本节书摘来自异步社区《人脸识别原理及算法——动态人脸识别系统研究》一书中的第5章5.2节 主成分分析方法在人脸图像识别中的应用,作者 沈理 , 刘翼光 , 熊志勇,更多章节内容可以访问云栖社区“异步社区”公众号查看。
5.2 主成分分析方法在人脸图像识别中的应用
人脸识别原理及算法——动态人脸识别系统研究
关于方法的算法实现,可参阅文献[34]、[47]、[48]、[49]或者第2章的相关内容。这里主要从实验角度对PCA方法在实际应用中的问题进行探讨。实验中所用的人脸图像库如不特别说明均来自MIT的媒体实验室。因为该图像库是公用的,实验结果具有可比性,同时该图像库比较全面,具有光照、尺度、旋转等条件下的图像,但有一点不足是库中的图像实际上只取自16个人。
具体的成像条件为:在3种光源(头顶上方、45°、90°)、3种摄像镜头尺度下(全镜距、中镜距、小镜距)对16个人进行拍摄,并且在拍摄过程中拍摄对象进行3种旋转(正面、左旋22.5°、右旋22.5°),因此共有16×27=432幅人脸图像,图像大小取为120×128像素点。图5-1所示为头顶上方光源、全镜距、正面人脸图像;图5-2所示为某一拍摄对象在27种成像条件下的图像。
5.2.1 特征向量的表示能力
如采用图5-1所示的人脸图像作为训练样本,构造相关联矩阵并对其进行KL变换,可得到16个特征向量,也称作特征脸,如图5-3所示。
对比图5-1与图5-3,可以发现,图5-1中的每个人脸图像在图5-3中都可找到对应的特征脸,为了检测这些特征向量的表示能力,可任取一幅人脸图像I,通过这些特征向量进行人脸图像的重构。重构公式如下:
(5-1)
式中,mathop Inolimits^{rec}为重构的人脸图像;$\mathop \mu \nolimits_i $为特征向量;N为所用的特征向量个数;$\mathop \varpi \nolimits_i $为人脸图像向特征脸空间投影所得到的投影系数,可由下式求出:
(5-2)
重构误差可定义为:
(5-3)
为了度量重构的效果,这里定义重构信噪比(Signal to Noise Ratio,SNR)为
(5-4)
信噪比越高,表明信息的损失越少,重构效果越好。
重构结果如图5-4和图5-5所示。图5-4a为原图,取自训练样本,图5-4b所示为特征向量分别取1,2,…,16时的重构图,且重构图下面的数字为相应的重构信噪比。图5-5a为训练样本外的图像,图5-5b为特征向量分别取1,2,…,16时的重构图。

由图5-4b可以看出,对于训练样本内图像的重构效果很好。当特征向量个数取8个时,根据重构图即可分辨出原图,并且特征向量取得越多,重构信噪比越大,重构效果越好;当取全部16个特征向量时,重构效果最好。对于非训练样本内的图像的重构,由图5-5b可知,其重构效果很差,从重构图像中无法分辨出原图像,且重构信噪比较小,最大为SNR(16)=3.1682。
由此可知,由这些特征向量组成的特征脸空间不能很好地表示所有的人脸空间,只是对于训练样本所组成的人脸空间能够较好地表示,对于不在训练样本库中的人脸图像则不能有效地表示,这种现象称作训练样本效应。图5-6是所有16个训练样本内图像以及1个训练样本外图像的重构信噪比与特征向量个数之间的关系图,从图中可以更好地观察到这种效应。图中最下面那条近乎直线的线表示训练样本外图像5-5a的重构情况,而在其上的曲折线段分别表示训练样本内图像5-1的重构情况,随着特征向量个数的增加,重构信噪比增大,表明重构效果较好。
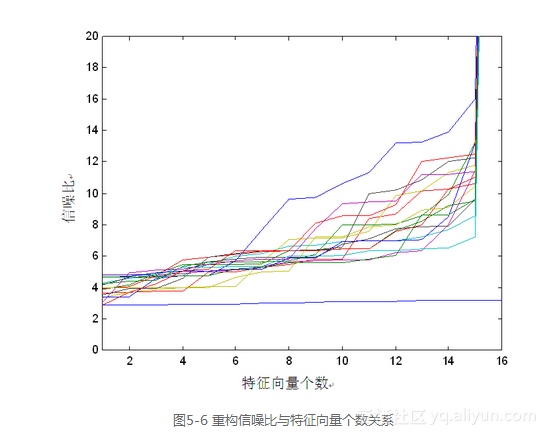
为了克服这种效应,一般使用多个训练样本进行训练。这里使用128幅人脸图像作为样本进行训练,这些样本来自ARPA/ARL的FERET人脸图像库。由这些图像得到的特征脸空间较好地反映了人脸图像空间,使得训练样本效应有所改善。对于训练样本外图像,图5-5a的重构如图5-7所示。

与图5-5相比,图5-7的重构效果要好一些。可以假定当训练样本个数增加时,利用PCA方法得到的特征向量空间将能更好地反映人脸图像空间,从而最终能够消除训练样本效应。
5.2.2 特征向量的选择
在文献[34]、[49]中,Turk等人认为,特征值越大则其对应的特征向量在表示人脸空间所起的作用越大,反之则越小,因此进行人脸图像的识别时,可以只取前面几个较大的特征值对应的特征向量,而忽略其余的特征值对应的特征向量。然而,O’Toole等人[104, 105]却不这样认为,他们在研究了特征向量与人脸特征之间的关系,如特征向量与种族、性别之间的关系后认为,较小的特征值对应的特征向量更有利于识别。
为了探讨特征向量的选择以及所选择的特征向量的个数对人脸图像识别的影响,本节在此进行了研究,做了两组实验。
实验5.1:取单个特征向量。
① 训练样本为16幅头顶上方光源、全镜距尺度、正面人脸图像,如图5-1所示;测试图像共有32幅为45°以及90°角光源方向、全镜距尺度、正面人脸图像。
② 实验过程为:在单独取不同特征向量的情况下,进行图像的识别。
该实验的目的是为了考察每个特征向量的识别能力。
实验5.2:取多个特征向量。
① 训练样本以及测试图像的选取同实验5.1。
② 实验中所取的特征向量的个数分别为从1直到16,实验目的是为了考察特征向量个数对识别的影响。
实验5.1及实验5.2的结果分别见表5-1及表5-2。
注: 表中,特征向量按其所对应的特征值进行排序,mu _1对应的特征值nu _1最大,mu _{16} 对应的特征值nu _{16} 最小
表5-2 实验5.2的结果
注: 这里特征向量个数为1表示只取mu _1 ,特征向量个数为2表示取mu _1 ,mu _2 ,依此类推
由表5-1可以看出,mu _1 得到的识别率最大,这一点与Turk等人的观点相符,但紧随其后的mu _2 、mu _3、mu _4等特征向量得到的识别率却不高;而较后的特征向量mu _{11} 、mu _{12} 、mu _{13} 、mu _{15} 等得到的识别率却较高,这一点与O’Toole等人的观点相符合。图5-8a、b分别是表5-1以及表5-2的更直观表示。
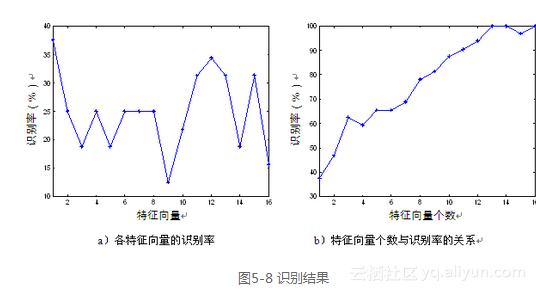
实验5.2的结果表明,特征向量个数取得越多,则识别准确率越高,这说明后面的特征向量对识别也是有贡献的。同时由图5-4b可以看出,特征向量个数少于8时,得到的重构图像只是一个模糊的人脸图像,具有人脸图像的共性,随着特征向量的增加,重构的图像更多的反映了人脸图像的具体特征,从而能够分辨出具体的人脸图像。
由此可以认为,对于人脸图像空间的表示,特征值越大其对应的特征向量所占的成分越多,特征值越小其对应的特征向量在表示中所起的作用越小,这与主成分分析的原理相符合。但对于人脸图像的识别而言,特征向量的选取似乎与特征值的大小没有关系,即O’Toole等人的观点更合理些。
从表5-1以及图5-8a可以发现,每个特征向量的识别能力是不同的,如果将识别能力较强的几个特征向量组合,进行识别,则识别率将会有所提高。这里给出组合特征向量集left{ {mu _1 ,mu _{11} ,mu _{12} ,mu _{13} ,mu _{15} } right}的识别率,为75%,对比表5-2可知这相当于其中特征向量个数为8时所达到的识别率。
5.2.3 光照的影响
为了研究光照对识别的影响,进行了以下实验。
实验5.3:光照相同。
① 训练所用的样本图像与待识图像相同,同为16幅头顶上方光源、全镜距尺度、正面人脸图像,如图5-1所示。
② 同实验5.2一样,实验中所选取的特征向量个数从1取到16,该实验目的是为了考察光照对识别的影响。实验结果见表5-3。
较理想的实验结果一方面验证了5.2.1节中所述的效应,即当待识目标取自训练样本库中时,识别效果较好;同时对比实验5.2的结果发现,在实验5.2中,识别率有所下降,由此可以知道光照对PCA方法有所影响,但影响不很大。
5.2.4 尺度的影响
对于同一个人的人脸,如果光照、背景、旋转等因素都不变,仅仅变换镜头的焦距,拍摄得到的人脸图像也是不一样的。对于识别系统而言,也必须考虑处理这种情况。以下章节,通过实验进一步阐述了这种情况,并提出一种方法,来确定图像的尺度。
1.不同尺度图像的识别情况
在进行人脸图像识别时,尺度是一个必须要考虑的因素。在对目标进行拍摄以得到人脸图像时,不能确保镜头焦距总是固定不变的,而且不同的人脸图像库之间的图像尺度也是不同的。为了考察PCA方法对不同尺度人脸图像的识别情况,共进行了4组实验,实验中所用的图像均来自MIT。
实验5.4:全镜距图像——中镜距图像,光源相同。
① 所用的训练样本为图5-1所示的全镜距、头顶上方光源、正面人脸图像,共有16幅;待识人脸图像为16幅中镜距、头顶上方光源、正面人脸图像,可参看图5-2中的211号图。
② 识别过程中选取不同数量的特征脸,以得到相应的识别率。实验结果如图5-9a中带星号的虚线所示。
实验5.5:中镜距图像——中镜距图像,光源相同。
① 所用的训练样本为16幅中镜距、头顶上方光源、正面人脸图像;待识人脸图像为16幅中镜距、头顶上方光源、正面人脸图像。
② 识别过程中选取不同数量的特征脸,以得到相应的识别率。实验结果如图5-9a中带圆圈的实线所示。
实验5.6:全镜距图像——中镜距图像,光源不同。
① 所用的训练样本为图5-1所示的全镜距、头顶上方光源、正面人脸图像,共有16幅;待识人脸图像为32幅中镜距、光源方向分别为90°以及45°、正面人脸图像,可参看图5-2中的221以及231号图。
② 识别过程中选取不同数量的特征脸,以得到相应的识别率。实验结果如图5-9b中带星号的虚线所示。
实验5.7:中镜距图像——中镜距图像,光源不同。
① 所用的训练样本为16幅中镜距、头顶上方光源、正面人脸图像;待识人脸图像为32幅中镜距、光源方向分别为90°以及45°、正面人脸图像。
② 识别过程中选取不同数量的特征脸,以得到相应的识别率。实验结果如图5-9(b)中带圆圈的实线所示。
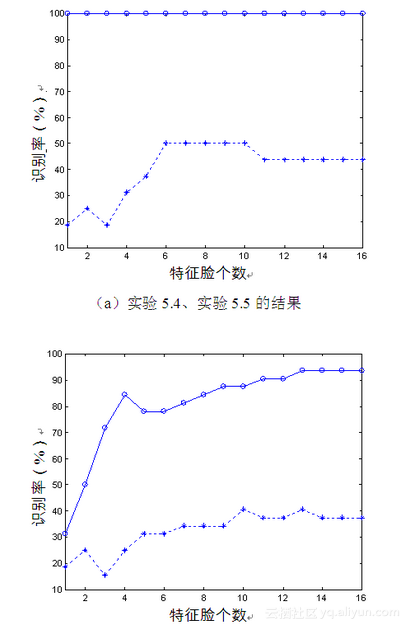
图5-9 尺度对PCA方法的影响
由图5-9可知,如训练样本图像与待识人脸图像的尺度不同则识别率很低,可从图5-9(a)、(b)中的虚线看出;而对于尺度相同的情况,则识别率较高,可从图5-9(a)、(b)中的实线看出。对于尺度相同、并且光照相同的情况,识别率更高,如图5-9(a)中的带圆圈实线所示;而对于尺度相同、光照不同的情况,识别率有所下降,从图5-9(b)中的带圆圈实线可看出,说明光照对识别有所影响,但不是很大,这与实验5.3所得出的结果相符。
2.不同尺度空间距离
造成上述现象的原因就是不同尺度的人脸图像代表不同的人脸空间,PCA方法提取的是这些空间的主要成分,由不同的人脸空间所得到的主成分也不同,因此根据一种空间的主成分去度量另一种空间的人脸,将会有很大差距。这种差距可根据以下式子进行计算:
d = left| {I - I_{face - space} } right|^2
(5-5)
式中,I为待识人脸图像,I_{face - space} 为I向人脸图像空间投影所得到的图像,具体计算可参考式(5-1);d为待识人脸图像与相应图像空间的距离。利用式(5-5)可计算不同尺度图像间的距离,为了进一步了解尺度对PCA方法的影响,进行了如下3组实验。
实验5.8:全镜距图像——全镜距、中镜距、小镜距图像。
① 所用的训练样本为图5-1所示的全镜距、头顶上方光源、正面人脸图像,共有16幅;然后分别取48幅全镜距、正面人脸图像,48幅中镜距、正面人脸图像以及48幅小镜距、正面人脸图像,光源方向均为头顶上方、90°方向、45°方向。
② 实验过程为利用式(5-5)计算这3种尺度的人脸图像与训练样本空间的距离。
③ 实验结果如图5-10(a)中所示,图中带星号的线表示48幅全镜距图像与样本图像空间的距离,带小圆圈的线表示48幅中镜距图像与样本图像空间的距离,带加号的线表示48幅小镜距图像与样本图像空间的距离。以下如不特别说明,都采用这种表示形式。
实验5.9:中镜距图像——全镜距、中镜距、小镜距图像。
① 所用的训练样本为16幅中镜距、头顶上方光源、正面人脸图像;所用的测试人脸图像同实验5.8。
② 实验过程同实验5.8。
③ 实验结果如图5-10(b)所示。各曲线的意义说明同实验5.8。
实验5.10:小镜距图像——全镜距、中镜距、小镜距图像。
① 所用的训练样本为16幅小镜距、头顶上方光源、正面人脸图像;所用的测试人脸图像同实验5.8。
② 实验过程同实验5.8。
③ 实验结果如图5-10(c)所示。各曲线的意义说明同实验5.8。
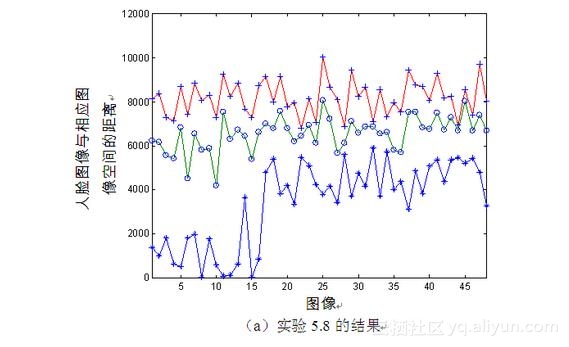
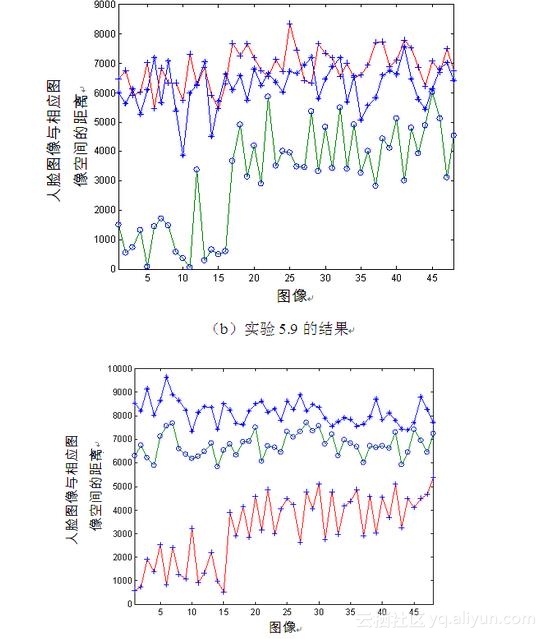
图5-10 不同尺度图像空间距离
由图5-10可见,对于与样本空间相同尺度的图像,由式(5-5)计算所得到的距离最小,这一点可从图5-10(a)中带星号的曲线、图5-10(b)中带圆圈的曲线以及图5-10(c)中带加号的曲线看出,它们都分别位于相应图的最下方,因为它们代表与相应样本图像尺度相同的图像。
同时从图中还可知道,图像尺度相差越大,其相互间的距离就越大。在图5-10(a)中,代表中镜距尺度图像的带圆圈曲线位于图的中间,而代表小镜距尺度图像的带加号曲线位于图的最上方,表示与全镜距尺度图像样本空间的距离最大。而在图5-10(b)中,因为全镜距尺度图像以及小镜距尺度图像相对于中镜距样本图像空间而言,距离相差大体一致,所以代表全镜距尺度图像的带星号曲线与代表小镜距尺度图像的带加号曲线在图的上方有些重叠。类似的结果也可从图5-10(c)中得到。
基于同样的原因,相同光源的图像间距离也较小,这一点可分别从图5-10中的最近距离曲线的前16幅图像与后32幅图像间的结果对比看出,因为前16幅表示头顶上方光源的图像,与样本图像相同,而后32幅不是。并且,可知光照对PCA方法的影响不如尺度的影响大,这也与5.2.3节的结论相符合。
3.图像尺度的确定
根据上节的阐述,不同尺度图像间的差距较大,可以使用PCA方法进行图像尺度的识别。为此首先给出尺度模板的定义。
定义5.1: 给定M幅尺度为S、头顶上方光源、正面人脸图像,利用PCA方法得到该图像集合的特征向量mu _s^1 ,mu _s^2 ,…, mu _s^M ,则由这些向量组成的空间Omega _s 称为尺度为S的模板。
同时还应该给出模板的阈值Theta _s ,当待测图像I与模板Omega _s 间的距离d小于Theta _s 时,则I的尺度为S;否则,I的尺度不为S。一般Theta _s 根据实验结果事先确定的。
若给出不同尺度的图像集合,则可以构造不同尺度图像的模板,如(Omega _{s1} ,Theta _{s1} ),(Omega _{s2} ,Theta _{s2} ),…,(Omega _{sn} ,Theta _{sn} )。任意给出一幅图像I,根据式(5-5)可得到I与不同尺度模板的距离d_1,d_2 ,…,d_n ,取距离最小值所对应的尺度模板(Omega _{si} ,Theta _{si} ),若d_i 小于Theta _{si} ,则将Omega _{si} 作为I的匹配空间,从而根据Omega _{si} 的尺度可以确定I的尺度,否则认为I的尺度不可知。
例如,在上一小节中,取16幅全镜距、头顶上方光源、正面人脸图像,可构造全镜距尺度模板Omega _f ;取16幅中镜距、头顶上方光源、正面人脸图像可构造中镜距尺度模板Omega _m ;取16幅小镜距、头顶上方光源、正面人脸图像,可构造小镜距尺度模板Omega _s 。则对于任给出的图像I,利用上述方法可确定其尺度,这一点由图5-10可明显看出。
5.2.5 旋转因素的影响
人脸图像的旋转可分为两种,一种为平面旋转,即人脸在同一平面内进行旋转,人脸的全局信息没有缺失;另一种为深度旋转,这种旋转使得人脸的全局信息会有所缺失,只能得到局部信息。图5-2中标号为112的图像是标号为111的人脸向右平面旋转得来的,而标号为113的图像是左平面旋转图像。图5-11是一个深度旋转的例子。
1.平面旋转图像的识别
在所得到的MIT的人脸图像库中只有平面旋转的图像,而没有深度旋转的情况,这里先考虑PCA对平面旋转的人脸图像的识别情况。为此进行了4组实验。
实验5.11:正面人脸——左平面旋转人脸,光源相同。
① 所用的训练样本为16幅全镜距、头顶上方光源、正面人脸图像;待识别图像为16幅全镜距、头顶上方光源、左平面旋转人脸图像。
② 识别过程中选取不同数量的特征脸,以得到相应的识别率。识别结果如图5-12a中带星号的虚线所示。
实验5.12:左平面旋转人脸——左平面旋转人脸,光源相同。
① 所用的训练样本与待识别图像相同,都为16幅全镜距、头顶上方光源、左平面旋转人脸图像。
② 识别过程同实验5.11,识别结果如图5-12a中带小圆圈的实线所示。
实验5.13:正面人脸——左平面旋转人脸,光源不同。
① 所用的训练样本为16幅全镜距、头顶上方光源、正面人脸图像;待识别图像为32幅全镜距、90°方向以及45°方向光源、左平面旋转人脸图像。
② 识别过程同实验5.11,识别结果如图5-12b中带星号的虚线所示。
实验5.14:左平面旋转人脸——左平面旋转人脸,光源不同。
① 所用的训练样本为16幅全镜距、头顶上方光源、左平面旋转人脸图像;待识别图像为32幅全镜距、90°方向以及45°方向光源、左平面旋转人脸图像。
② 识别过程同实验5.11,识别结果如图5-12b中带小圆圈的实线所示。
由图5-12可以看出,图像的平面旋转对识别影响很大。对比图5-9可知,旋转因素与尺度因素的影响是类似的,同样地可以认为平面旋转人脸图像空间与正面人脸图像空间是两个不同的空间,因此使用正面人脸图像空间的主成分去识别平面旋转人脸图像,识别准确度将降低,这从图5-12(a)、(b)中的虚线可以看出;而使用平面旋转人脸图像空间的主成分去识别旋转人脸图像效果很好,这从图5-12a、b中的实线可以看出。
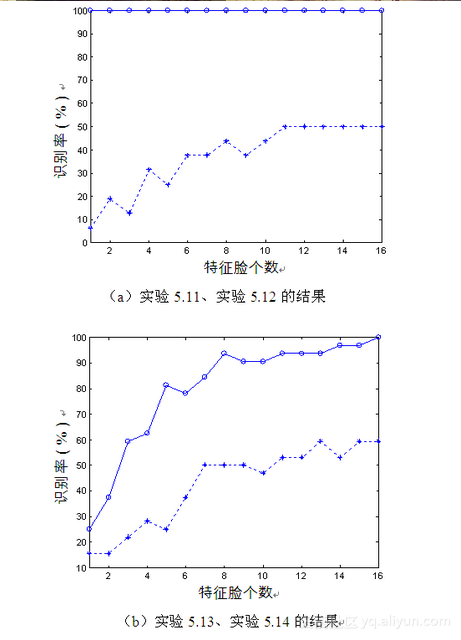
图5-12 左平面旋转对PCA方法的影响
类似左平面旋转所做的实验5.11~实验5.14,对于右平面旋转图像的识别情况,可相应地做4组实验进行研究,具体过程从略,只给出最终的实验结果,如图5-13所示,其中曲线的意义与图5-12相同。
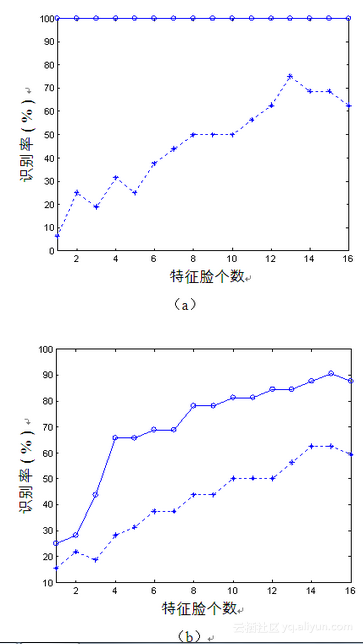
2.平面旋转图像空间距离
同样可以利用式(5-5)计算平面旋转人脸图像空间与正面人脸图像空间的距离。为此进行了如下3组实验。
实验5.15:正面图像——正面、左平面旋转、右平面旋转图像。
① 所用的训练样本为图5-1所示的全镜距、头顶上方光源、正面人脸图像,共有16幅;然后分别取48幅全镜距、正面人脸图像,48幅全镜距、左平面旋转人脸图像,以及48幅全镜距、右平面旋转人脸图像,光源方向均为头顶上方、90°方向、45°方向。
② 实验过程为利用式(5-5)计算这3种姿势的人脸图像与训练样本空间的距离。
③ 实验结果如图5-14(a)所示,图中带星号的线表示48幅正面图像与样本图像空间的距离,带小圆圈的线表示48幅左平面旋转图像与样本图像空间的距离,带加号的线表示48幅右平面旋转图像与样本图像空间的距离。以下如不特别说明,都采用这种表示形式。
实验5.16:左平面旋转图像——正面、左平面旋转、右平面旋转图像。
① 所用的训练样本为16幅全镜距、头顶上方光源、左平面旋转人脸图像;所用的测试图像同实验5.15。
② 实验过程同实验5.15,实验结果如图5-14(b)所示,各曲线的意义说明同实验5.15。
实验5.17:右平面旋转图像——正面、左平面旋转、右平面旋转图像。
① 所用的训练样本为16幅小镜距、头顶上方光源、正面人脸图像;所用的测试图像同实验5.15。
② 实验过程同实验5.15,实验结果如图5-14(c)所示,各曲线的意义说明同实验5.15。
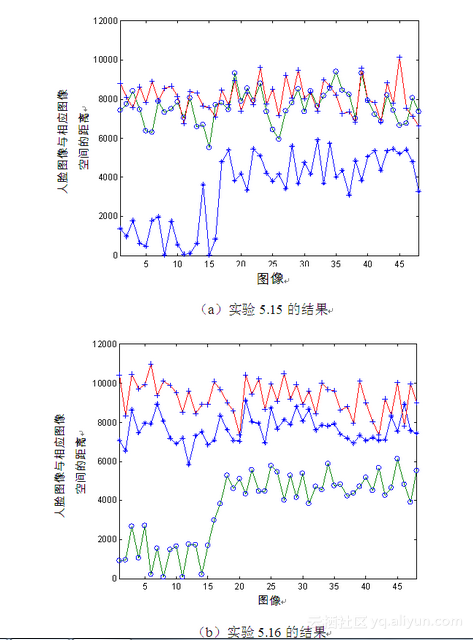
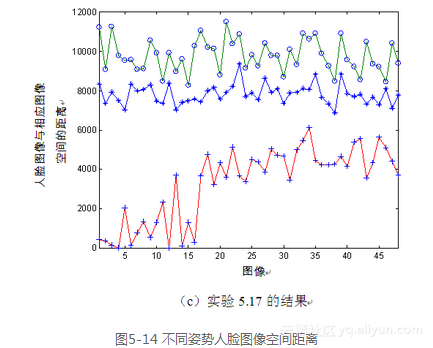
由图5-14可见,对于与样本空间相同姿势的人脸图像,由式(5-5)计算所得到的距离最小,这一点可从图5-14(a)中的带星号的曲线、图5-14(b)中带圆圈的曲线,以及图5-14(c)中带加号的曲线看出,它们都分别位于相应图的最下方,因为它们都代表与相应样本图像姿势相同的图像。
同时从图中还可知道,图像间姿势相差越大,其相互间的距离就越大;反之,则越小。在图5-14(a)中,代表左平面旋转姿势的带圆圈曲线与代表右平面旋转姿势的带加号曲线位于图的上方,并有重叠,这是因为这两种姿势的人脸图像相对于正面姿势的人脸空间而言,距离相差大体一致;而在图5-14(b)中,代表正面姿势的带星号曲线位于图的中间,而代表右平面旋转姿势的带加号曲线位于图的最上方,这是因为正面人脸图像与左平面旋转人脸空间的距离相对于右平面旋转人脸图像与左平面旋转人脸空间的距离要小些。类似的结果也可从图5-14c中得到。
3.图像平面旋转角度的确定
根据上节的阐述,不同姿势图像间的差距较大,可以使用PCA方法来确定图像的平面旋转角度。这里给出平面旋转模板的定义。
定义5.2: 给定M幅旋转角度为A、头顶上方光源、正面人脸图像,利用PCA方法得到该图像集合的特征向量mu _A^1 ,mu _A^2 ,…,mu _A^M ,则由这些向量组成的空间Omega _A 称为旋转角度为A的模板。同时还应该给出模板的阈值Theta _A ,当待测图像I与模板Omega _A 间的距离d小于Theta _A 时,则I的平面旋转角度为A;否则,I的旋转角度不为A。一般Theta _A 是根据实验结果事先确定的。
这里平面旋转包括向左旋转以及向右旋转。若给出不同旋转角度图像集合,则可以构造不同旋转角度图像的模板,如(Omega _{A1} ,Theta _{A1} ),(Omega _{A2} ,Theta _{A2} ),…,(Omega _{An} ,Theta _{An} )。类似于5.2.4节中关于图像尺度的确定算法,可以确定图像的平面旋转角度。
4.深度旋转图像的识别
为了研究PCA方法对深度旋转图像的识别情况,同样也进行了几组实验。实验中所用的图像来自UMIST的人脸图像库,库中图像为对20个目标拍摄而得的,拍摄过程中,目标进行不同角度的深度旋转,平均一个人有40多幅图像,包括各种角度。这里只考察3种旋转角度情况:正面、旋转45°及旋转90°,如图5-11所示。
实验5.18:正面图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅正面人脸图像,待识图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 识别过程为利用PCA方法识别各种待识图像,实验中利用了20个特征向量,实验结果见表5-4第二列。
实验5.19:旋转45°图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅旋转45°人脸图像,待识图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 识别过程同实验5.18,实验结果见表5-4第三列。
实验5.20:旋转90°图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅旋转90°人脸图像,待识图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 识别过程同实验5.18,实验结果见表5-4第四列。
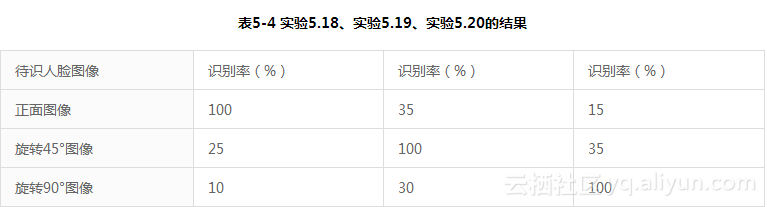
由表5-4可知,图像的深度旋转对PCA方法的识别有很大影响,相同旋转角度图像间的识别情况较好,而不同旋转角度图像间的识别情况较差。
5.深度旋转图像空间距离
同样可利用式(5.5)来计算不同旋转图像空间的距离。为此进行了如下3组实验。
实验5.21:正面图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅正面人脸图像,测试图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 实验过程为利用式(5-5)计算测试图像与训练样本的空间距离,实验结果如图5-15(a)所示,图中带小圆圈的曲线表示正面人脸图像与训练样本空间距离,带星号的曲线表示旋转45°人脸图像与训练样本空间距离,带加号的曲线表示旋转90°人脸图像与训练样本空间距离,以下图中曲线意义如不特别说明,都采用这种表示形式。
实验5.22:旋转45°图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅旋转45°人脸图像,测试图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 实验过程同实验5.21,实验结果如图5-15(b)所示,图中曲线意义同实验5.21。
实验5.23:旋转90°图像——正面、旋转45°、旋转90°图像。
① 训练样本为20幅旋转90°人脸图像,测试图像分别为20幅正面人脸图像、20幅旋转45°人脸图像以及20幅旋转90°人脸图像。
② 实验过程同实验5.21,实验结果如图5-15(c)所示,图中曲线意义同实验5.21。
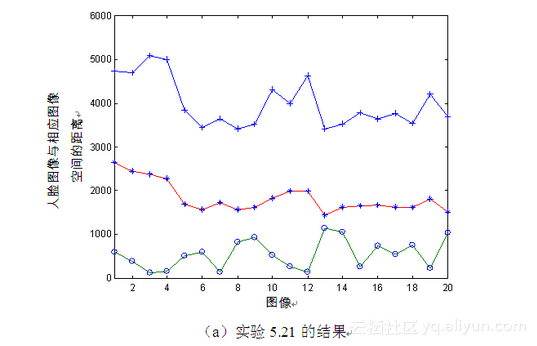
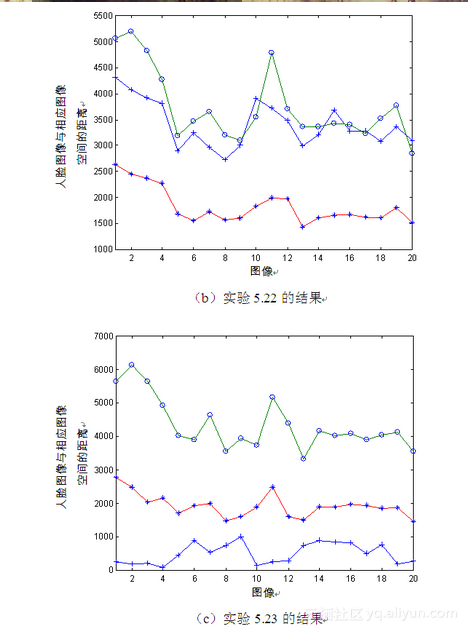
由图5-15可见,不同深度旋转角度的人脸图像空间差距明显,从而解释了上一小节的实验结果。
6.图像深度旋转角度的确定
图像深度旋转角度的确定方法类似于5.2.4节、5.2.5节所述方法,可以利用PCA方法给出不同深度旋转角度模板的定义,并由此求出待识图像的深度旋转角度,具体可参考上述两节,这里从略。
5.2.6 小结
由上述可知,光照、尺度、图像旋转等因素都会对PCA方法的正确识别产生干扰,若待识图像与库中存储的样本不是在同一条件下拍摄得到的,则使用该方法就不能很好地识别。为了得到通用的识别系统,一种解决方法是对于每个目标,在图像库中都有多个样本,如多种尺度模板、多种旋转模板等,另外,也有可能待识图像既有尺度变化同时还有旋转变化,则还需有多种尺度的旋转模板。具体识别时,将待识目标在各个模板空间中利用PCA方法进行识别,取最相似者作为匹配对象。显然,这样将使得存储开销空间很大。
另一种解决方法是不必要在库中为每个对象保留多个样本,而是构造一些公共的模板空间,如多尺度模板空间、多平面旋转角度空间、多深度旋转空间等。具体识别时,可以通过5.2.4节、5.2.5节、中所述的方法确定出图像的尺度、平面旋转角度以及深度旋转角度,然后对图像进行尺度标准化、旋转标准化处理,使得待识图像与库中样本图像具有同样的尺度、同样的姿势等,最后利用PCA方法进行识别。这种方法比上一种方法效果更好些,其关键在于图像的标准化处理,尤其是深度旋转图像的标准化处理。
总之,使用PCA方法能够很好地提取样本集合的主要成分,对于属于同一样本空间的图像能够很好地识别,而对于与样本不为同一空间的图像识别率较低。因此,可根据PCA方法的这一特点进行人脸特征的探测,如构造眼睛模板、鼻子模板、嘴部模板等,因为这些模板都代表不同的空间,故能够较精确地进行探测。以下将具体说明这种特征探测算法。
本文仅用于学习和交流目的,不代表异步社区观点。非商业转载请注明作译者、出处,并保留本文的原始链接。
