集合。
一条路径是图中任意两个顶点之间有向弧线的序列。例如,在图6-1中,顶点1到顶点4的路径可以被表示为 (1, 2), (2, 4) 或 (1, 3), (3, 2), (2, 4)。SPF算法的目标是确定从图中任一参考顶点到所有其他顶点的最短路径。SPF算法使用一种迭代机制来解决这一问题。
下一节将讨论在一个表示为G = (N, L)的有向图中SPF算法的操作,在一个固定的顶点s,顶点集N中:
- N—顶点的集合;
- L—弧线的集合;
- d(i,j) —顶点i到j的距离,如果顶点i与j非直连,则d(i, j) = 无限大;
- P —到参考顶点的最短路径已确定的顶点的集合;
- L(n) —当前的从顶点s到顶点n的最小开销。
SPF算法确定了从图中参考顶点s到每个顶点n的最短路径。一般情况下,这个过程主要包括三个步骤:
1.初始化;
2.下一个顶点选择;
3.最小开销路径更新。
6.1.2 SPF算法操作
SPF算法操作中的三个主要步骤如下。
步骤1.设置i=0,P0={v0=s},L(s)=0。如果n直连到s,L(n)=d(s,n)。如果n与s非直连,L(n)=无穷大。使用[L(n),s]标记每一个节点n。设置i=1。
步骤2.找到不在P集合中的下一个顶点vi,对于所有的vi来说,L(vi) = min L(n)。将vi移入P中,新的顶点为vi。
步骤3.更新P集合外的顶点的最短开销路径;L(n) = min{L(n),L(vi)+d(vi,n)}。如果L(n)被替代,更新n的标签为[L(n),NH(vi)],其中NH(vi)是从s到vi的下一跳。将i替换为 i+l,即(i = i+l)。如果i = N-i,停止;否则回到步骤2。
步骤1为初始化阶段。由于算法是迭代的,因此需要按阶段运行,每个阶段用i标明。在初始化阶段,i被设置为0。计算的执行与参考顶点s相关,参考顶点也称为源。在算法的操作过程中会用到以下三个相互独立的列表。
未知(Unknown,U):尚未计算的顶点集合。
实验(Tentative,T):正在进行计算的顶点集合。
路径(Paths,P):已经计算了最短路径的顶点集合。
在初始化阶段(i=0),参考顶点v0=s被选定并放入已知最近顶点集(P),即P0={v0=s}。图中其余顶点放入集合U。s到达自身的开销L(s)=0。从s到达直连顶点的开销设置为已知值,到达非直连顶点的开销被认为是未知的,设置为无穷大。
在步骤2中,算法计算从集合T中选定到达s的下一个最近的顶点,并标记其相关的开销和下一跳,然后将其移入集合P。在初始化阶段,只有与s直连的顶点会从集合U移入集合T。具有最低开销的顶点会被移入集合P。当一个顶点从集合T移入集合P后,所有与其直连且不在集合T中的顶点将被移入集合T中。
在最后一步中,与最新移入集合P的顶点相关的集合T中的每个节点的最小开销将被更新,下一跳也将改变为此节点。只有当新的开销值更低时才会替代现有的最小开销。
算法随后进行下一次迭代,回到步骤2并再次进行步骤3,直到所有的节点被移入集合P。对于包括作为计算中心的参考顶点在内的具有N个顶点的图例来说,从0开始需要进行N-1次迭代。在完成最后的第N-1次迭代后,会计算出从参考顶点到其他所有顶点的最短距离。
在一个有向图中确定任意两个顶点之间的最短路径与在数据通信网络中找到任意两个节点之间的最短路径是相似的。如前文提到的,路由选择协议的功能是依据一些优化的标准确定网络中两个节点之间的最短路径,这些标准通常为最小开销或最低度量。以此类推,通信网络中的路由器类似于有向图中的顶点,链路或邻接关系类似于弧线。由于网络节点之间的通信流是双向的,每条网络链路会被看作是一对平行的指向相反方向的弧线。网络中的链路会被分配一个称作开销或度量的权重值。大部分现实中的网络使用数字表示链路开销,与带宽成反比。因此,最快的链路会被分配最小的开销值。在网络中的节点间寻找最短路径的过程其实就是确定节点间最小开销值路径的过程。其他可能的度量选型包括跳数和复合度量。复合度量是基于带宽、延迟、可靠性、负载、最大传输单元(Maximum Transmission Unit,MTU)及其他链路特性综合计算得到的。
6.1.3 SPF算法运算开销
前文描述了SPF算法是如何工作的。这种工作机制表明,SPF算法的运算开销是与参与运算的节点和链路的数量相关的。在大型网络中,SPF算法是非常占用资源的,其需要的计算时间达到N2,其中N为节点数量。这一复杂的计算过程可以被直观地看作是:对于全部N个节点,确定从一个参考节点到图中所有其他节点的最低开销路径需要N-1次迭代,在每次迭代中,确定最小开销顶点所需的运算次数与N成比例。
如果在一个图中有N个节点和一共L条链路,那么一般情况下,SPF的计算时间与链路数量成比例:L的对数的L倍。这就是SPF计算的开销的阶数:O(LlogL)。
在一个互连程度不高的网络中,例如,所有的节点仅以最少的链路以直线的布局相连,此时L等于N-1。LlogL就可以被表示为Llog(N-1),等价于LlogN。总的来说,可以使用O(LlogN)来估算Dijkstra SPF算法的计算复杂度,其中L为网路中的全部链路的数量,N为节点数。计算复杂度与执行算法所需的处理时间是直接相关的。
与Dijkstra算法相关的另一个重要元素是对存储器或内存的需求。
6.1.4 内存需求
图中每台路由器存储了N个LSP,每一个LSP来自于区域中的一个节点。由于每个LSP中包含所连链路和邻接邻居的信息,假定K是所连的链路数,因此每个LSP的大小是与K成比例的。因此,每个节点需要的存储空间与NK成比例。即,每个节点的内存需求阶数是为O(NK)或O(L),其中L是全部链路的数量。在互连程度不高的环境中,L与节点数N的阶数相同,内存需求可以估算为O(N)。
对于节点数较多的网络,SPF算法过多的内存需求以及相应的长处理时间是在网络设计规划中引入层次结构的主要驱动因素。IS-IS提供了一个两层的层次结构从而允许建立多个大小合理的Level 1区域,并通过Level 1骨干区域将这些Level 1区域连接起来。
6.1.5 SPF计算示例
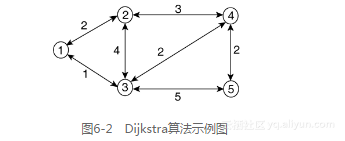
表6-1基于图6-2说明了Dijkstra算法的操作过程。在下面这个参考站点中还提供了一个用于说明Dijkstra算法操作步骤的演示动画:http://ciips.ee.uwa.edu.au/~morris/Year2/PLDS210/
dijkstra.html。
在图6-2中,用带有双向箭头的链路作为弧线,表示在两个邻接节点间双向的开销相同。这可能与实际的网络情况不符。特别是IS-IS协议并不要求链路的双向度量值相同。图6-2的拓扑中包含了5个节点和7条链路。算法在执行过程中以节点1作为参考节点。在真实的网络中,每一个节点会以自身为参考节点进行类似的运算。运算的最终目标是获得从源节点到拓扑中所有其他节点的最低开销(最优)路径。
算法在初始化时i=0,i列表示迭代次数。L(n)是在某次迭代中参考节点s到节点n的总开销。“下一跳”是到达某一特定节点的直连下一跳。表中其他缩写的释义如下所示。
- P:在路径集合或列表中的条目集合。
- value:S的直连下一跳。
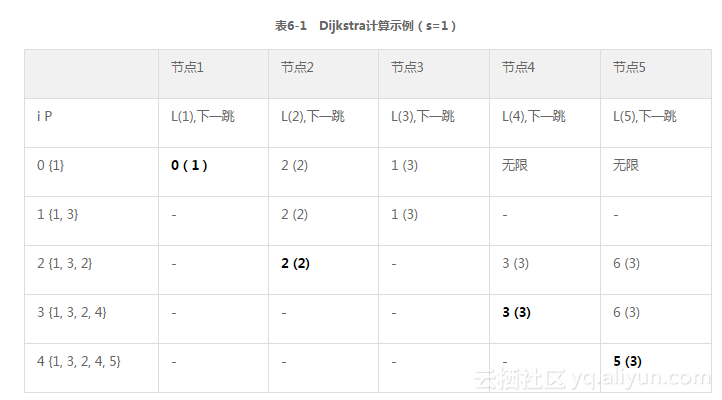
表6-1中加粗显示了每次迭代中从实验集(Tentative set,T)中选出的路径。在i=1次迭代中,只有节点2和3被放入了T中。每条路径都给出了到达目标的度量和下一跳。由于节点2和3是直连到节点1的,所以到达2和3的下一跳就是2和3本身。
没有直连到参考节点s的节点从其父节点处继承下一跳。例如,到达节点4的最优路径是通过节点3,开销值为3。到达节点5的最优路径是通过节点4,而节点4的父节点是节点3。因此,节点3是从节点1到节点5的下一跳。需要注意的是下一跳的计算表达了数据转发流程,即每个节点在沿着最优路径将数据包发往目标时只关注其下一跳。
表6-1的说明(SPF运算示例)
本小节将对表6-1中SPF算法的操作步骤进行了解释。步骤与迭代次序一致。
i=0 在第一次迭代中,节点1被选为源,相应地,L(1)=0和NH(下一跳)=1被填入到节点1下以表明从源到节点1的下一跳是其本身,且开销为0。没有关于其他节点的动作。
i=1 在迭代1的运算过程中,直连到节点1的节点2和3被放入T中。从节点1到节点2的下一跳是节点2,开销为2。从节点1到节点3的下一跳是节点3,开销为1。节点4和5仍留在未知集(Unknown set,U)中,开销为无穷大。由于节点3具有最低开销,因此从T中提升到P中。
i=2 在节点3从T提升到P之后,由于其直连邻居节点4和5并不在P中,因此将移入T中。需要注意节点2已经在T中了,开销为2。从源节点经过节点3到达节点2的开销为5,由于节点2直接到达源节点的开销为2,为最低开销,因此该条目将被保留。节点4和5使用节点3作为到达源的下一跳。从节点1到节点4的总的开销值为3,到节点5为6。由于具有最低开销,节点2从T提升到P中。
i=3 在节点2从T提升到P之后,其不在P中的直连邻居将被加以运算。此操作只会对节点5进行。节点5已经在T中。从节点1经过节点2到达节点4的总的开销为5,先前的路径由于开销更低将被保留。由于与节点5相比,节点4具有更低的关联开销,因此节点4将被提升到P中。
i=5 在节点4从T提升到P之后,其不在P中的直连邻居将被加以运算。此操作只会对节点5进行。节点5已经在T中。从节点1经过节点4到达节点5的总的开销低于先前路径的开销6。因此,节点4取代节点3作为节点5的父节点。同时,节点5继承了与节点4关联的下一跳节点3,开销值减为5。由于节点5是T中的唯一节点,因此将被提升到P中。
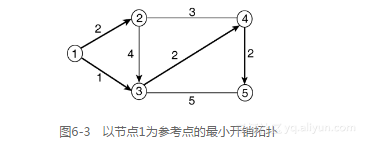
图6-3显示了在算法运算完成后产生的以节点1为参考节点的最小开销拓扑。节点2和3是直连到节点1的,但是到达节点4的最优路径为通过节点3,到达节点5的最优路径是首先通过节点3,随后通过节点4。